
我会每天撰写一个AI前沿术语词知识贴,欢迎各位在评论区提出想要了解的词!如果对文章内容有任何问题或建议,也欢迎指正!
欢迎对文章多多点赞,可以关注我的主页,不错过AI前沿内容!
知识点
- 与一般的微调方法不同,Delta Tuning方法只微调超大规模模型的一小部分参数,极大地降低了计算和存储的成本。
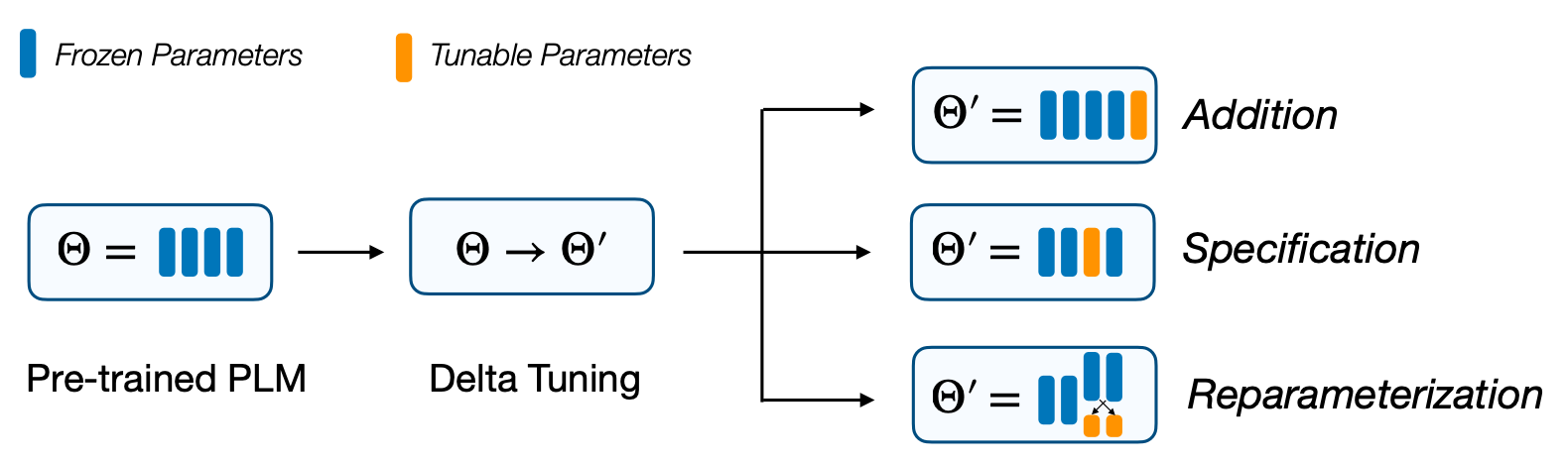
- Delta Tuning方法总共可以分成三类,分别是:Addition-based方法、Specification-based方法和Reparameterization-based方法。
- Delta Tuning目前已经在预训练模型的研究方面取得应用,包括提升模型的微调效率,降低计算和存储成本,提升模型的多任务学习能力,减少灾难性遗忘的出现,以及为模型在工业界应用提供支持。
定义
在预训练模型领域,模型经过预训练后,需要使用微调(Fine-tuning)等方法,使其能够在下游任务上进行推理和使用。随着模型参数规模的快速增长,对于模型进行参数的微调成本非常高昂。因此,许多研究者开始探索更为高效的大模型微调方法,这类方法——包括更为高效的参数微调方法等,统称为Delta Tuning,由清华大学、北京智源人工智能研究院的研究者在2022年3月提出。
与一般的微调方法不同,Delta Tuning方法只微调超大规模模型的一小部分参数,极大地降低了计算和存储的成本。[1]
Delta Tuning的方法有哪些
根据论文“Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models”[1],研究者将Delta Tuning方法分成了三种,分别为:
1.Addition-based
这一方法引入了额外的可训练的神经模块和参数,这些参数是原始模型中不存在的。微调针对的是这些额外引入的参数。Addition-based方法主要包括Adapter-based Tuning和Prompt-based Tuning(包括Prefix-tuning)两种。
2.Specification-based
这一方法对模型中特定的参数和过程进行训练,但其他部分保持冻结状态。Specification-based方法中主要包括Heuristic Specification和Learn the Specification两种。
3.Reparameterization-based
这一方法对模型中已有的参数进行重新参数化,使其在微调过程中更为高效。Reparameterization-based方法中主要包括Intrinsic Dimensions of PLM Adaptation、Intrinsic Rank of Weight Differences和Intrinsic Space of Multiple Adaptations三种。
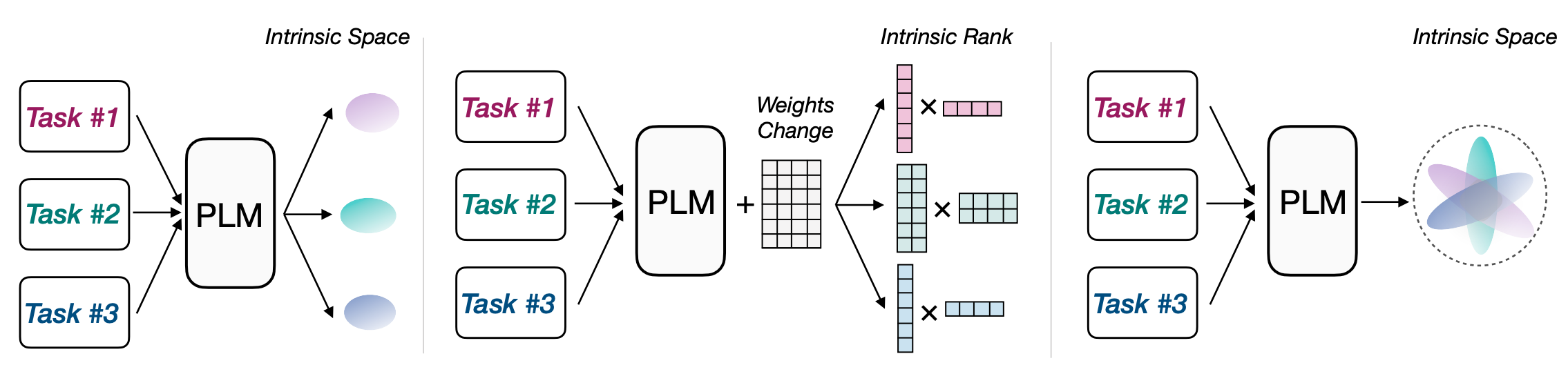 图注:Reparameterization-based的三种主要方法
图注:Reparameterization-based的三种主要方法
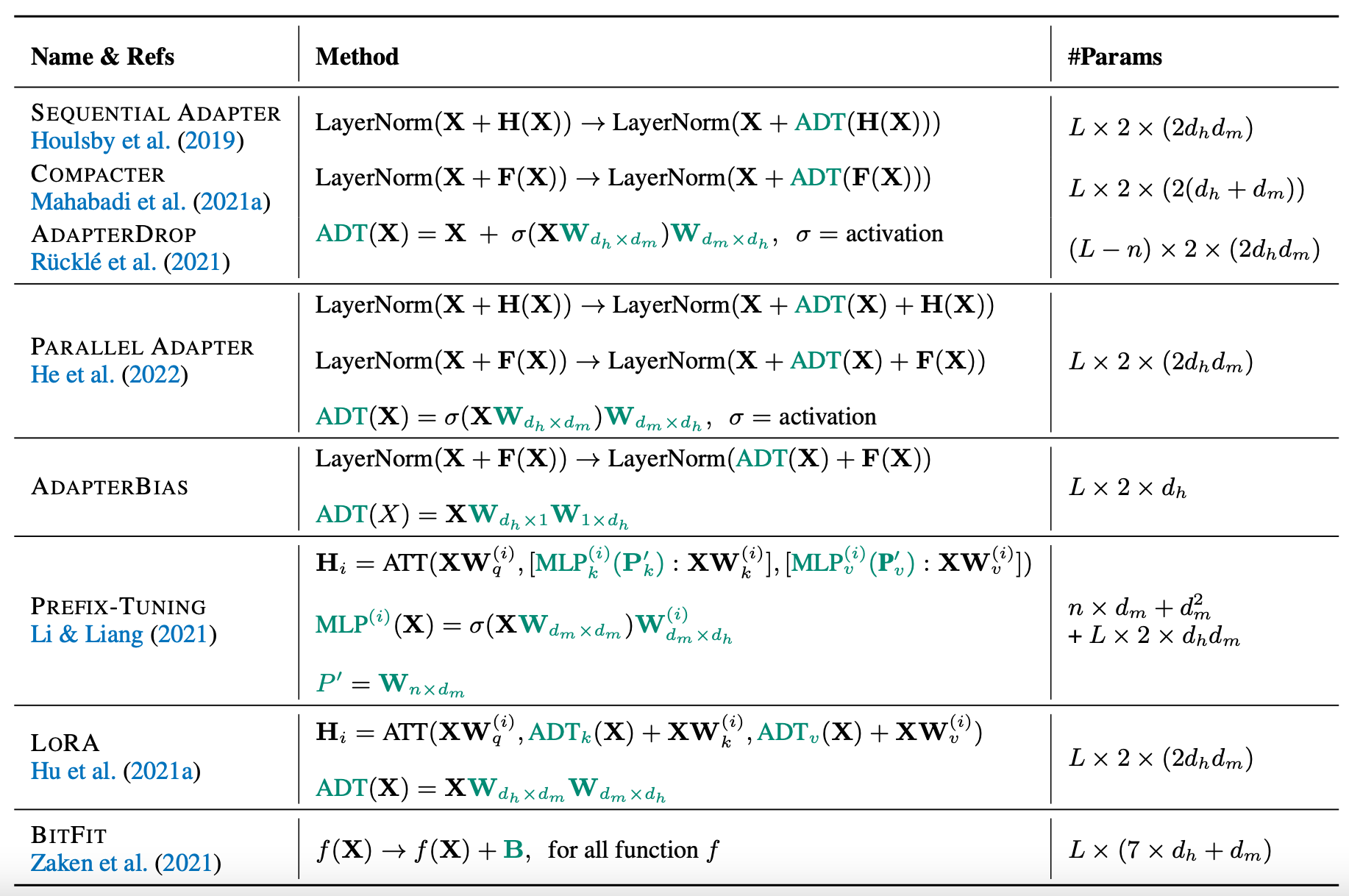
图注:一些Delta Tuning的方法
Delta Tuning的应用
Delta Tuning目前已经在预训练模型的研究方面取得应用。
首先,Delta Tuning能够更快地训练大模型,其反向传播的规模显著下降,降低了计算成本。例如,Rücklé等人[2]的研究显示,与微调相比,在模型上使用Adapters方法,能够在下游任务微调上降低40%的训练时间,而且模型还能保持与微调一样的性能。Mahabadi等人[3]的研究也指出,一系列Delta Tuning方法可以显著降低训练时间和峰值GPU内存。
其次,Delta Tuning可以提升模型的多任务学习能力,并保持相对较低的额外存储。例如,Pfeiffer等人[4]提出了一种多语言学习的方法,其中有一种可逆Adapter模块。这些模块可以支持多个子任务之间的知识迁移,还能维持较低的参数开销。其他多任务学习领域还包括问答、零样本迁移等。
此外,Delta Tuning还可以缓解模型中存在的灾难性遗忘问题。当模型按一定顺序训练一系列任务的过程中,在没有正则化情况下,对预训练模型进行全参数更新会导致灾难性遗忘的情况[5]。而Delta Tuning只需要微调很小部分的参数,因此它可能是一个解决灾难性遗忘的方法。
最后,Delta Tuning能够推动语言模型成为一种服务,并实现In-batch并行计算。当前,将大规模语言模型打包为一种服务已经是一个趋势。用户可以通过API与模型进行交互,获得模型的推理结果。考虑到用户和服务商之间巨大的通信成本,Delta Tuning明显比微调更适合这些模型。服务商只需要调整部分参数,就能让模型适应下游任务。
此外,Delta Tuning中的Prompt Tuning和Prefix-tuning支持并行计算,这能够让多个用户的实例在同一个Batch进行训练和验证。
目前已有一些基于Delta Tuning的开源框架,如OpenDelta[6]。用户可以非常容易地在微调大模型的过程中使用Delta TUning的技术。
参考链接
[1]Ding et al. (2022) Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models. https://arxiv.org/abs/2203.06904
[2]Andreas Rücklé, Gregor Geigle, Max Glockner, Tilman Beck, Jonas Pfeiffer, Nils Reimers, and Iryna Gurevych. AdapterDrop: On the efficiency of adapters in transformers. In Proceedings of EMNLP, pp. 7930–7946, 2021. URL https://aclanthology.org/2021.emnlp-main.626.
[3]Rabeeh Karimi Mahabadi, James Henderson, and Sebastian Ruder. Compacter: Efficient low-rank hypercomplex adapter layers. ArXiv preprint, abs/2106.04647, 2021a. URL https://arxiv.org/abs/2106.04647.
[4]Jonas Pfeiffer, Ivan Vulic, Iryna Gurevych, and Sebastian Ruder. MAD-X: An Adapter-Based Framework ´ for Multi-Task Cross-Lingual Transfer. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 7654–7673, Online, 2020b. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.617. https://aclanthology.org/2020.emnlp-main.617.
[5]Xisen Jin, Dejiao Zhang, Henghui Zhu, Wei Xiao, Shang-Wen Li, Xiaokai Wei, Andrew Arnold, and Xiang Ren. Lifelong pretraining: Continually adapting language models to emerging corpora. arXiv preprint arXiv:2110.08534, 2021. URL https://arxiv.org/abs/2110.08534.
[6] OpenDelta:https://github.com/thunlp/OpenDelta.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢