
可信联邦学习会是下一个技术趋势吗?杨强教授为我们展现未来全面的发展愿景。

近日,机器之心 AI 科技年会在线上召开。在下午的人工智能论坛上, FATE 联邦学习开源社区技术指导委员会主席杨强教授做了主题为《可信联邦学习》的演讲。他带我们系统地回顾联邦学习的进展和挑战,并展望了该领域未来发展的一个重要阶段 —— 可信联邦学习。
演讲视频回顾:
https://www.bilibili.com/video/BV1GY4y1q7ek?spm_id_from=333.999.0.0
机器之心对演讲内容做了不改变原意的整理。
我今天讲的题目叫做「可信联邦学习」。
首先回顾一下整个 AI 发展的阶段。我们看到 AI 现在有很大的发展,但是在理想和现实之间有很大的鸿沟。AI 现在主要的成就在于中心化的数据,样本足够多,质量足够好,特征也足够多。这样的情况下可以做出非常好的模型,像现在的预训练模型。
但是,我们的真实世界数据是多元的,散落在各地,质量不同,属主不同,又带来不同的利益。数量的格式、质量、特征不同,随时间的变化大。理想化的 AI 没有考虑到的一个重要因素是,用户的隐私怎么解决,如何合规,监管和审计如何解决,等等。
所以我们看到现在很大的成就,像大模型,我们预计在未来它们的发展趋势应该是来自很多分布式的小模型。这些模型有很多都是自下而上自发的,并且它们的合作和共享都是通过联邦的形式进行的,即联邦学习(Federated Learning)。
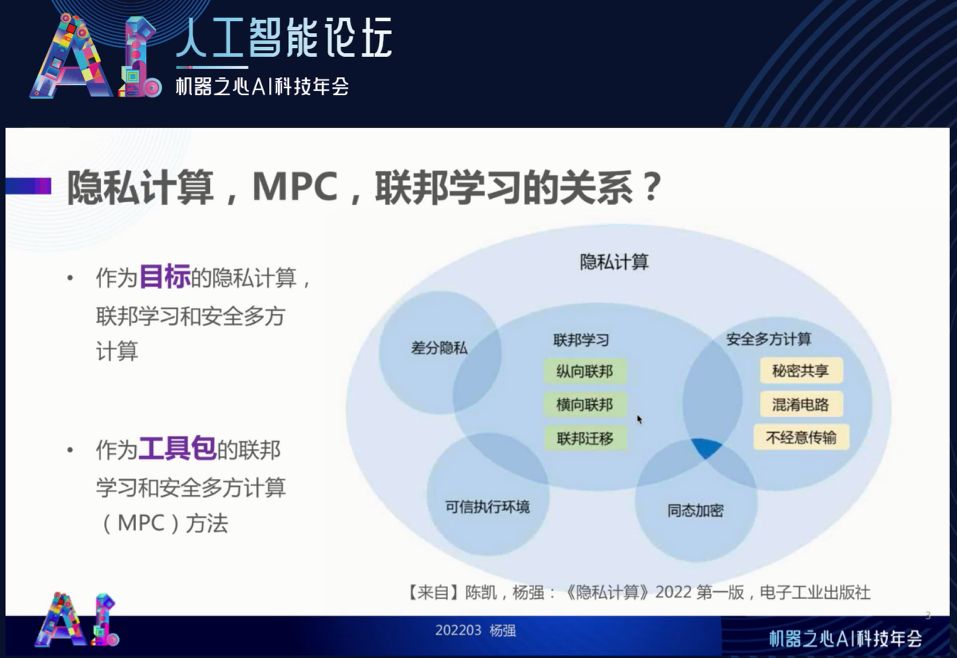
隐私计算、联邦学习和安全多方计算之间的关系
接着来看隐私计算和联邦学习,这些概念对大家来说已经不陌生了。经过三四年的市场教育,大家已经清楚什么是隐私计算,什么是安全多方计算(MPC),什么是联邦学习。但是,在不同的场合也有很多疑问。那么,到底隐私计算是联邦学习的一部分还是联邦学习是隐私计算的一部分?安全多方计算是联邦学习的子集吗?它们之间的关系又是怎样的呢?
首先概念不要混淆。我们有两个层次的概念,第一个是作为目标来说,隐私计算、联邦学习和安全多方计算三者的目标是共同的。尤其对于人工智能、多方数据建模的要求来说,联邦学习是一个我们要去解决建立和使用模型的目标。但是,这些技术从不同领域又提供了很多工具包,就像我们造了很多不同的砖一样,包括安全多方计算、加密算法,硬件,分布式机器学习等。这些砖作为工具包服务于联邦学习和安全多方计算以及隐私计算的目标。这些工具包本身还不能为我们解决想要解决的任务,因为我们的任务和目标是盖一座大楼,中间要利用到这些砖,即工具包。所以有的时候,我们所说的隐私计算指的是目标;有的时候指的是这些工具包。对于安全多方计算和联邦学习也是如此。
所以,我们说哪一个是哪一个的子集,哪一个是为哪一个服务,就要清楚我们说的是目标的概念,还是工具包的概念。我们可以看下图(右)。隐私计算作为目标来说,不同的技术路线都在试图解决它。但是,每个技术路线都有自己的特点,并有自己的工具包。这样来说,我们就可以解决谁到底是为谁服务的。我们一定要分清目标和工具包,工具包是为目标服务的。
有的时候,我们说联邦学习的目标可以用安全多方计算工具来解决,有时候安全多方计算的目标可以用联邦学习和差分隐私来解决。这些并不矛盾。
现在,隐私计算的发展已经有 40 年的历史,也经历了很多阶段。我们在这里总结一下这些阶段,相关信息出自最近我与陈凯老师以及很多优秀博士生合作完成的书籍《隐私计算》。
首先是安全多方计算,是理论计算机方向为整个计算机行业做出的贡献,即利用利用隐藏部分信息来保护隐私,基于各方交换的部分数据来计算正确的结果。这样做的好处是能够满足保护隐私的法律法规,但计算速度非常得慢。之后,出现了利用混淆个体的方式保护隐私的差分隐私技术和利用硬件来保护隐私的集中加密计算技术,它们都有各自的特点和问题。联邦学习是随着 AI 的发展,利用分布式多方建模的手段对模型作为一个主体进行生产,使用和管理而产生的。联邦学习和前面这些发明都不矛盾,不是替代关系,它们是相辅相成的。
从联邦学习到可信联邦学习
我今天特别要讲的主题是「可信联邦学习」,这里面有一个词叫做 NFL(No-free lunch, 没有免费的午餐)。另外一个叫知识产权保护,下面会特别讲到这些概念。
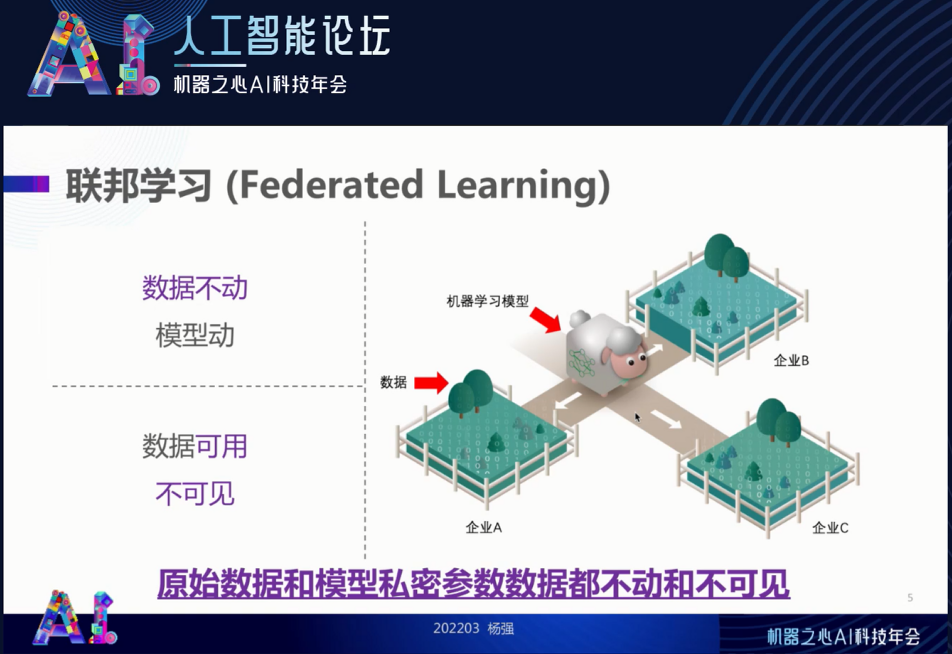
首先,我们简单地回顾一下联邦学习。我从一开始就说它的思想是「数据不动模型动、数据可用不可见」。有人认为这很好理解,但也有疑问:模型在不保护的前提下可以通过参数的传递泄露部分原始数据。我们说的数据不动模型动,意味着我们所设计的联邦学习算法,能保证原始数据和模型私密参数的数据都不能 “动”。如果模型参数泄露了原始数据,那这句话就成了空话。因此,联邦学习一定要严格地保证原始数据和重要模型参数真的原地不动,以保证联邦学习的安全。
下面再来说隐私保护、数据安全和模型效能到底是什么关系。所谓隐私,往往是对我们特别想要保护的部分数据而言,我们管这个数据叫 D(Data)。安全指的是整个系统的安全,也就是说,我们要保证所有数据 D 的安全。隐私往往特指要保证不泄露某些数据。所以,安全是指逻辑学里面的 “所有”(For all),而隐私是逻辑学里 “某些” 的概念。
同时,我们在说安全的时候,要绝对明确地定义出面对的 “威胁攻击” 的假设是什么,以及是怎么样的攻击。我们从教科书里面学到的是,这个攻击可以是半诚实的、恶意的、好奇的等。但是,我们一定要明确隐私计算和联邦学习系统所在的环境以及它可能受到的攻击到底是什么。
我在下图(右)列了两个极端,一个叫拜占庭式攻击,即某个参与者其实是坏人,或者部分时间是坏人,但混在参与者当中。还有一种攻击就像《三体》中水滴一样完全无法防御,这叫灾难式攻击(catastrophic threat),也叫极端性攻击。大部分情况下,我们面对的都是拜占庭式攻击。在这种攻击下,我们要确定自己的隐私保护到底是怎么样的。
所以,隐私保护(P)可以用联邦学习框架、同态加密作为工具,也可以用安全屋、安全多方计算的某种计算模式作为工具包。如何保护取决于我们的任务到底是什么。

总之,我们如果要给一个系统(如上图羊到多方吃草)定安全等级,绝对不能只看用的是联邦学习还是安全多方计算。我们一定要说自己保护的数据 D、威胁模型 T 和保护措施 P 到底是什么,在(D,P,T)三者都知道的情况下才可以定级。这个是真正的安全概念。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢