
药物推荐 (Medication Recommendation) 是智能医疗的一大研究方向,目前大量的药物推荐工作是基于医疗电子病历 (EHR) 展开的。随着数据的完善以及相关技术的发展,药物推荐方法经历了由“基于规则的推荐模式 (Rule-based recommendation)”向“基于实例的推荐模式 (Instance-based recommendation)”再到“纵向推荐模式 (Longitudinal recommendation)”的转变。并且,根据建模对象和关注重点的不同,当前相关工作有的关注用户画像建模即病人状态建模,而有的更关注药物表示学习。本文将从这两个方面出发,介绍 4 篇与药物推荐相关的工作。
文章概览
-
Change Matters: Medication Change Prediction with Recurrent Residual Networks (基于循环残差网络的药物变更预测)
论文地址:https://www.ijcai.org/proceedings/2021/0513.pdf
这篇工作来自于伊利诺伊大学香槟分校,发表于IJCAI2021. 现有的方法侧重于预测当前就诊的所有药物,这通常与历史就诊的药物有所重叠。这篇文章则是将建模的目标放在药物变更的预测(包括增加与删除),与传统方法直接对患者整个病史进行建模有所不同,这篇工作是基于残差进行推断的,只允许基于最新的患者特征(例如最近就诊的新诊断)进行更新,在方法上具有启发性。
-
Personalizing Medication Recommendation with a Graph-Based Approach (基于图方法的个性化药物推荐)
论文地址:https://dl.acm.org/doi/pdf/10.1145/3488668
这篇工作来自于新加坡国立大学,发表于ACM TOIS (Vol 40). 这篇工作将药物信息建模作为重点,基于药物相互作用图 (Drug-drug interactions, DDI) 和共现图 (Co-occurrence graph) 提供了一种较为宏观的药物表示学习方法。并且,建模中采用了注意力机制使得推断过程更具可解释性。
-
: Dual Molecular Graph Encoders for Recommending Effective and Safe Drug Combinations (: 用于有效安全药物组合推荐的对偶分子图编码器)
论文地址:https://www.ijcai.org/proceedings/2021/0514.pdf
这篇工作同样来自于文章1的团队,同样发表于IJCAI2021. 与文章1不同的是,这篇文章提供了一种中微观的药物表示学习方案,即将药物分子结构作为建模对象。并且,通过对药物全分子图和子结构两个层面的编码,实现药物分子的连接性和功能性的学习。实验表明,文中提出的模型具有更少的参数,训练速度和推理速度比基线模型有较大提升,并且推荐结果也更优。
-
Pre-training Molecular Graph Representation with 3D Geometry (基于三维几何的分子图表示预训练)
论文地址:https://openreview.net/pdf?id=xQUe1pOKPam
这篇工作来自于Mila实验室,被ICLR2022接收。分子图通常由二维拓扑结构建模,但有研究表明三维几何信息在预测分子功能方面起着更重要的作用。因此,这篇文章提出了多视图预训练框架 (GraphMVP),利用二维拓扑结构和三维几何视图之间的对应性和一致性来进行自监督学习,以服务其他下游任务。
任务描述
基于EHR的药物推荐任务要求将患者的历史问诊记录作为输入,预测当前问诊应给出的相关药物。
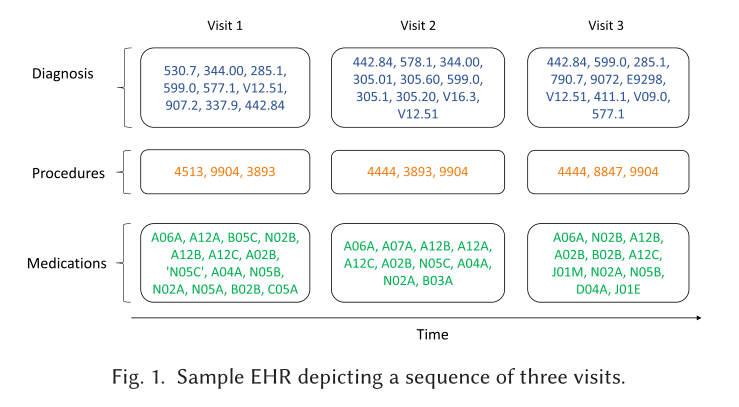
如图所示,对患者,用 表示患者的所有历史问诊记录,每一次问诊记录中,有患者的诊断 (Diagnoses)、医学操作 (Procedures) 如手术检查等,和药物 (Medications) 的信息,. 其中 用multi-hot向量记录了上述三种信息。此外,药物之间的相互作用信息也越来越被重视,DDI矩阵 描述了药物之间是否具有不良反应 (1为相互作用,0为安全联合处方). 因此,任务的输入输出为:
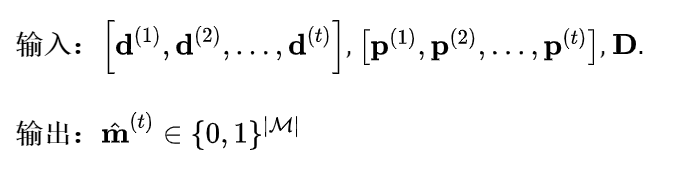
论文细节

动机
在多次就诊的患者中,尽管大多数患者在连续就诊期间被诊断患有不同的疾病(平均Jaccard低于0.2),但药物组合保持相对稳定(平均Jaccard约为0.5)。然而,目前很少有人探究和利用这种药物模式来进行药物推荐,作者认为的主要挑战有(1)如何准确描述每个时间步患者健康状况的变化,(2)如何根据健康状况变化来正确识别药物变化。基于此,作者提出了一种局部的“循环残差学习”的方法来进行病情建模和药物变更预测。
方法
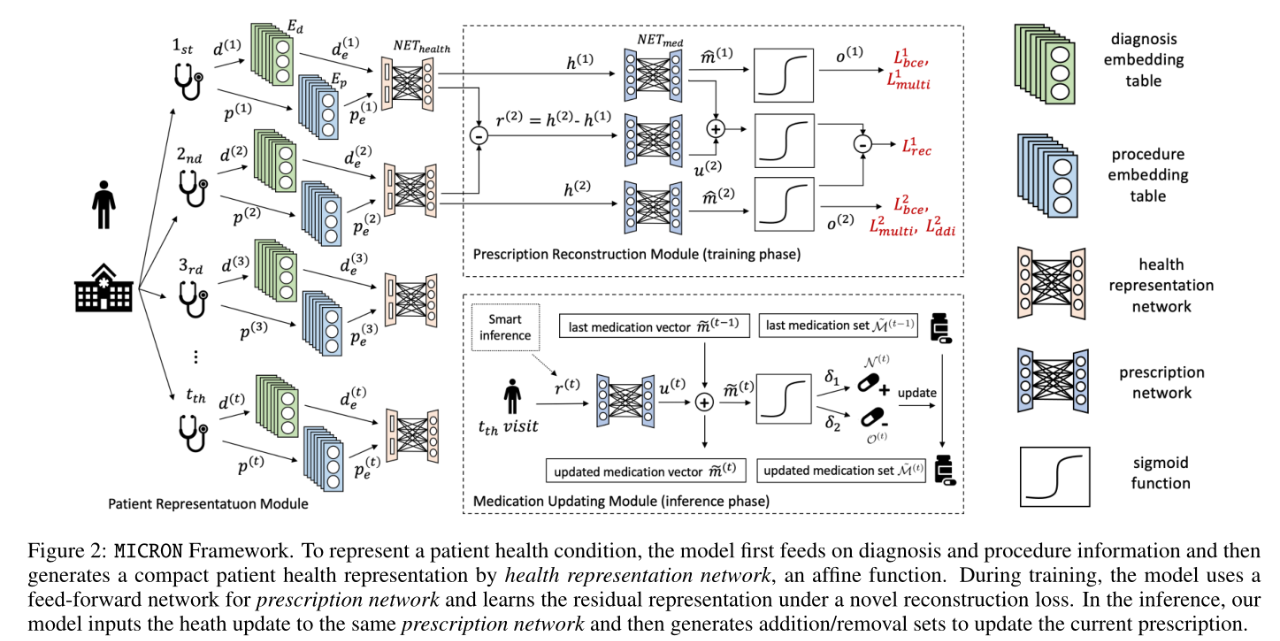
由一个患者编码模块、一个处方重建模块(训练阶段)和一个药物更新模块(测试阶段)所组成
(1) 患者编码模块
利用诊断、医学操作嵌入矩阵和前馈神经网络进行时刻的病人状态编码
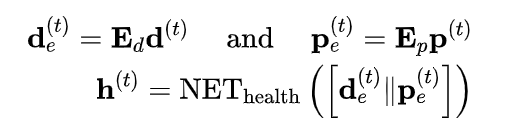
(2) 处方重建模块(训练阶段)

(3) 药物更新模块(测试阶段)
在测试阶段,模型首先进行药物状态更新,其次根据设定的阈值进行药物的增添和删除,最后产生各时刻的药物推荐组合。

实验
实验采用了一个公开的住院EHR数据集MIMIC-III和一个私密的门诊数据集IQVIA。
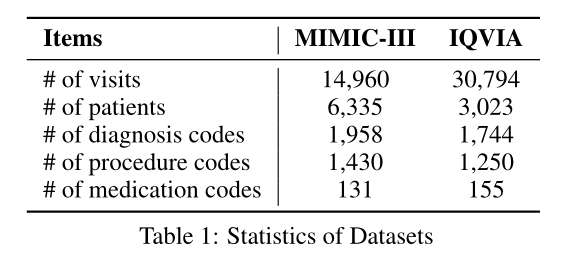
主要结果
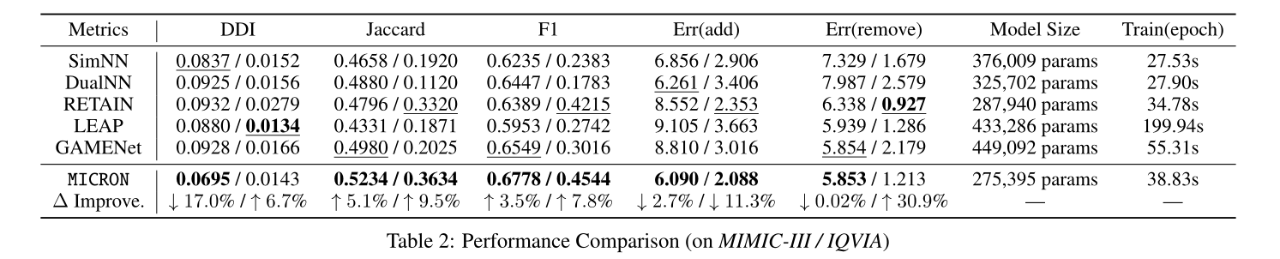
MICRON在住院和门诊设置方面都优于大多数基线,尤其是在Jaccard和F1指标方面。LEAP在两个数据集上给出了相对较好的DDI度量;然而,就准确性而言,其性能不如其他基线。SimNN和DualNN是基于实例的基线模型(只考虑当前时刻的状态),RETAIN则使用序列建模,三者在MIMIC-III上的表现不相上下,但对于门诊药物变化预测(在IQVIA上),RETAIN显示出强劲的表现。作者认为,门诊EHR中两次就诊之间的时间跨度可能更长,因此记忆单元在GAMENet中不太可靠。而MICRON通过学习有效的残留表征,为住院或门诊患者提供了更准确、更安全的用药建议。
消融实验
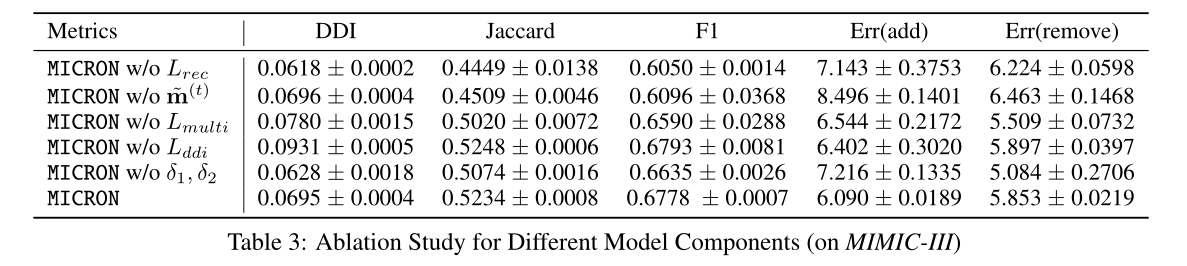
消融实验的结果表明,文中提出的几种机制是有效的。总的来说,所有其他变体都比表格中前两行的变体表现得更好,突出了残差重构在模型中的重要性。作者认为,没有药物载体,模型无法记忆纵向信息,因此结果较差。同时,在没有DDI损失的情况下,变型 (iv) 的DDI率显著高于其他模型变型。通过各个组件的配合,实现了更平衡、更稳定的性能。

动机
使用GCN建模药物相互作用信息的药物推荐系统无法捕捉不同药物相互作用的严重程度。这是因为GCN在固定大小邻域上进行卷积运算,并不能对节点的贡献程度进行建模。这种限制在药物推荐实践中可能会产生严重影响,例如:由于使用抗炎药(如布洛芬)和抗凝剂(如依诺肝素)而导致长期或永久性瘫痪的不良药物作用应当比使用布洛芬和利纳克罗肽等便秘药物后出现腹泻而严重得多。基于此,作者采用了GAT,并通过使用多头注意力来建模同一邻域中不同节点的重要性。
方法
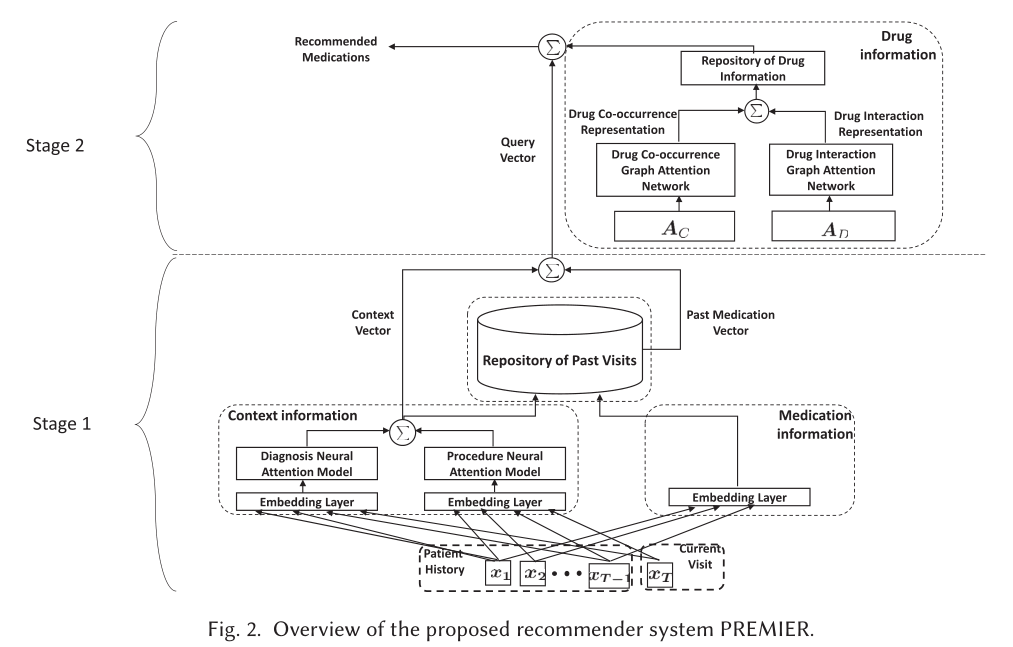
作者将整体的框架解耦成两个阶段,第一个阶段是查询生成,即基于患者历史的诊断和医疗操作总结患者病情表示向量,第二个阶段为药物信息检索,即基于患者病情的表示向量以及药物的表示,进行匹配学习。
(1) 查询生成
-
就诊级别的诊断重要性
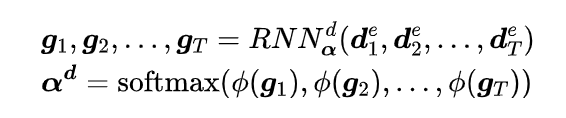
-
诊断级别的重要性
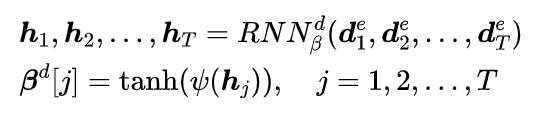
其中建模各个诊断的贡献大小,而建模贡献的方向。
-
当前诊断表示
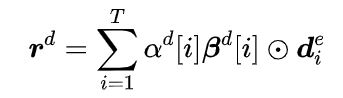
依照相同的方式,可以对当前操作的表示进行建模,然后对两者进行融合得到患者当前病情的综合表示,再通过对历史药物建模,得到查询向量
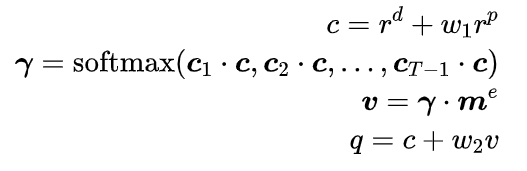
(2) 药物信息检索

由于在两个阶段中,模型均采用了注意力机制进行学习,因此,该方法可以对各来源信息的贡献进行比较来验证药物推荐的合理性。在模型的损失函数选取上,与近期其他工作保持了一致,选取了交叉熵损失、多标签合页损失和DDI损失的调和。
实验
实验采用了一个公开的住院EHR数据集MIMIC-III和一个私密的门诊数据集PRIVATE。
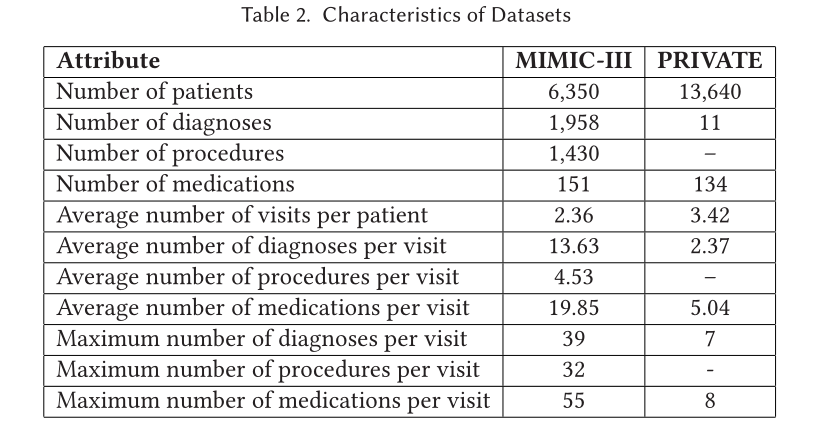
(1) 敏感性分析
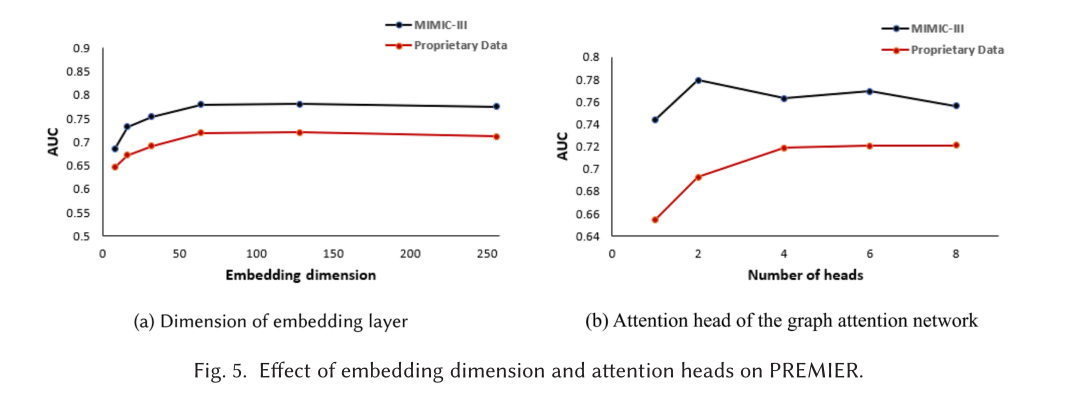
作者对模型中的各组超参数进行了敏感性分析,在GAT的注意力头选择上,对于MIMIC-III数据集,首层采用2个注意力头可以得到最好的效果,而对于PRIVATE而言,4个注意力头是更好的。其他超参数的选择在原文中有相关说明。
(2) 对比分析
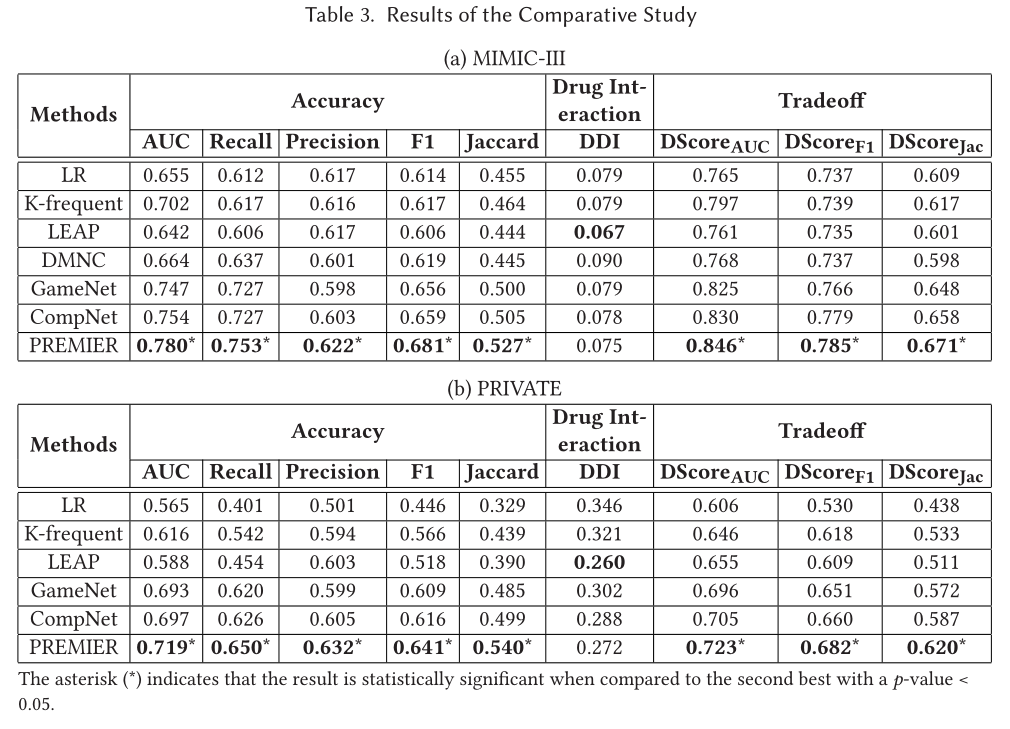
表中的数据表明,文中提出的方法在两个数据集上都取得了最好的推荐效果,作者将这种提升归因于纵向就诊史的注意力建模和药物相互作用的注意力建模。
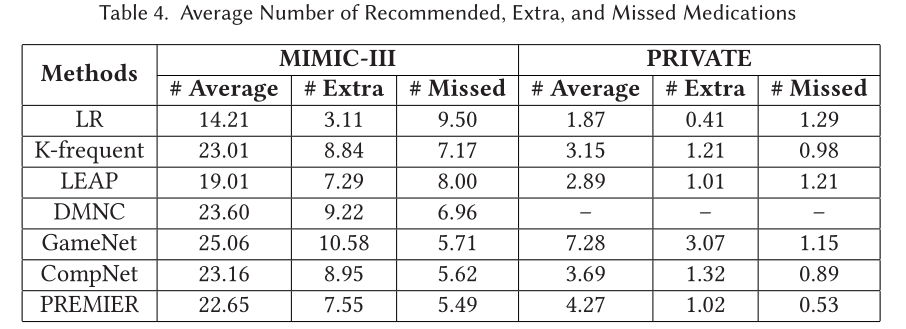
另外,从表4中可以看出,PREMIER的推荐策略是比较平衡的,不像LR和LEAP那么保守,也不像GAMENet那么激进,表现出来即模型推荐的额外药物和缺失药物都相对较少。其他更多的实验结果可以查阅原文。
(3) 消融实验
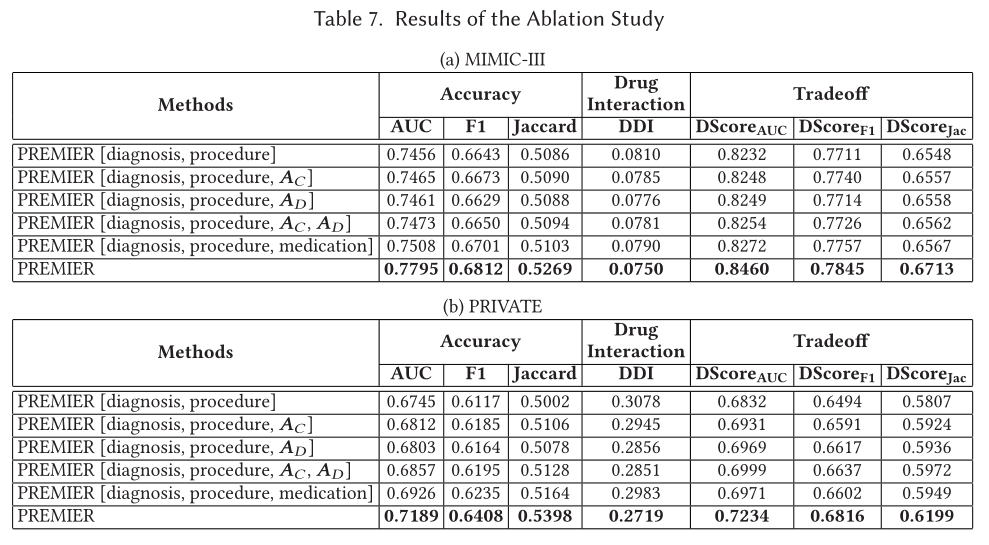
消融实验结果表明,药物共现图、药物相互作用图以及历史药物信息是有效的,并且这些信息隐式地蕴含了药物之间的DDI信息,使得引入这部分信息,尤其是后,模型的DDI指数相对于基础模型有明显的下降。

动机
现有的大量药物推荐工作存在药物编码不足的缺陷,(1) 药物通常使用独热编码进行表示,忽略了药物在分子图层面中的重要药物特性,如疗效和安全性。此外,分子子结构可能与药物功能相关,这些知识有助于提高药物推荐的准确性和安全性。(2) 隐式和不可控的DDI建模。一些现有研究通过软约束或间接约束对药物相互作用DDI进行建模,导致最终推荐或次优推荐准确率不可控。基于此,作者提出了一个DDI可控的药物推荐模型,名为,模型在药物推荐中加入分子结构以获得收益。
方法
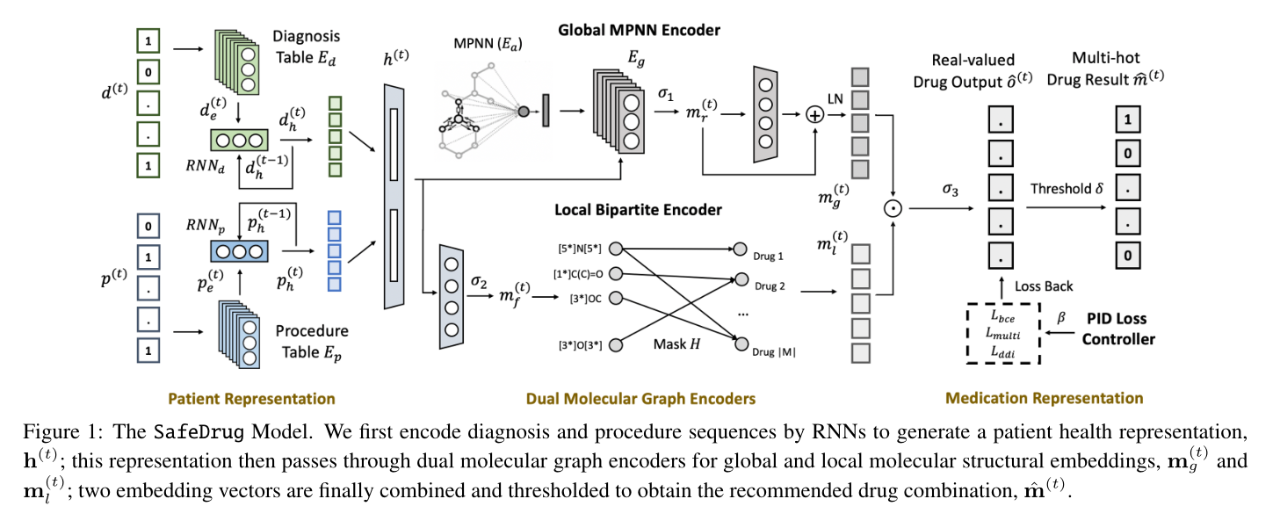
模型共有四个组件:纵向患者表征模块、全局信息传递神经网络 (MPNN) 编码器、局部二部编码器和药物表示模块
(1) 纵向患者表征模块
对诊断嵌入和操作嵌入进行融合
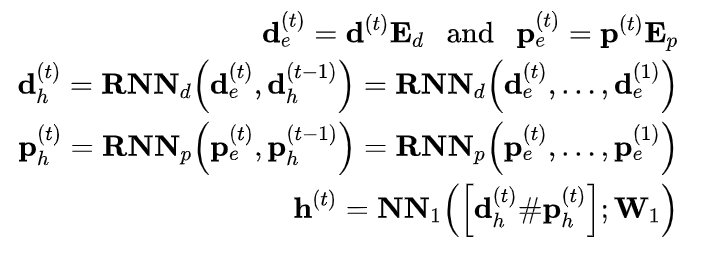
(2) 全局 MPNN 编码器
MPNN利用GNN对分子图中的各原子邻接关系进行建模。各原子表示的更新公式为
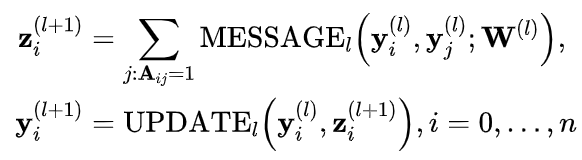
基于分子图和原子表示的分子聚合表示为
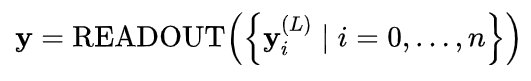
因此,可以得到药物分子全局信息与患者表征的匹配得分
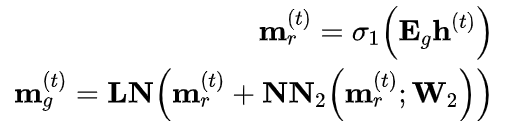
(3) 局部二部编码器
使用MPNN编码器可以将具有类似结构的分子映射到临近的空间。然而,作者在文中指出,药物的功能性更多地通过分子子结构反映出来,分子子结构可以理解为一组相互连接的原子,二部编码器就是用于捕获药物的这种局部功能性及其依赖性。

(4) 药物表示模块

(5) 损失函数
损失函数同样由交叉熵损失、多标签合页损失和DDI损失共同贡献,
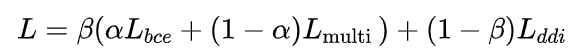
不过与前文不同的是,DDI损失的系数并非固定的系数,而是一个指数函数
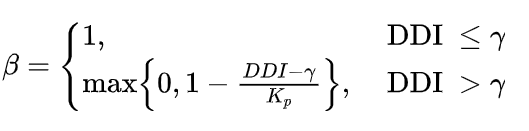
当DDI较大时,模型利用DDI损失进行惩罚,当DDI较小时,相应的惩罚减小,通过这种方式,可以选取不同的阈值来实现控制DDI的效果。
实验
实验同样在MIMIC-III数据集上进行。
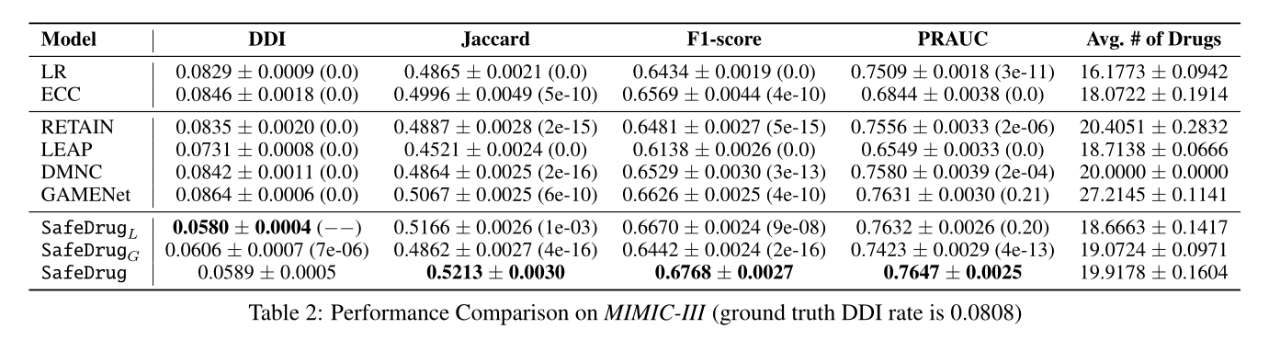
与各个基线模型相比,SafeDrug及其变体具有更好的推荐效果,且DDI更低,表明其能给出更安全的药物组合。消融实验表明,SafeDrug中的全局编码器和局部编码器都对整体有正向作用。
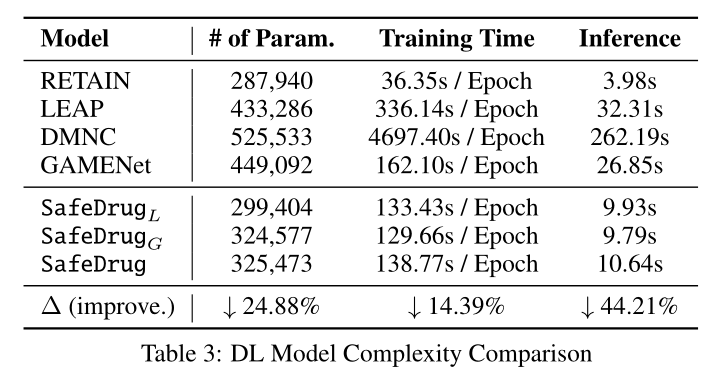
并且SafeDrug参数量更小,训练和推断速度更快。
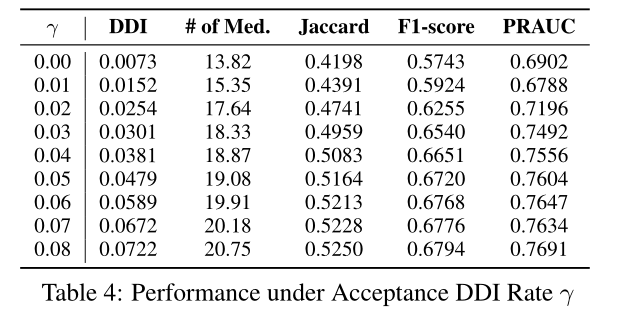
表4显示了不同阈值对于模型表现的影响,的减小对于DDI和推荐准确率指标的边际影响是不同的。通过控制阈值,可以使得模型给出的推荐组合的DDI处于比真实数据集中更低的水平,从而实现更安全的推荐。

动机
分子图表征学习是现代药物和材料发现中的一个基本问题。分子图通常由二维拓扑结构建模,但最近相关研究发现三维几何信息在预测分子功能方面起着更重要的作用(例如相似或相同的药物之间可能具有不同的手性,两个具有相同2D拓扑结构但具有不同手性的分子互为对映体,对映体之间通常表现出不同的功能)。然而,现实场景中缺乏3D信息,这严重阻碍了几何图形表示的学习。基于此,作者提出了GraphMVP框架,是一种基于最大化2D和3D视图之间的互信息 (MI) 的自监督学习 (Self-Supervised Learning, SSL) 方法,使学习到的表示能够捕捉分子中的高维几何信息,使得下游任务可以有所增益。
方法
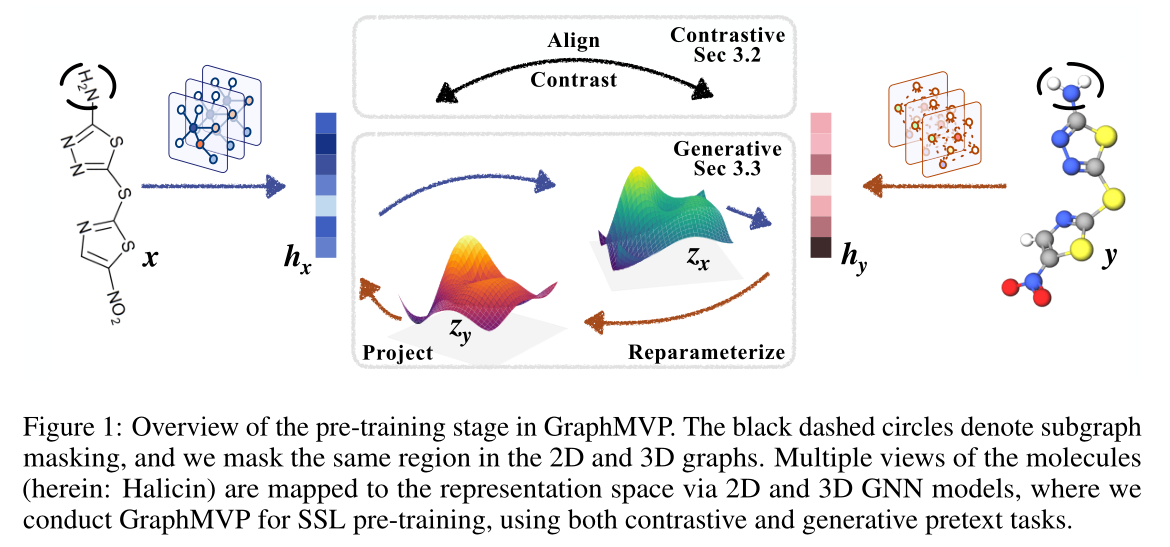
在SSL预训练阶段,作者设计了两个任务:一个对比任务和一个生成任务。文中推测并实证证明这两项任务侧重于不同的学习方面,总结为以下两点。(1)从表征学习的角度来看,对比任务更关注分子间的知识,而生成任务更关注分子内知识。对比SSL的重点是构造分子间差异的样本对;而生成式SSL则将重点放在每个分子本身上,捕捉分子内关键信息来重建分子。(2)从分布学习的角度来看,对比SSL和生成SSL分别从局部和全局的角度学习数据分布。对比SSL通过在数据间级别对比样本对之间的距离,学习局部分布。因此,在数据足够多的情况下,局部对比操作可以较好学习数据分布。另一方面,生成SSL则是直接学习全局数据分布。
(1) 对比自监督学习
2D和3D的分子表示由两个不同的GNN进行编码,在对比自监督学习任务中,作者采用了两组损失函数进行对比。
-
InfoNCE
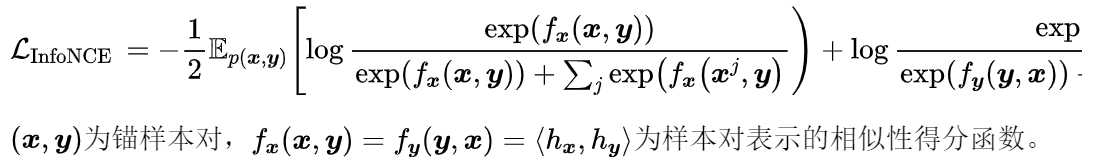
-
Energy-Based Model with Noise Contrastive Estimation (EBM-NCE)
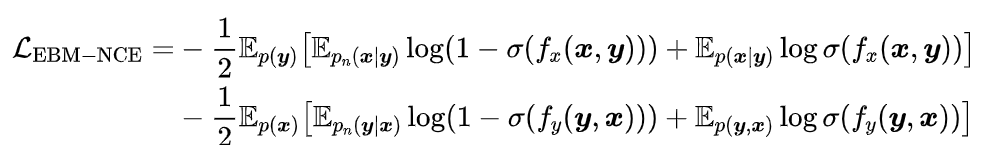
EBM-NCE是一种被广泛应用于图对比SSL的替代方案。它的意图与InfoNCE基本相同,即对齐正样本对和区分负样本对,而主要区别在于使用二进制交叉熵和额外的噪声分布进行负采样。
(2) 生成自监督学习
生成式SSL是无监督预训练的另一个经典方案。在药物发现方面,每个分子具有一个2D图和一定数量的对映体,该环节的目标是学习一种强大的2D/3D表示法,在最大程度上可以恢复其3D/2D对应物。通过这样做,生成式SSL可以引导2D/3D GNN对最关键的几何/拓扑信息进行编码,从而提高下游任务的性能。在这篇工作中,作者选择 了VAE来进行自监督学习,原因如下:(1)两个分子视图之间的映射是随机的:多个3D构象对应于相同的2D拓扑;(2) 下游任务需要明确的2D图表示(即特征编码器)
-
变分分子重构
在从相应的二维拓扑生成三维构象时,需要对条件似然进行建模。该条件概率有下界:
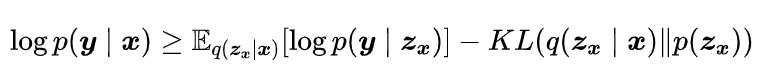
同理也类似。然而,在数据空间上进行图形重建并非易事(即的计算):由于分子(例如原子和键)是离散的,在分子空间上建模和测度将带来额外的障碍。
-
变分表示重构 (VRR)
为了克服上述的问题,作者提出了一种新的损失函数,将分子重构转化为表示重构,由离散转为连续。由于表示空间是连续的,也可以用高斯分布对条件对数似然进行建模,从而得到重建的L2距离。
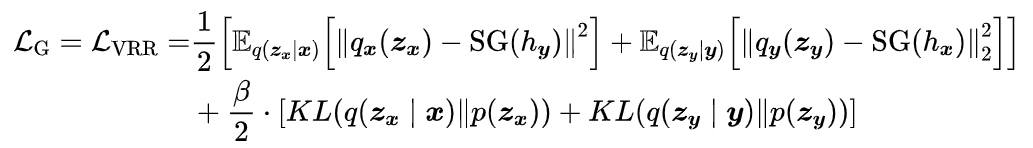
(3) 损失函数
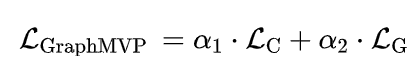
GraphMVP的损失函数由对比和生成两种损失调和而成。并且,集合现有工作中设计的各种基于2D的SSL损失函数,可以构造GraphMVP损失函数的变体。

实验
实验中采用的基线模型详见原文,文中采用的2D-GNN为图同构网络GIN,3D-GNN为SchNet.
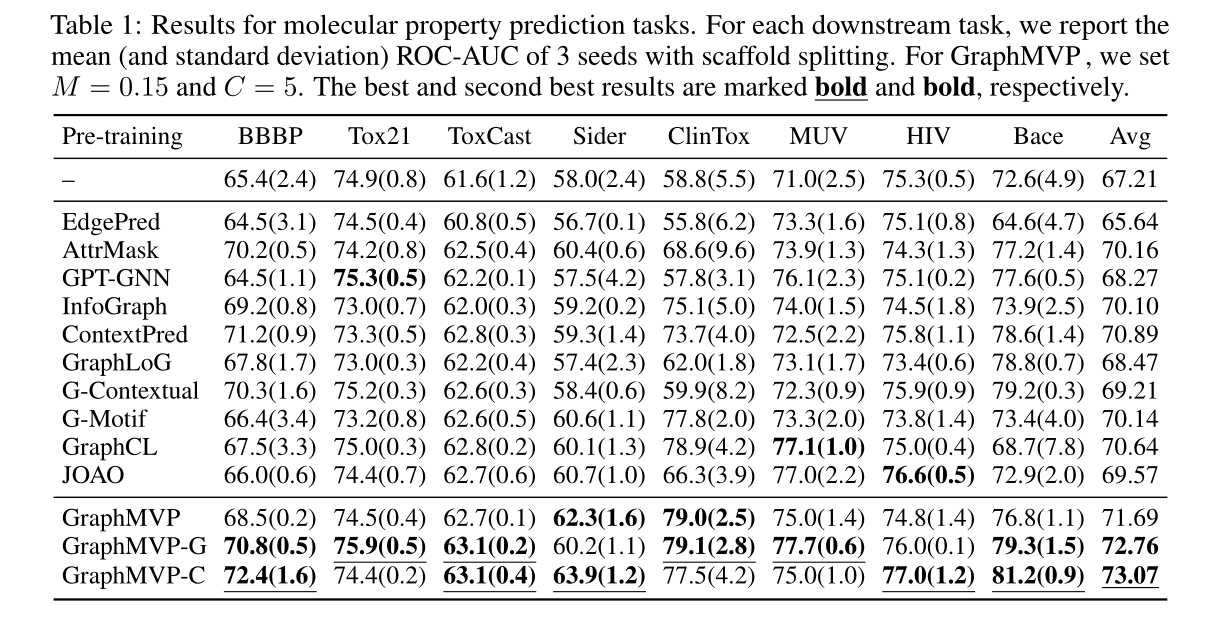
在分子性质预测任务上,文中提出的方案明显优于随机初始化的方法,并且几乎在所有预测任务上都是最佳的。作者认为,3D几何信息是2D拓扑信息的补充,GraphMVP协调了三维几何和二维拓扑之间的信息,从不同的角度提取信息,是相辅相成的。

敏感性分析表明,遮罩比例和异构体数量过多,对模型的边际收益增加不明显。
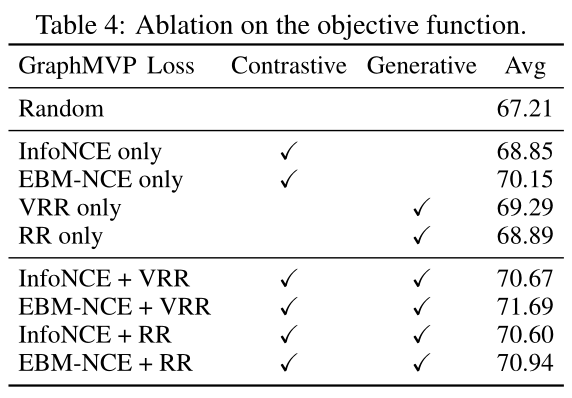
消融实验结果表明,每个单独的SSL目标函数都可以带来更好的性能,反映了添加3D信息有助于2D表示学习的说法。并且添加对比和生成SSL的组合可以得到更好的效果。同时,EBM-NCE比InfoNCE更有效,文中提出的VRR相比于RR也具有更好的效果。
更详细的实验结果说明和验证细节见原文。
总结
本文分享的四篇文章从几个不同的角度对药物推荐工作的研究动向进行了阐述,当前,对于药物的表示学习是一大研究重点。在ICLR2022接收的文章中,有许多关于分子表示学习的工作,这些方案对于药物推荐任务尤其是药物表示学习都有一定的借鉴意义。
参考文献
[1] Dwivedi, Vijay Prakash, et al. "Graph neural networks with learnable structural and positional representations." International Conference on Learning Representations (2022). 2021.
[2] Wang, Hongwei, et al. "Chemical-Reaction-Aware Molecule Representation Learning." International Conference on Learning Representations (2022). 2021.
[3] Godwin, Jonathan, et al. "Simple GNN Regularisation for 3D Molecular Property Prediction and Beyond." International Conference on Learning Representations (2022). 2021.
[4] Liu, Yi, et al. "Spherical message passing for 3d molecular graphs." International Conference on Learning Representations (2022). 2021.
[5] Xu, Minkai, et al. "GeoDiff: A Geometric Diffusion Model for Molecular Conformation Generation." International Conference on Learning Representations (2022). 2021.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢