
【论文标题】An Explanation of In-context Learning as Implicit Bayesian Inference
【作者团队】Sang Michael Xie, Aditi Raghunathan, Percy Liang, Tengyu Ma
【发表时间】2022/03/24
【机 构】斯坦福
【论文链接】https://arxiv.org/abs/2111.02080v4
大型语言模型如GPT3具有令人惊讶的能力,可以进行语境学习,即模型仅仅通过对将输入实例组成的提示构建条件模型,就可以学会下游任务。本文研究了当预训练数据具有长距离一致性时,语境学习是如何出现的。语言模型必须推断出一个隐藏的文档级概念,以便在预训练期间产生连贯的token,当模型推断出一个提示中的例子之间的共享隐藏概念时,就会出现语境学习。本文也证明了在这种情况下,预训练分布是混合HMMs。与一般预训练使用的大规模数据集相比,本文产生了一个小规模的合成数据集GINC,其中Transformer和LSTM都表现出语境学习的能力。在GINC上的实验还表现出诸多现象,包括随着模型规模的扩大而提升的语境表现等。
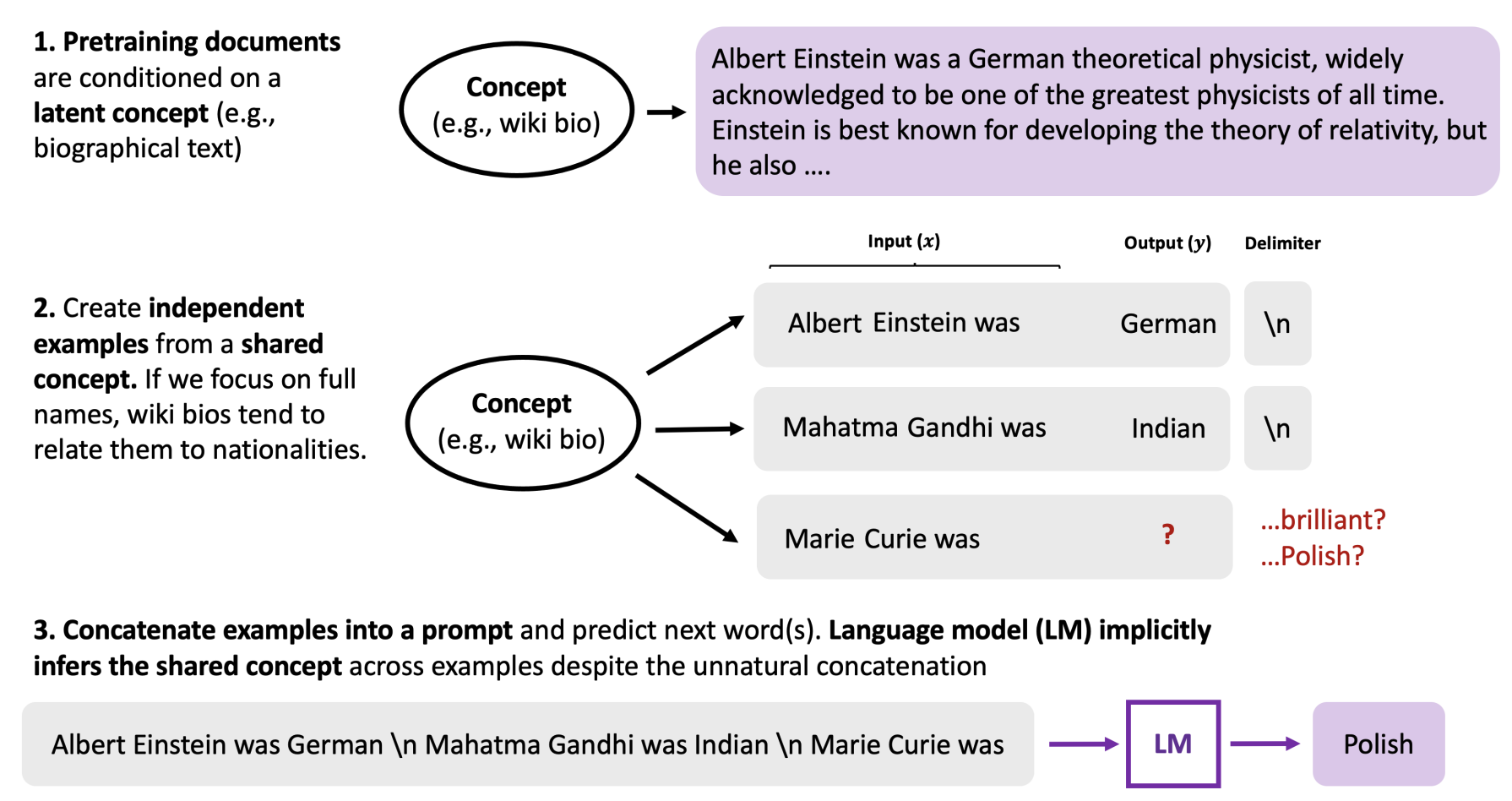
语境学习可以从预训练数据的长距离一致性中出现。在预训练过程中,语言模型隐含地学习推断出一个隐藏的概念。例如,维基生物,通常在名字(阿尔伯特-爱因斯坦)→国籍(德国)→职业(物理学家)→......。尽管提示是将独立的例子串联起来的非自然序列,但如果语言模型仍然能够推断出跨例子的共享概念来完成任务,比如姓名→国籍,这是维基生物的一部分,就会发生语境学习。
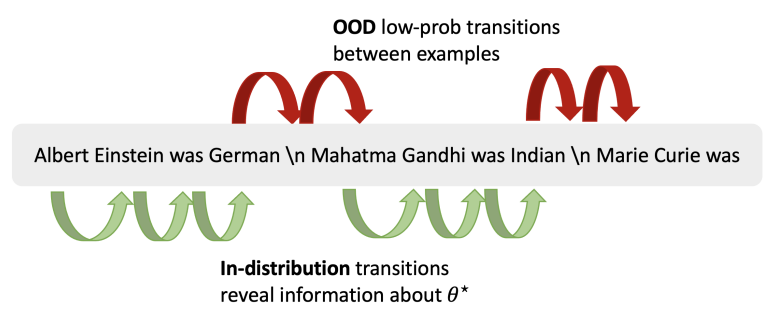
上图展示了语境学习的一个转换例子,当每个语境中的例子中关于提示概念的信号(绿色)大于例子之间的低概率转换的误差时,语境学习是成功的。语境中学习的信号来自输入和输入-输出映射中的token转换。
创新点
1.本文把语境学习看作是隐性贝叶斯推理,即预训练的语言在进行预测时隐性地推断出一个概念。
2.本文表明,当预训练分布是HMMs的混合物时,就会发生语境中学习。
3.本文的工作开启了理解语境中学习,希望这将为改进预训练和提示提供启示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢