

论文链接:https://arxiv.org/pdf/2203.13278v2.pdf
代码链接:https://github.com/cszn/scunet
导读
尽管近年来利用深度神经网络解决图像去噪任务取得了显著的成功,但现有方法大多依赖简单的噪声假设,例如加性高斯白噪声、JPEG压缩噪声、相机传感器噪声等,这使得面向真实图像的通用盲去噪任务性能欠佳。在本文中,作者视图从网络结构设计、训练数据合成的角度来解决这一问题。具体来说,对于网络架构,本文提出了一整个Swin-Conv模块来结合卷积的局部建模能力和Transformer的全局建模能力,这一模块作为一种即插即用式的改进可以直接结合到UNet架构中来。而对于训练数据合成,作者设计了一个实际的噪声退化模型,该模型将多种不同的噪声种类进行了综合考量,并引入了随机打乱和双退化策略。大量实验表明,新的网络架构设计实现了最先进的性能,新的退化模型有助于显着提高实用性。
贡献
图像去噪,即从噪声图像Y中恢复干净图像X,可能是计算机视觉中最基本的图像处理任务。这一过程可以用形式化方法定义如下:
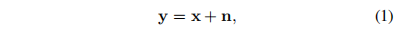
其中n为需要去除的噪声。近年来,深度神经网络已成为图像去噪的主流方法。为了提高深度神经网络的去噪性能,研究人员主要关注两个研究方向:一是在假设n是加性高斯白噪声(AWGN)的情况下提高性能,二是在训练数据或噪声建模上进行创新,这两个研究方向都以提高真实噪声图像的复原心性能为最终目标。
噪声n的常见类型有加性高斯白噪声AWGN、JPEG压缩噪声、泊松噪声和摄像机传感器噪声,其中AWGN由于其数学上的方便性,是应用最广泛的一种。然而,由于噪声假设的单一局限性,由AWGN训练的深度图像去噪模型对大多数真实图像表现不佳,但去除AWGN对于测试不同网络架构设计的有效性具有较大的参考价值。近年来,人们提出了各种网络架构设计,例如DnCNN、NLRN、DRUNet、SwinIR。然而,高级网络架构设计能否进一步提高PSNR的性能仍然是一个有趣的问题(it is still interesting to raise the first question whether the PSNR performance can be further improved by advanced network architecture design)。为了促进深度去噪模型的实用性,噪声建模已经出现了一系列的工作,它们背后的动机是为了使噪声假设与真实图像的情况尽可能一致。然而,关于训练通用盲图像去噪的深度模型的工作还很少,即如何改进盲去噪模型的训练数据。
针对这两个问题,本文展开了相关研究。对于网络架构设计,作者提出了如下动机:1)不同的图像去噪方法具有互补的图像先验建模能力,并且可以结合起来提高性能; 2) DRUNet 和SwinIR利用不同的网络架构设计,同时实现了非常有希望的去噪性能。并在此基础上提出了一个 swin-conv 块来结合残差卷积层的局部建模能力和Swin Transformer的全局建模能力,并将其作为主要模块插入 UNet 架构。作者进一步提出了一种随机扰动的噪声(包括高斯噪声、泊松噪声、散斑、JPEG压缩和处理过的摄像机传感器噪声)和调整操作(包括常用的双线性和双边插值),以尽可能地逼近真实图像噪声。
本文的贡献可以总结如下:
- 提出了一种新的去噪网络,将新的Swin-Conv模块插入到多尺度UNet中,以提高局部和非局部建模能力;
- 提出了一个手工设计的噪声合成模型,它可以用来训练一个通用的盲图像去噪模型;
- 利用噪声合成模型训练的盲去噪模型可以显著提高真实图像去噪的实用性。
方法
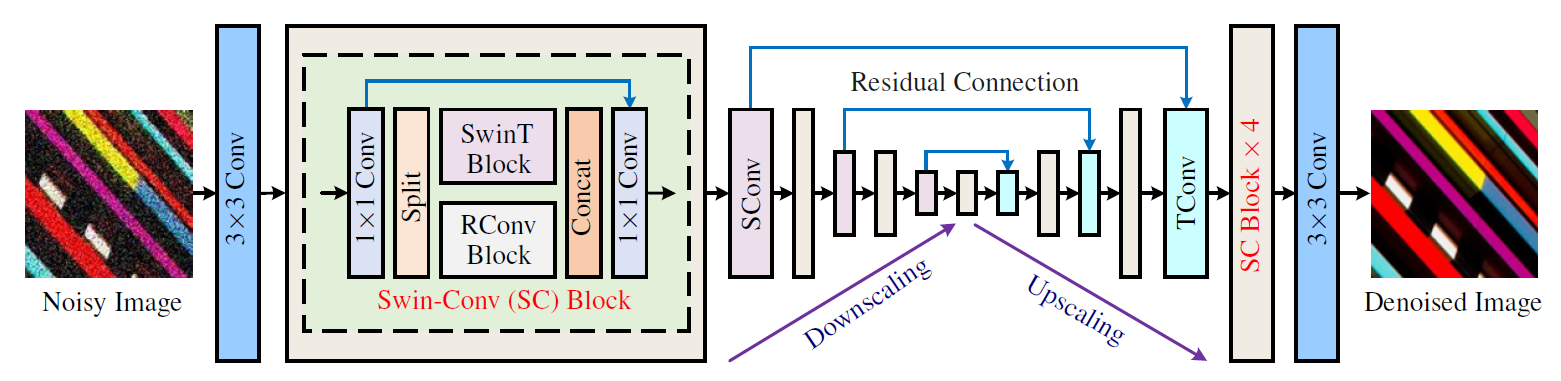
本文所提出的 Swin-Conv-UNet (SCUNet) 架构如上图。 SCUNet 利用 swin-conv (SC) 块作为 UNet 主干的主要构建块。
在每个 SC 块中,输入X首先通过 1×1 卷积,随后被均匀地分成两个特征图X1、X2:

然后将两个特征图分别输入 swin 变换器(SwinT)块和残差 3×3 卷积(RConv ) 块:
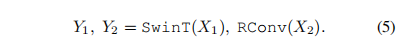
之后,将 SwinT 块和 RConv 块的输出拼接起来,然后通过 1×1 卷积以产生输入的残差图像:

值得指出的是,本文提出的SCUNet由于一些新颖的模块设计而具有一些优点:
- SC块融合了RConv块的局部建模能力和SwinT块的非局部建模能力;
- 通过多尺度UNet进一步增强了SCUNet的局部和非局部建模能力;
- 1×1卷积可以有效地促进SwinT块和RConv块之间的信息融合;
- 分割和连接操作可以作为与两组的组卷积,以降低计算复杂度和参数的数量。
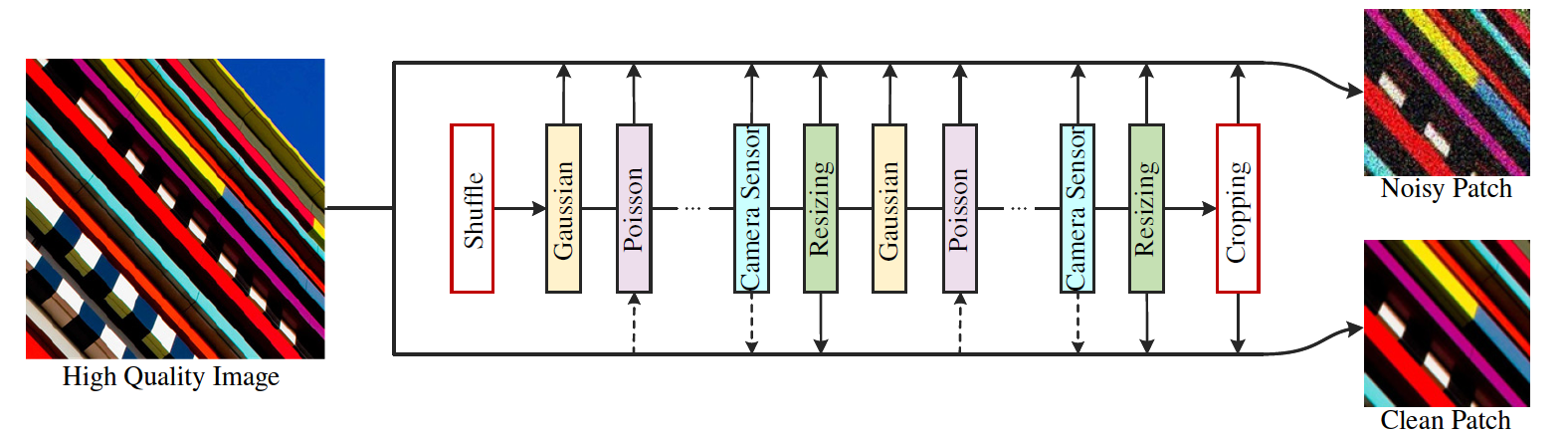
本文没有建立大量真实的噪声/干净的图像对,而是尝试合成真实的噪声/干净的图像对。如上图所示,上述目的主要通过添加不同类型的噪声,还包括调整大小,以及合并双重退化策略和随机洗牌策略。
对于高质量图像,首先执行随机打乱的退化序列以产生噪声图像。同时,利用调整大小和反向调映射以产生相应的干净图像。 然后裁剪成对的噪声/干净的训练补丁,用于训练深度盲去噪模型。
上述训练数据合成策略至少在三个主要方面与[51,55]中提出的管道有所不同。
- 首先,应用场景不同,上述策略用于深盲图像去噪,而在[51,55]中提出的策略是用于盲超分辨率设计的;
- 其次,上述策略还对高质量图像进行调整,以产生噪声图像的干净图像,而[51,55]中的退化模型不执行这样的过程;
- 第三,上述策略采用了更多种类的噪声,如散斑噪声(speckle noise)。

可以看出,上述训练数据合成策略可以产生非常真实的噪声图像。值得注意的是,噪声/干净的图像块对来自相同的高质量图像,大小为544×544。由于对干净的图像块也执行大小调整操作,所以可以从一些干净的图像块中观察到模糊现象。
实验
为了公平起见,本文首先在Set12,,BSD68,Urban100等合成高斯去噪数据集上评估了SCUNet的性能。然后,评估了本文提出的训练数据合成策略与SCUNet在真实图像上的盲去噪效果。
灰度图高斯去噪
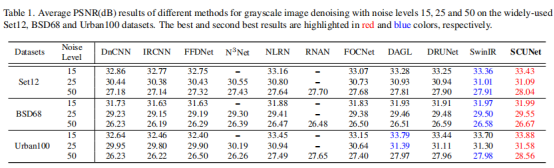
表1展示了在广泛使用的Set12、BSD68、Urban100数据集上对噪声水平15、25、50的PSNR指标结果。可以注意到,N3Net、NLRN、RNAN和SwinIR明确地采用了非局部模块设计以捕获非局部图像,从而获得更好的去噪性能。可以看出,SCUNet在三个数据集上的所有噪声水平上都取得了比其他方法更好的PSNR结果。

为了定性地评价本文所提出的SCUNet,作者在图4中提供了噪声水平为50时,经典图像“Barbara”上的去噪结果。
彩色图高斯去噪
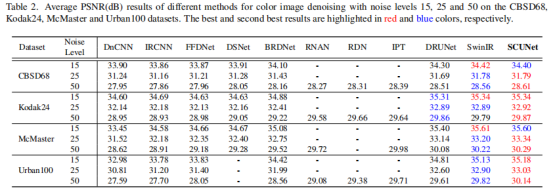
表2报告了不同方法在CBSD68、Kodak24、McMaster和Urban100数据集上的彩色图像去噪结果。比较的方法包括DnCNN、IRCNN、FFDNet、DSNet、BRDNet、RNAN、RDN、IPT、DRUNet和SwinIR。正如可以看到的,SCUNet产生了最好的整体性能。
真实图像去噪
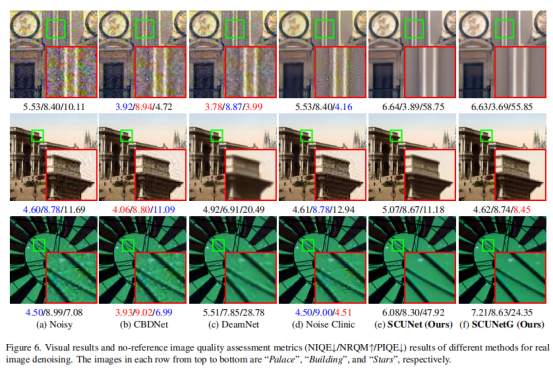
图6提供了对真实图像去噪的不同盲去噪方法的可视化结果。
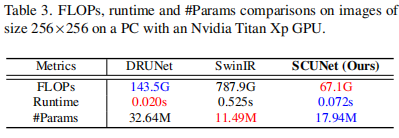
表3中报告了DRUNet、SwinIR和SCUNet之间的flop、运行时间和参数大小的比较。可以看到,由于UNet和SC块的组合,SCUNet实现了最低的计算消耗。

图7提供了更多SCUNet和SCUNetG对来自RNI15数据集的真实图像的盲去噪结果。与图6不同,模型并不知道图7中这些真实图像的噪声类型和噪声水平。根据以上结果,作者得出结论,本文所提出的训练数据合成策略适用于训练实际应用中的深度盲去噪模型。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢