
昨天,高性能计算先驱Jack Dongarra获得2021年图灵奖。今天,我们就来讲讲老爷子的研究,日后在AI领域诞生的一个新技术:混合精度训练。
知识点
1.混合精度训练(Mixed-precision Training)指的是在模型训练过程中,同时使用单精度FP32和半精度FP16等多种浮点数精度的方法。
2.混合精度训练能够加快训练时间,减少网络训练所占用的内存,同时可以保持模型精度不变。
3.混合精度训练方法主要有FP32权重备份、损失缩放、精度累加等方法。
定义
在深度学习训练过程中,数据类型默认为单精度FP32。为了加快训练时间,减少网络训练所占用的内存,但同时要保持模型精度不变,越来越多的研究者开始采用混合精度训练的方法。
混合精度训练(Mixed-precision Training)指的是在模型训练过程中,同时使用单精度FP32和半精度FP16等多种浮点数精度的方法。
1.精度是什么?
在计算机领域,“精度”指的是浮点数的表示方式,如半精度(FP16)、单精度(FP32)、双精度(FP64)等。每一种浮点数都有三个不同的位来表示。FP64是8字节64位、FP32是4字节32位、FP16是2字节16位。[2]

怎样表示一个数字?通过如下公式计算即可,其中S表示了正负符号,E表示指数位,fraction/M表示的是分数位。这里需要注意,S、E和M都是由二进制的1或0表示的,尽管它们做代表的含义并不一样。
FP16的表示:
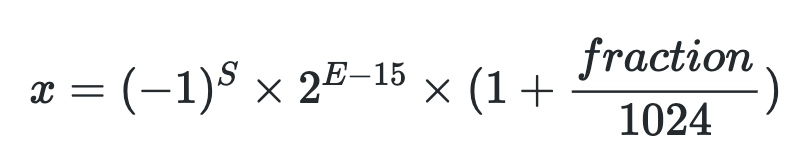 FP32的表示(规则化之后):
FP32的表示(规则化之后):
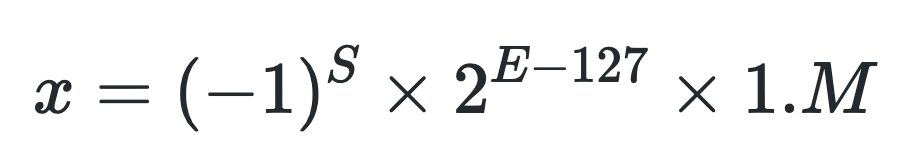
不同精度的浮点数在计算机中的存储空间不同,因此在同等的任务规模下,采用半精度计算的速度比单精度要快。
但是,又由于不同精度的数值表示范围不同,所以更高精度的计算,结果更为精确。
2.混合精度训练的优势和挑战
采用混合精度训练,模型能够[1]:
(1)减少内存占用:FP16的位宽是FP32的一半,权重等参数所占内存也是原有精度下模型的一半,节省的内存可以用于更大规模模型和更多数据的训练;
(2)加快通讯效率:降低数据位宽可以提升通讯性能,减少机器等待的时间;
(3)提升计算效率:在一些加速芯片上,FP16的执行性能比FP32更快。
但采用FP16和FP32的混合精度训练,会带来以下两个问题[1]:
(1)数据溢出:由于FP16的有效数据表示范围远远小于FP32,替换后模型的参数精度收到较大的影响,出现上溢(Overflow)和下溢(Underflow)的问题;
(2)舍入误差:当网络模型的反向梯度很小时,一些FP32能够表示的数值可能不能满足FP16精度下的表示范围,导致被强行舍入,带来误差。
混合精度训练的具体方法
混合精度计算的思路最早由Baboulin等人(其中Dongarra参与)提出[3],当时采用的是FP32和FP64混合精度,用于提升超算中FPGA和GPU的计算性能。在人工智能领域,混合精度训练往往采用的是FP16和FP32精度结合的方法,主要有以下几种方式[4]:
1.FP32权重备份:解决舍入误差问题
保留一份FP32的主权重(Master-Weights),同时在训练中使用FP16存储权重、激活、梯度等数据。在参数更新的过程汇总,用FP16更新FP32的主权重。
![]()
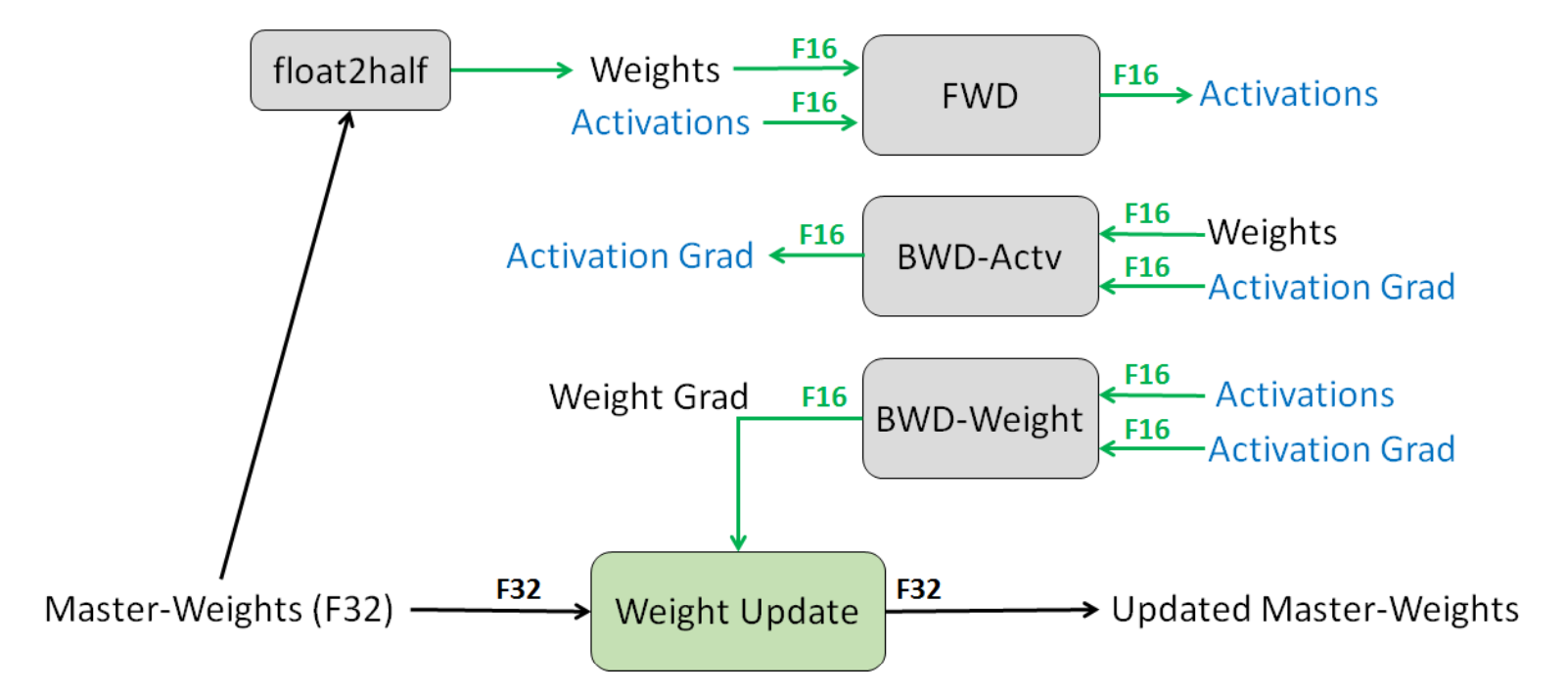 2.损失缩放:解决数据下溢问题
2.损失缩放:解决数据下溢问题
当采用FP16而不是FP32更新梯度时,由于值太小,会造成FP16精度下数据下溢的问题,一些梯度会变为0,导致模型不收敛。
因此,可以在前向计算完成,反向传播开始前进行放大(FP32->FP16)工作,将FP32精度转为FP16。由于链式法则,反向传播会让所有的梯度值都同样程度地方法,所以不需要在反向传播中有额外的计算,也能够防止一些梯度值变为0。而在反向传播完成后,在权重更新前,立刻对权重梯度进行缩小(FP16->FP32),这样可以保证任何超参数不会被影响。
3.精度累加
此外,研究者还发现,可以在模型训练的过程中,使用FP16进行乘法预算,使用FP32进行累加运算,并将FP32转换为FP16存储。FP32可以弥补损失的精度,减少舍入误差。
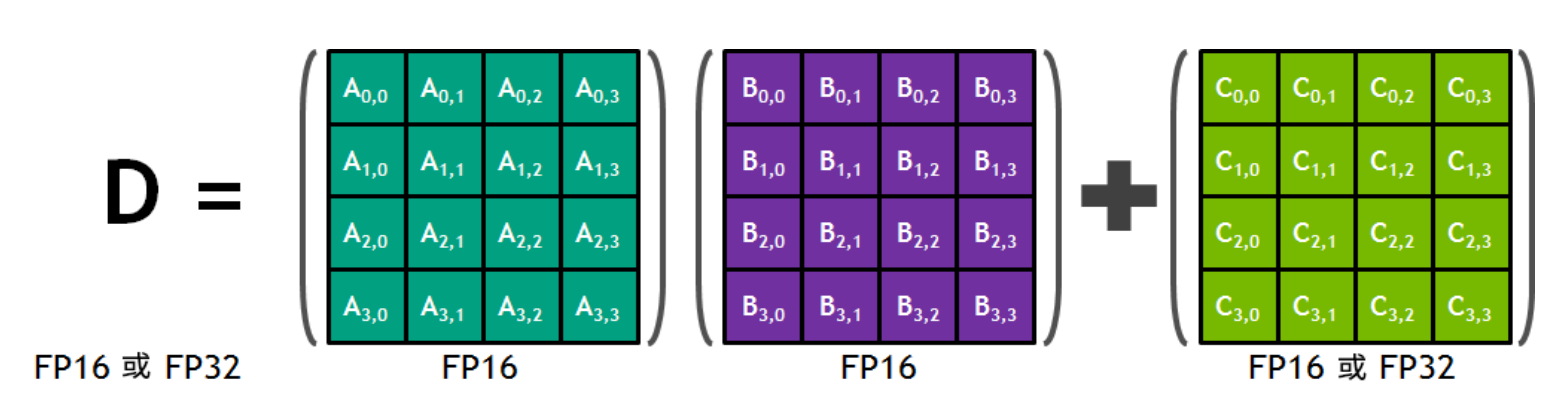
例如,英伟达Volta架构中的Tensor Core可以使用FP16混合精度进行加速,采用的是FP16的矩阵乘法,得出全精度乘积,然后使用FP32累加,将该乘积与其他中间乘积累加,减少因FP16带来的精度损失。
4.更为动态的精度缩放方法
在英伟达最新的Hopper架构GPU中,英伟达的Tensor Core能够自动根据所需的精度进行动态的数据缩放调整,特别是针对Transformer网络架构,能够在数据存入内存前,根据需求改变各种参数精度。
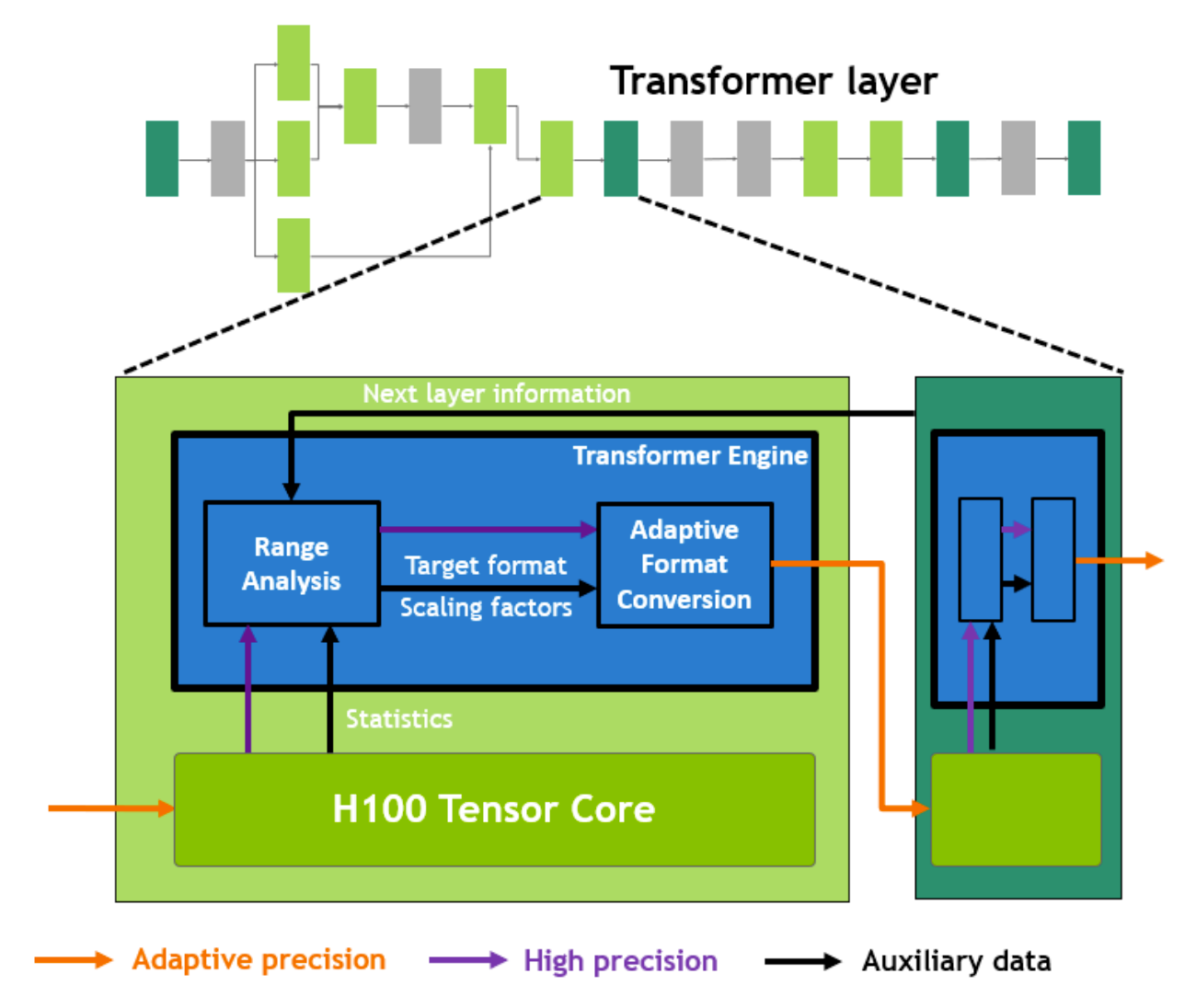
Hopper白皮书内容如下[6]:
在 Transformer 模型的每一层,Transformer Engine 都会分析 Tensor Core 产生的输出值的统计数据。了解了接下来会出现哪种类型的神经网络层以及它需要什么精度后,Transformer Engine 还会决定将张量转换为哪种目标格式,然后再将其存储到内存中。 FP8 的范围比其他数字格式更有限。为了优化使用可用范围,Transformer Engine 还使用从张量统计数据计算的缩放因子动态地将张量数据缩放到可表示的范围内。因此,每一层都在其所需的范围内运行,并以最佳方式加速。
参考链接
[1] 混合精度训练原理总结:https://bbs.cvmart.net/articles/5858
[2] IEEE 754:https://en.wikipedia.org/wiki/IEEE_754
[3] Baboulin, M., Buttari, A., Dongarra, J., Kurzak, J., Langou, J., Langou, J., ... & Tomov, S. (2009). Accelerating scientific computations with mixed precision algorithms. Computer Physics Communications, 180(12), 2526-2533.
[4] Micikevicius, P., Narang, S., Alben, J., Diamos, G., Elsen, E., Garcia, D., ... & Wu, H. (2017). Mixed precision training. arXiv preprint arXiv:1710.03740.
[5] NVIDIA TESLA V100 GPU 白皮书:https://www.nvidia.cn/content/dam/en-zz/zh_cn/Solutions/Data-Center/volta-gpu-architecture/Volta-Architecture-Whitepaper-v1.1-CN.compressed.pdf
[6] NVIDIA H100 Tensor Core GPU Architecture:https://nvdam.widen.net/s/9bz6dw7dqr/gtc22-whitepaper-hopper
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢