
作者:AI小将 来源:微信公众号@机器学习算法工程师
近日,MetaAI大佬团队(何恺明)发布了新的研究论文:Exploring Plain Vision Transformer Backbones for Object Detection,这篇论文提出了基于纯粹的ViT作为检测Backbone的模型ViTDet,效果可以匹敌基于金字塔结构的Backbone!

论文:https://arxiv.org/abs/2203.16527
这篇论文研究了普通的、非分层的视觉转换器(ViT)作为对象检测的骨干网络。这种设计使原始的 ViT 架构可以针对目标检测进行微调,而无需重新设计用于预训练的分层主干。和微调的最小适应,我们的普通骨干检测器可取得有竞争力的性能。令人惊讶的是,可以得到如下结论:
-
足以从单尺度特征图构建一个简单的特征金字塔(没有
常见的 FPN 设计; -
使用窗口注意力就足够了(不移动窗口),而只需要很少的跨窗口传播块的辅助。
如果用无监督学习方法Masked Autoencoders (MAE)预训练ViT,ViTDet可以匹敌与之前基于分层主干的方法,仅使用 ImageNet-1K 预训练就可以在 COCO 数据集上达到61.3 AP box。代码将会开源!

ViTDet只使用ViT的最后的1/16特征,而区别之前的层级Backbone+FPN,只需要对1/16特征做简单的上采样(stride>1卷积)或者下采样(stride>1反卷积)就能够得到多尺度特征:1/4,1/8, 1/16和1/32大小特征:
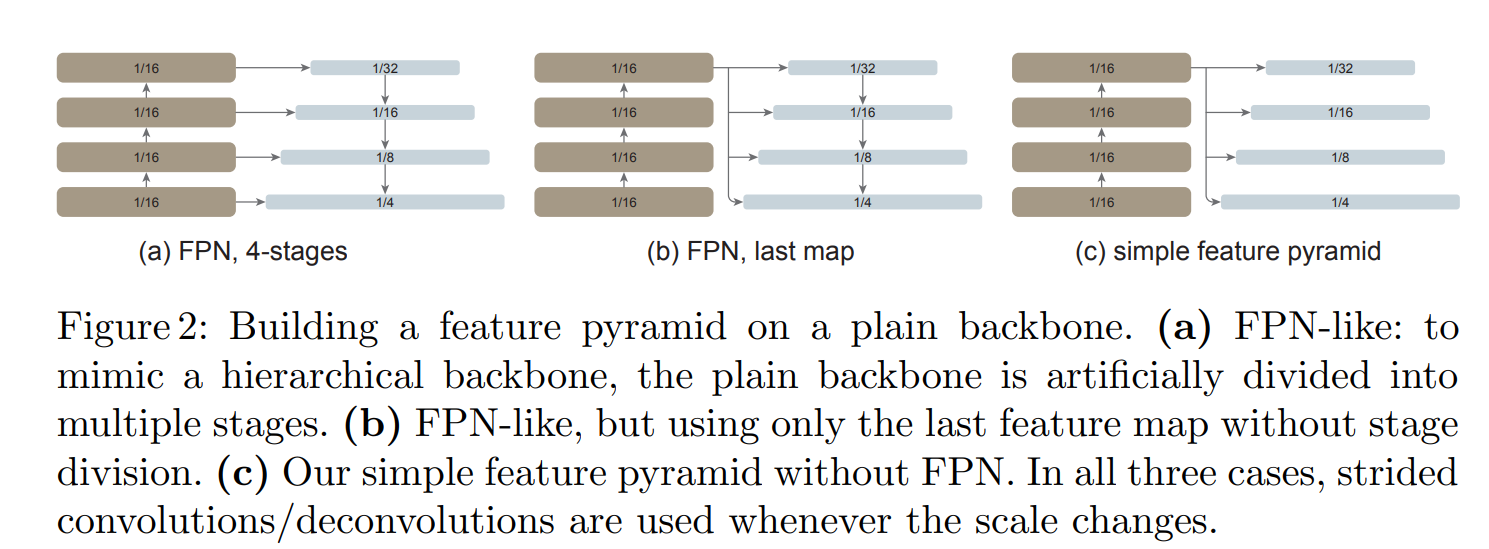
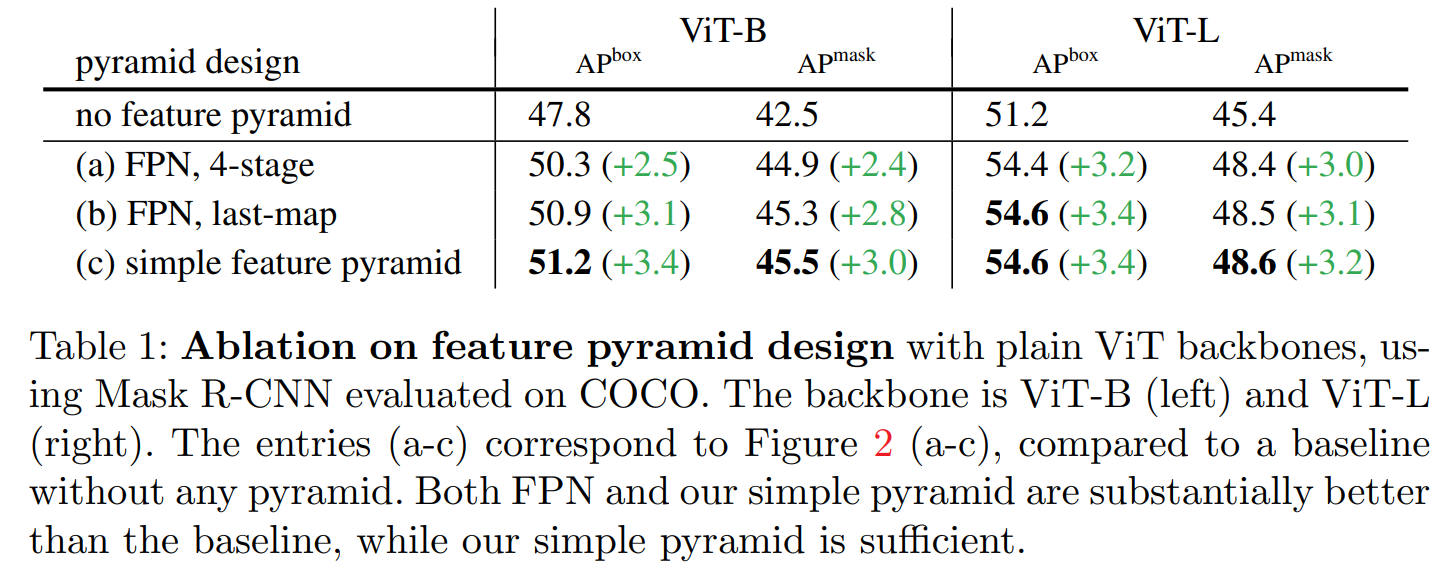
这种设计要比其它复杂的FPN设计效果要更好:
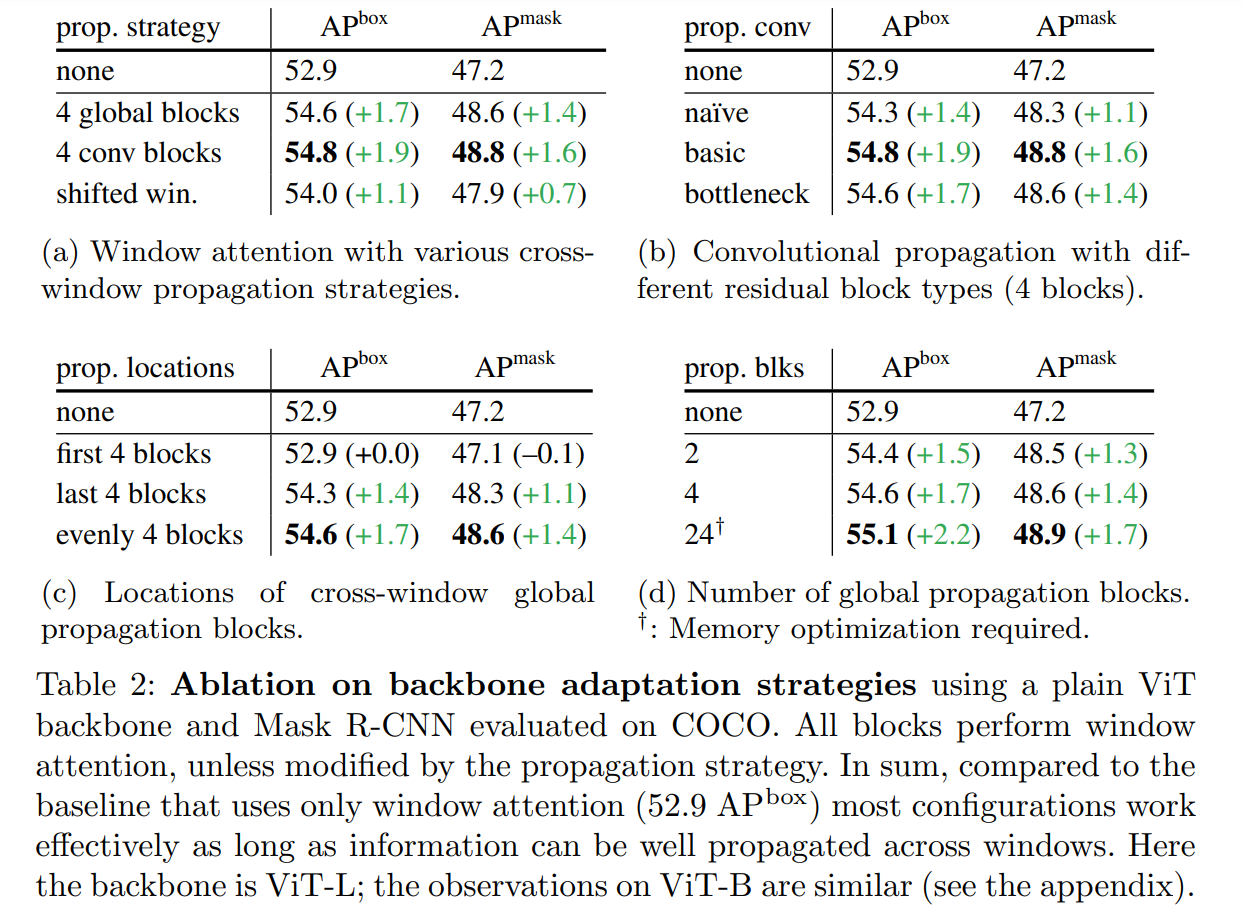
ViTDet的第二个设计是采用window attention提升计算效率,然后在ViT的均分4个位置加上一个cross-window策略,可以适用全局attention或者卷积block,对比效果如下所示,均比shifted window效果要好:
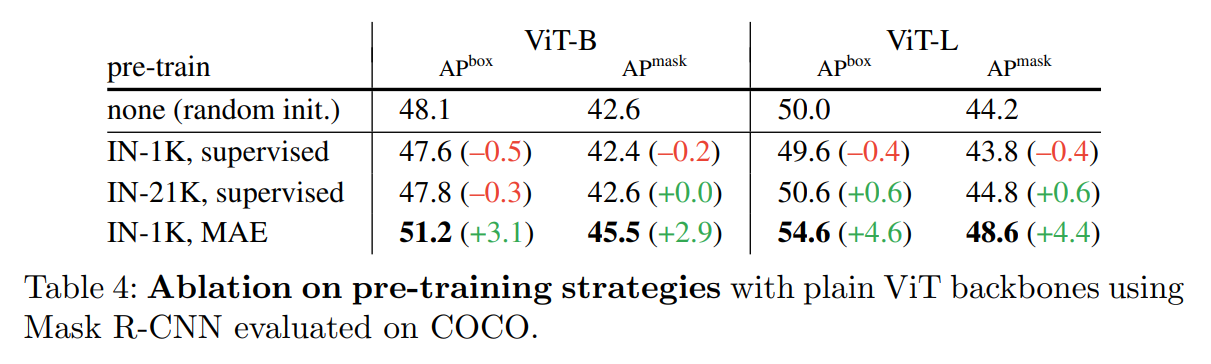
另外一个点是采用MAE来预训练模型,效果有进一步增强:
在效果上,ViTDet可以超过基于层级的backbone(如Swin):
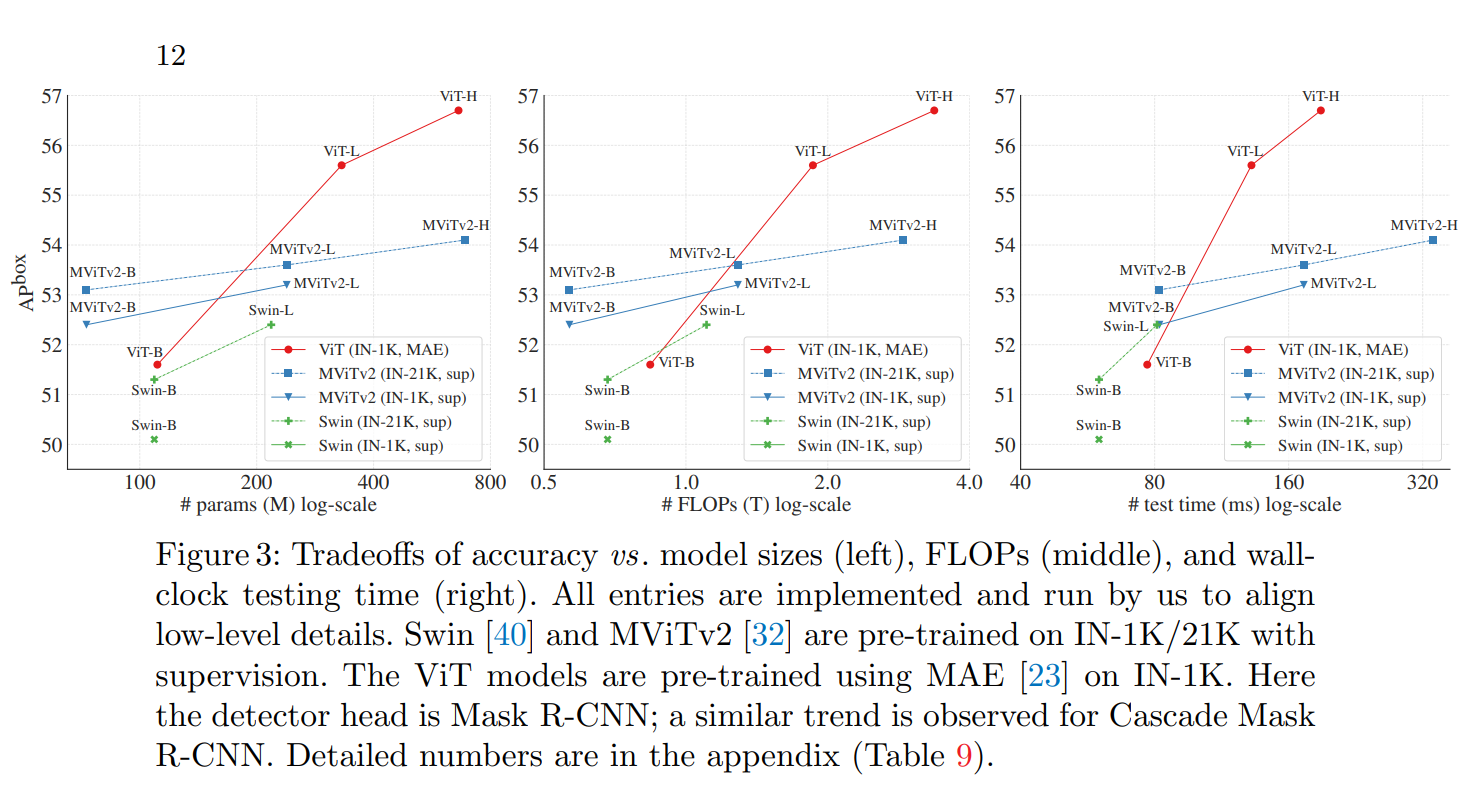
更多细节,详见论文:https://arxiv.org/abs/2203.16527
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢