
【标题】Mask Atari for Deep Reinforcement Learning as POMDP Benchmarks
【作者团队】Yang Shao, Quan Kong, Tadayuki Matsumura, Taiki Fuji, Kiyoto Ito, Hiroyuki Mizuno
【发表日期】2022.3.31
【论文链接】https://arxiv.org/pdf/2203.16777.pdf
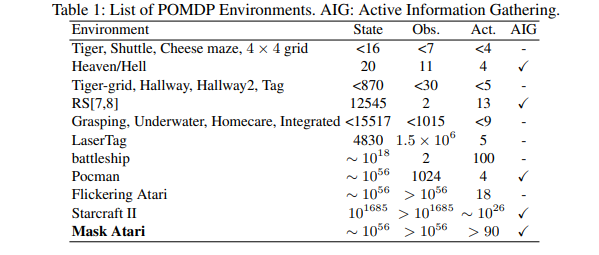
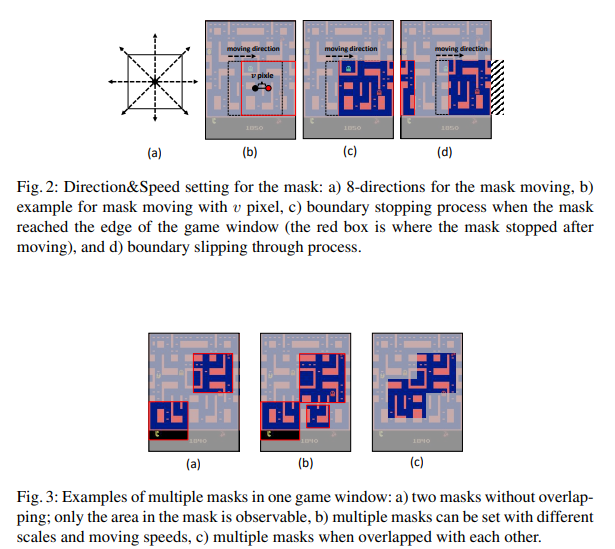
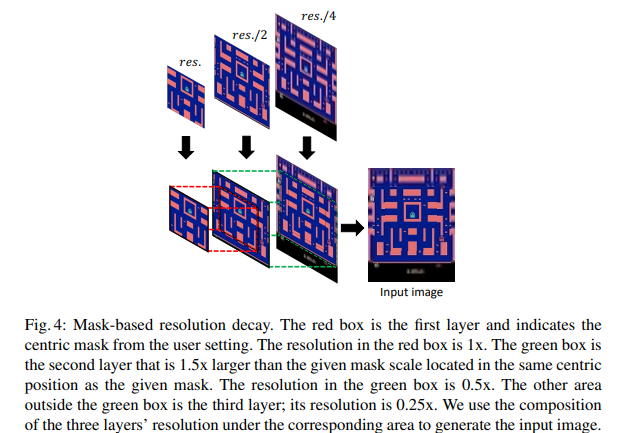
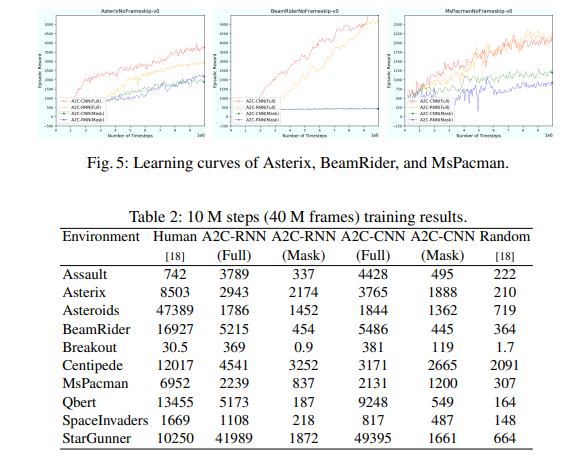
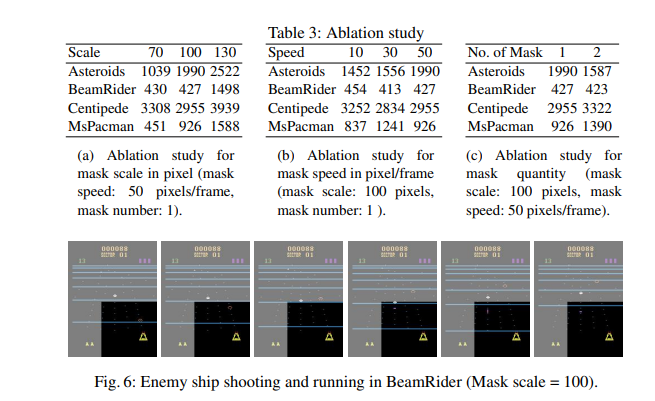
【推荐理由】本文提出了 Mask Atari,一个新的基准,可帮助使用基于深度强化学习 (DRL) 的方法解决部分可观察的马尔可夫决策过程 (POMDP) 问题。为了实现 POMDP 问题的模拟环境,Mask Atari 是基于 Atari 2600 游戏构建的,具有可控、可移动和可学习的掩码作为目标代理的观察区域,特别是 POMDP 中的主动信息收集 (AIG) 设置。鉴于尚不存在,Mask Atari 提供了一个具有挑战性的、有效的基准来评估专注于上述问题的方法。此外,掩码操作是将人类视觉系统中的感受野引入代理的模拟环境的试验,这意味着与人类基线相比,评估不会偏向于感知能力,而是纯粹关注方法的认知性能。通过描述该基准测试的挑战和特点,并使用 Mask Atari 评估了几个基准。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢