
论文标题:MatteFormer: Transformer-Based Image Matting via Prior-Tokens
论文链接:https://arxiv.org/abs/2203.15662
作者单位:首尔大学 & NAVER
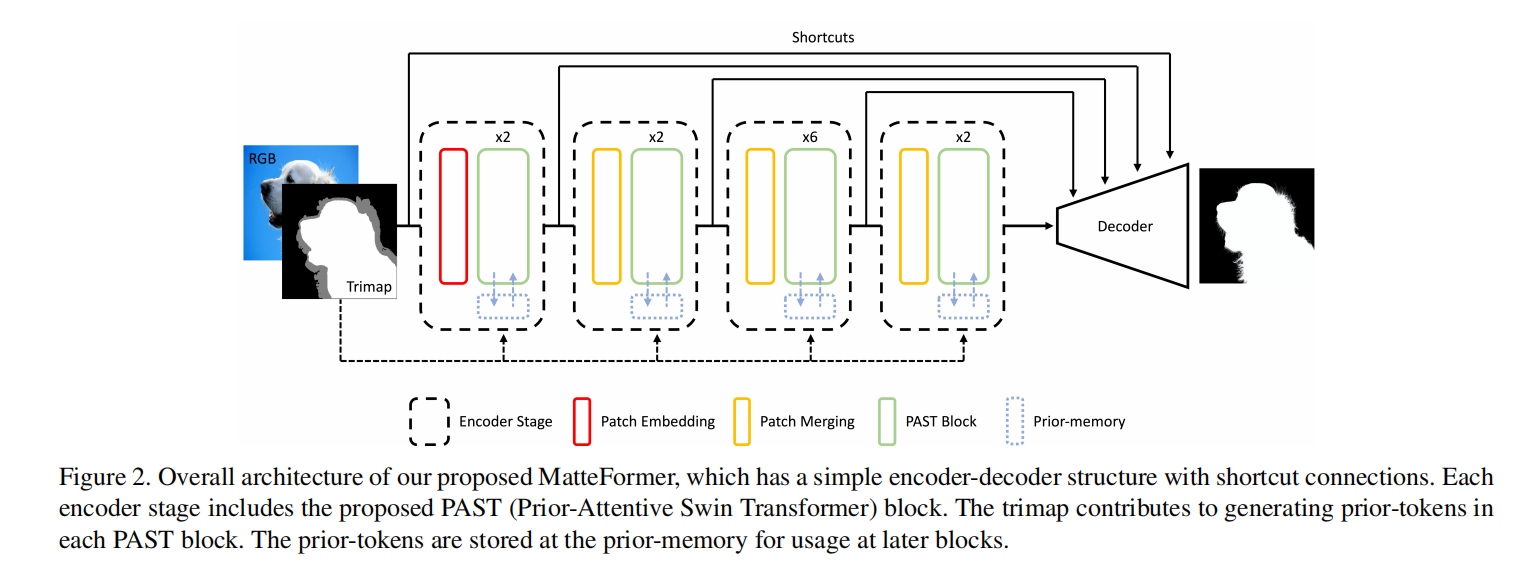
在本文中,我们提出了一种基于Transformer的图像抠图模型,称为 MatteFormer,它充分利用了Transformer块中的 trimap 信息。我们的方法首先引入了一个先验标记,它是每个 trimap 区域的全局表示(例如前景、背景和未知)。这些先验令牌用作全局先验,并参与每个块的自注意力机制。编码器的每个阶段都由 PAST(Prior-Attentive Swin Transformer)块组成,该块基于 Swin Transformer 块,但在几个方面有所不同:1)它具有 PA-WSA(Prior-Attentive Window Self -Attention) 层,不仅使用空间标记,还使用先验标记执行自我注意。 2)它具有先验内存,可以从先前的块中累积保存先验令牌并将它们转移到下一个块。我们在常用的图像抠图数据集上评估我们的 MatteFormer:Composition-1k 和 Distinctions-646。实验结果表明,我们提出的方法以较大的优势实现了最先进的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢