
离线强化学习旨在从一批收集的数据中学习最佳策略,而在训练过程中无需与环境进行额外的交互。
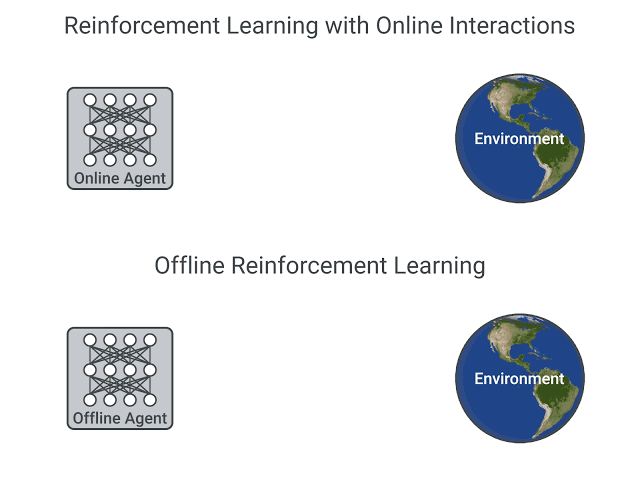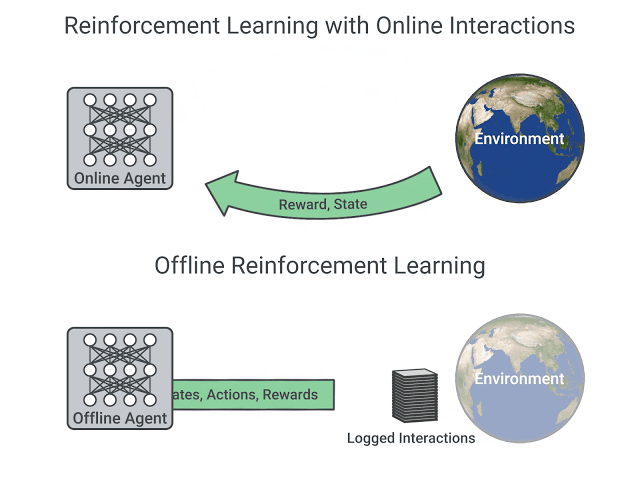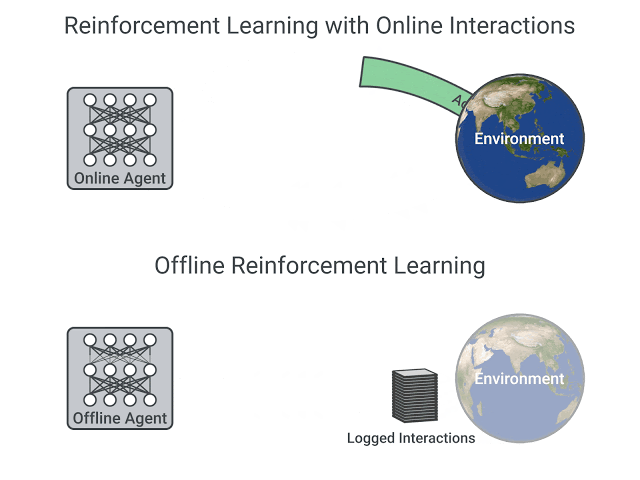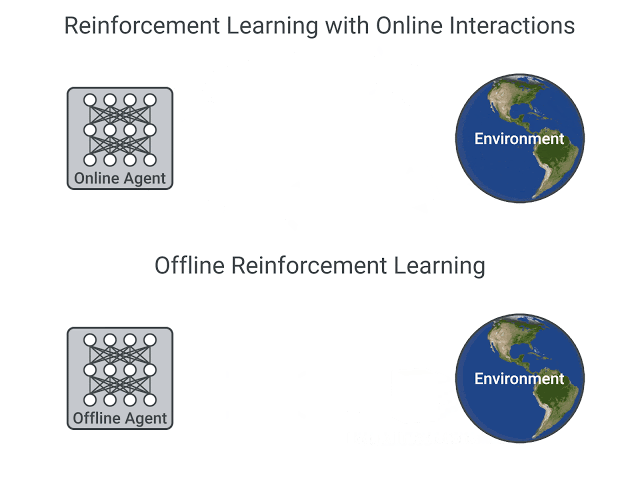
昨日Hugging Face将一种离线强化学习方法Decision Transformers引入其Hub及Transformers库中。Decision Transformers将强化学习抽象为条件序列建模问题,其主要想法是:使用序列建模算法(Transformers)而不是使用RL方法(例如拟合值函数)训练策略,该策略将告诉我们要采取什么行动来最大化回报(累积奖励),该算法将给定所需的回报、过去状态和操作,生成未来操作以实现所需的回报。这是一个以预期回报、过去状态和行动为条件的自回归模型,以生成实现预期回报的未来操作。
这是强化学习范式的完全转变,因为我们使用生成轨迹建模(建模状态、动作和奖励序列的联合分布)来取代传统的RL算法。这意味着在Decision Transformers中,不会最大化回报,而是生成一系列实现预期回报的未来行动。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢