
我会每天撰写一个AI前沿术语词知识贴,欢迎各位在评论区提出想要了解的词!如果对文章内容有任何问题或建议,也欢迎指正!
欢迎对文章多多点赞,可以关注我的主页,不错过AI前沿内容!
知识点
1.随着知识图谱和大模型的规模、性能的快速增强,研究者逐步开始探索将二者融合的研究,知识增强大模型(Knowledge-enhanced Big Models)应运而生。
2.知识增强大模型可以分为将知识图谱作为“边信息”和让大模型学习知识图谱的能力两种。
3.在知识图谱和预训练模型融合方面,主要存在三个技术上的挑战:结构化的知识图谱与擅长非结构化的预训练模型结合的问题;文本和知识图谱嵌入在特征空间上的对齐问题;知识噪声的问题。
4.知识增强大模型的主要发展方向有:让模型学习知识图谱的能力,而非信息本身;在知识图谱中引入更多跨模态的信息,提升模型的性能。
定义
知识指的是对某个主题/概念获得的认识,可以用于理解、推理等用途。在AI领域,知识往往以知识图谱的形式进行表示。
知识图谱能够将人类的知识以结构化的形式存储下来,便于进行符号推理,并为理解人类语言和其他信息提供额外的知识,具有很大的应用潜力。
随着知识图谱和大模型的规模、性能的快速增强,研究者逐步开始探索将二者融合的研究,知识增强大模型(Knowledge-enhanced Big Models)应运而生。
目前,有三种类型的知识图谱已经和大模型产生融合,分别是:
1.世界知识(World Knowledge):包含世界上不断产生的新事实,以及事实性知识和百科知识;
2.常识知识(Commonsense Knowledge):日常生活中的事实,对于大模型非常重要,但目前在模型中很缺乏;
3.领域特定知识(Domain-specific Knowledge):为特定领域和应用构建的知识图谱,如生物医学、学术领域等。

图注:知识的类型及与其对应的知识表示增强的大模型
知识与大模型结合的方法及典型案例
根据“A Roadmap for Big Model”[1]报告,知识增强大模型可以分为以下两种:
1.将知识图谱作为“边信息”(Side Information*)
知识图谱可以提供很多长尾的世界事实,是预训练语料中几乎不存在的。同时,知识图谱及其对应的文本可以提供额外的预训练监督信号,提升模型对和事实相关文本的理解能力,提升在知识密集型任务上的性能。
在这类模型中,主要有以下几种知识增强大模型的方法:
(1)将知识图谱表征和表示学习融合的方法:将知识图谱中实体的嵌入向量输入到大模型中,典型的案例有清华的ERNIE[9]等;
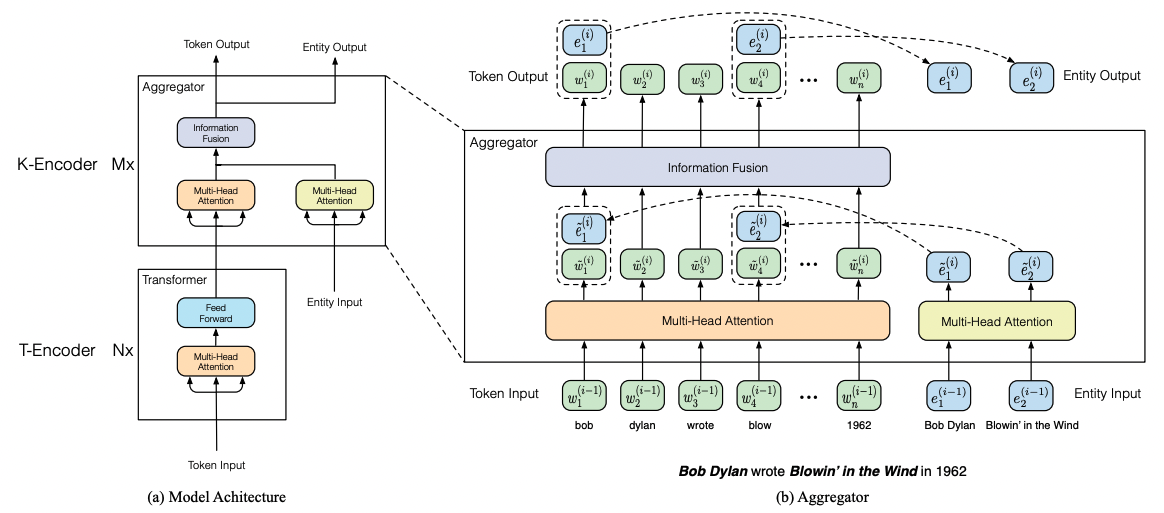
图注:ERNIE在传统的transformer encoder(也就是图中的T-encoder,T可以理解为token或者text)的基础上,加入了一种可以进行知识融合的encoder模块(对应图中的K-encoder)
(2)让表示学习算法和语义信息结合,而非直接使用知识图谱表示的方法:让模型动态地选择知识谱图的子图(Subgraph)作为输入的表示,知识图谱只帮助网络的初始化等阶段。例如,CokeBERT[2]让知识图谱的子图与一个语义驱动的图神经网络(Semantic-driven Graph Neural Network,S-GNN)进行融合和嵌入,使知识图谱只作为网络的初始化。
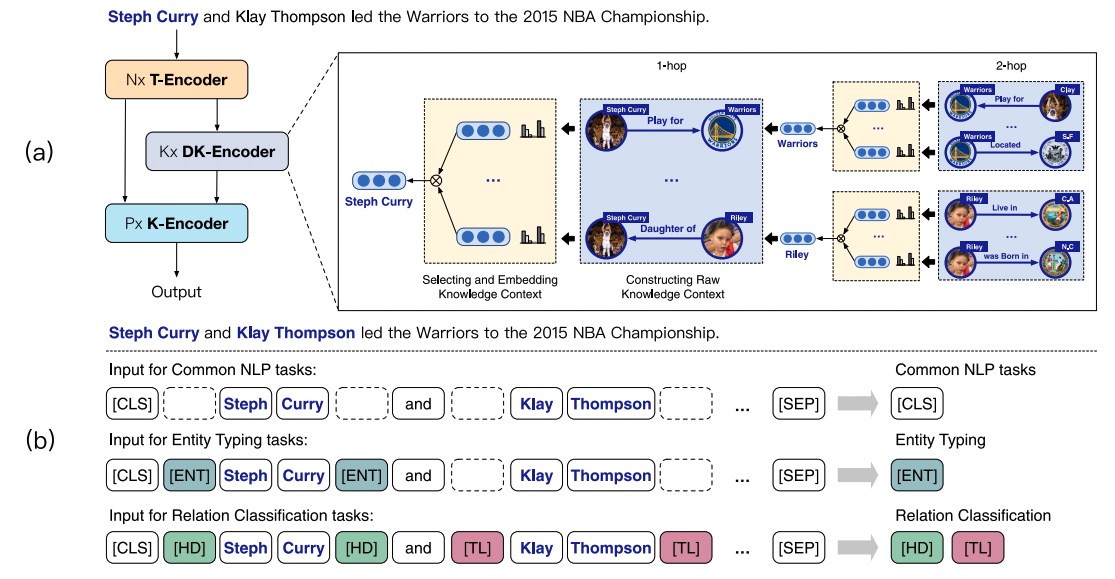
(3)在预训练阶段,使用知识图谱作为监督:将知识图谱中的实体作为预训练的一部分。例如,LUKE[3]在模型的词表中加入知识图谱的实体token,并使用遮盖语言建模的方式进行了预训练。为了让模型能够分辨词语和实体token,LUKE还引入了类型嵌入和实体感知的自注意力机制。
(4)加入额外的知识记忆:例如,FaE[4]采用key-value记忆的方式,在外部以及中保存了事实而非实体信息。
(5)使用知识图谱引导和提升语言模型的理解能力:让知识图谱给大模型“出”更难的语言理解题目。例如,百度的ERNIE1.0[5]中,知识图谱对预训练文本中的实体进行了遮盖,而非仅是词汇遮盖。
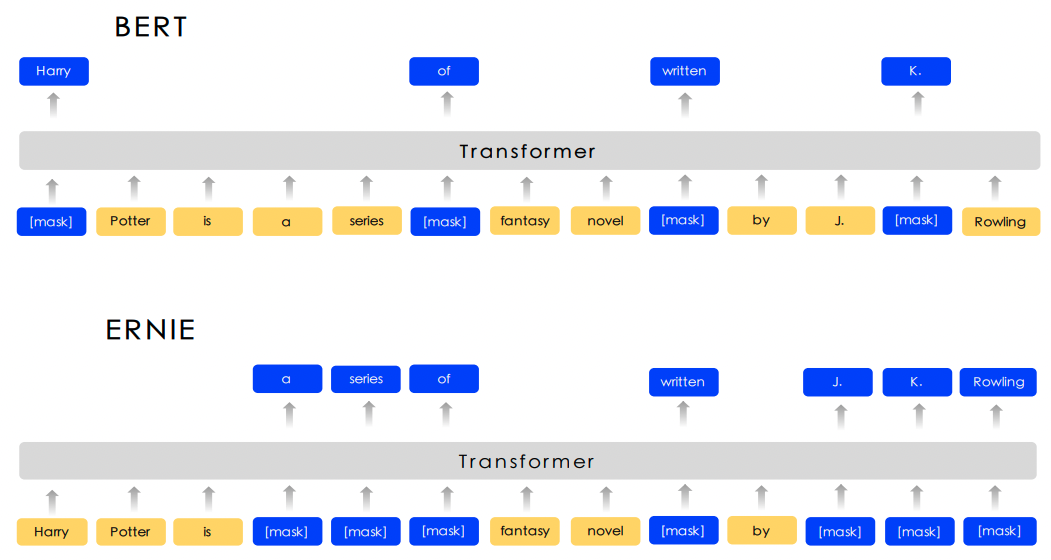
(6)采用知识图谱提升模型的语言生成能力:让语言模型从知识图谱中学习实体和关系特征,帮助其提升生成结果的质量,如KGLM[6]等
2.让大模型学习知识图谱的能力
让模型学习知识图谱中的符号推理能力,或者帮助补全知识图谱中缺失的事实。这是目前较为前沿的一个研究领域,相关案例包括KEPLER[7]等。
知识与大模型融合面临的技术挑战
在知识图谱和预训练模型融合方面,主要存在三个技术上的挑战[8]。
1.结构化的知识图谱与擅长非结构化的预训练模型结合的问题。
2.文本和知识图谱嵌入在特征空间上的对齐问题:知识图谱和文本是通过不同方式构建的,在特征空间上不完全相同。
3.知识噪声的问题:如果无法进行良好的融合,知识图谱信息不仅不会提升模型性能,反而还会降低预训练的效果。如知识图谱可能干扰注意力机制的计算,知识图谱带来的噪声可能破坏句子的结构和表达,影响模型的理解和生成等。
知识增强大模型的主要发展方向
1.学习知识图谱的能力,而非信息本身:知识图谱具有符号推理能力,怎样让模型也能够习得这种能力是一个值得探索的问题。
2.在知识图谱中引入更多种类的信息:目前知识图谱主要使用三元组事实进行存储,但图像、视频、语音等跨模态数据也可以提升模型的能力,如果能够利用知识图谱中的这些种类的信息,对于模型性能可能有更大的提升。
*Side Information:既不在输入空间也不在输出空间的知识,模型可以从中学到有用的信息
参考链接
[1] A Roadmap for Big Model: https://arxiv.org/pdf/2203.14101
[2] Su, Y., Han, X., Zhang, Z., Lin, Y., Li, P., Liu, Z., ... & Sun, M. (2021). Cokebert: Contextual knowledge selection and embedding towards enhanced pre-trained language models. AI Open, 2, 127-134.
[3] Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, and Yuji Matsumoto. Luke: deep contextualized entity representations with entity-aware self-attention. arXiv preprint arXiv:2010.01057, 2020.
[4] Pat Verga, Haitian Sun, Livio Baldini Soares, and William W Cohen. Facts as experts: Adaptable and interpretable neural memory over symbolic knowledge. arXiv preprint arXiv:2007.00849, 2020.
[5] Sun, Y., Wang, S., Li, Y., Feng, S., Chen, X., Zhang, H., ... & Wu, H. (2019). Ernie: Enhanced representation through knowledge integration. arXiv preprint arXiv:1904.09223.
[6] Robert L Logan IV, Nelson F Liu, Matthew E Peters, Matt Gardner, and Sameer Singh. Barack’s wife hillary: Using knowledge-graphs for fact-aware language modeling. arXiv preprint arXiv:1906.07241, 2019.
[7] Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu, Zhengyan Zhang, Zhiyuan Liu, Juanzi Li, and Jian Tang. Kepler: A unified model for knowledge embedding and pre-trained language representation. Transactions of the Association for Computational Linguistics, 9:176–194, 2021.
[8] 综述 | 三大路径,一文总览知识图谱融合预训练模型的研究进展. https://mp.weixin.qq.com/s/kuxjRgKnX2bi_BPY_mDgpA
[9] Zhang, Z., Han, X., Liu, Z., Jiang, X., Sun, M., & Liu, Q. (2019). ERNIE: Enhanced language representation with informative entities. arXiv preprint arXiv:1905.07129.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢