

论文:https://arxiv.org/pdf/2203.01152.pdf
导读
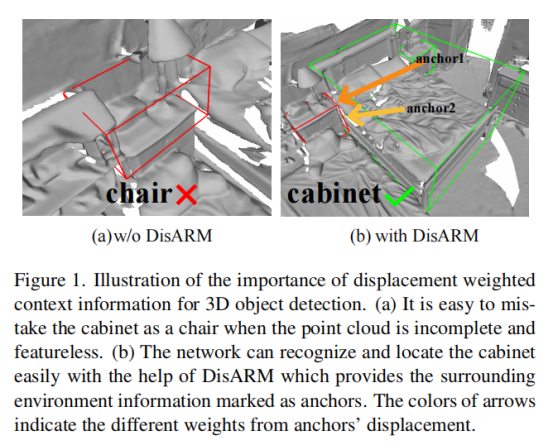
本文介绍了位移感知关系模块 (DisARM),即一种新颖的神经网络模块用于提高点云场景中 3D 对象检测的性能。DisARM的核心思想是,当实例几何信息不完整或无特征时,上下文信息对于区分实例间的差异至关重要。作者发现实例Proposal之间的关系提供了一个很好的上下文表示。然而,采用所有对象或实例Proposal之间的关系进行检测是低效的,并且局部和全局关系的不平衡会带来额外的噪声,最终可能会误导训练。因此,作者提出仅使用最具代表性的关系或锚点之间的关系进行训练可以显着提高检测性能,而不是使用所有关系。最具代表性的锚点应该是语义感知的,其语义信息没有歧义且独立于其他锚点。为了找到最具代表性的锚点,DisARM首先使用对象感知采样方法与关系锚点模块,然后利用一个基于位移的模块来衡量关系的重要性,以便更好地利用上下文信息。当DisARM插入最先进的检测器时,上述轻量级的关系模块可以显着提高对象实例检测的准确性。对真实场景公共基准的实验结果表明,DisARM在 SUN RGB-D 和 ScanNet V2 上均达到了最先进的性能。
贡献
3D目标检测中一个重要的难点问题是对不完整目标、噪声目标的检测。尽管已有研究提出了多种方法解决这一难点问题,但它们在检测精度和检测效率上仍存在一定的局限性。
为此,本文提出上下文信息的融合是三维理解的关键,可以提高目标检测性能。因此提升3D检测模型的重点就是如何利用上下文信息来提高检测性能。同时为了避免冗余的关系特征对训练的误导和提取重要的信息,需要从两个方面选择和收集最关键的上下文。
为此,作者首先引入了一个关系锚点模块,它仅通过特征空间上感知对象的最远特征点(FPS)将最具代表性和信息量最大的实例Proposal作为锚点进行采样。 这种设计的动机是上下文编码的关系锚应该在特征空间上均匀分布,同时完整和干净。文中实验表明,采用这些关系锚点而不是整个实例关系集进行上下文融合更加有效和准确。 为了最大限度地利用所提出的关系锚点,作者还引入了一种取决于空间和特征位移的动态加权机制。其关键动机是每个锚点的重要性在识别不同对象方面应该是不同的,由于实例位置通常与室内场景的一些特定组织模式相结合,其重要性应取决于实例与锚点之间的空间布局和语义关系。
本文的主要贡献可以总结如下:
- 提出了一种轻量级神经网络模块DisARM,它可以与现有的三维目标检测方法结合以进一步提高检测性能,可以很容易地嵌入广泛使用的目标检测工具箱,如MMtesecy3D;
- 介绍了一种将三维上下文描述为一组加权的代表性锚点的方法。该方法可以有效地从复杂场景中的冗余关系中提取有效的信息;
- DisARM简单但有效,在 ScanNet V2 上实现了最先进的性能,在 SUN RGB-D 上实现了最先进的性能(mAP@0.25)。
方法
本文提出了一种便携式网络模块DisARM以有效地利用3D上下文,它可以很容易地与现有的目标检测方法组合在一起,以提高性能。
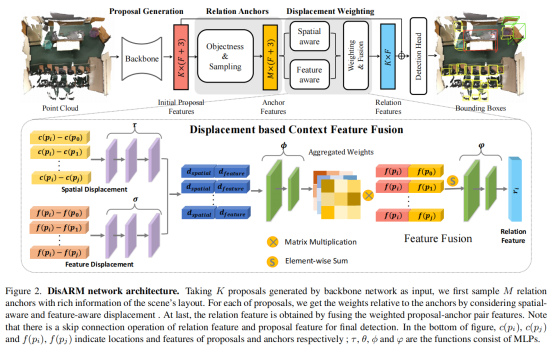
作者认为在室内场景中检测有用的上下文信息需要满足两个条件:1)可以反映物体之间的内在关系,2)可以隐含地代表整个场景的布局。因此,本文提出了一种双向网络框架来有效地提取上下文信息。如下图所示,DisARM的前一个模块对每个潜在目标提议学习到的深度特征之间的关系锚进行采样,后一个模块对每个提议在锚之间的相对位移进行编码场景布局。更具体地说,前者的核心是定位最具代表性和信息量最大的关系特征构造proposals,我们将这些选定的建议表示为锚点,后面的模块通过分析空间位移和特征位移来计算每个锚的权重,实验表明,本文提出的框架能够有效地提取用于三维目标检测的上下文,并且与其他现有框架相比,该框架的性能有显著提高。
Relation anchors
Initial proposals采用VoteNet作为Backbone,产生proposals作为DisARM模块的输入。每个proposal都用它的中心点表示,Initial proposals特征编码器网络具有多层感知功能(MLP)层和具有跳过连接的特征传播层。输出特征f(pi)是一个F维向量,它是对支持proposals pi的每一实例所学习到的深度特征的集合。
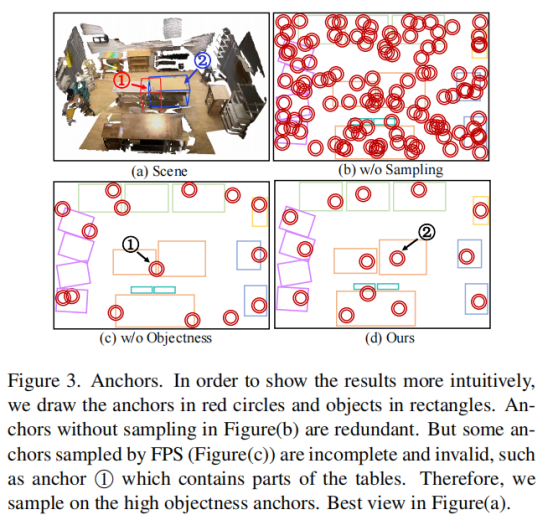
Proposal object如图3所示,proposals的整个集合在某种程度上是冗余的,并且包含大量不完整和无效的proposals ,考虑场景中所有可能的关系来构建上下文特征是无效的,可能会引入过多的噪声信息。因此,设计有效利用这些关系的机制的关键是找到最具代表性和信息量最大的关系。图3只展示了Backbone给出的少数proposals 是完整的。DisARM引入objectness的概念来过滤不完整和有噪声的信息。
给定一个proposals pi及其对应的特征f(pi),其objectness表示为o(pi)。计算objectness的网络模块是一个具有全连接层、sigmoid激活和批量归一化的简单MPL网络。因为大多数数据集只将标注了场景中的有效对象的真值,将objectness损失定义如下:
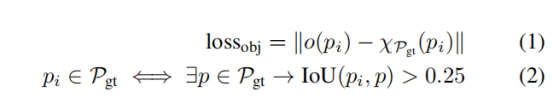
其中,χPgt(pi)为指示函数。如图3所示,o(pi)可以表示给定提案的完整性,这对于定位提案锚点至关重要。
Displacement based context feature fusion
Spatial displacement 该proposal anchors可以有效地描述整个输入场景的上下文。然而,他们对不同目标的检测贡献不应该是相等的,如下图所示:
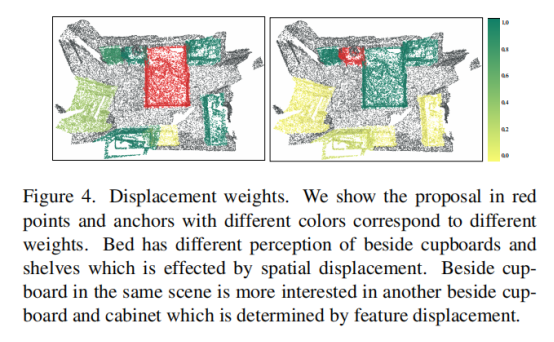
空间布局模式可以有效地描述室内场景中具有代表性的子结构。因此,作者认为检测的上下文信息也应该根据布局感知的空间位移分配权重。
对于不同的空间布局移,一个物体对不同的建议锚有不同的感知。例如,橱柜通常放在床的旁边,椅子通常放在书桌或桌子的前面。这些模式可以通过建议锚对之间的空间布局来反映。因此,本文将提案周围不同位移的重要性视为位移权重,从而鼓励网络给予不同程度的关注。具体来说,给定位置c(pi)的目标提案pi和位置c(pj)的提案锚点pj:
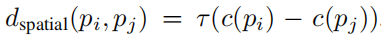
Feature displacement 与空间位移类似,在度量提议锚对的重要性时,也要考虑目标提议锚对pi和提议锚对pj给出的特征位移f(pi)−f(pj)。这里的重点是,布局模式有时是语义感知的。例如,浴缸的存在总是表示场景中的脸盆。这个特征可以通过预先编码的特征f(pi)和f(pj)反映出来,因为具有相似语义标签的对象在特征空间上也很接近,反之亦然。因此,给定目标建议pi,pj,它们之间的特征位移权重表示为dfeature(pi, pj) = σ(f(pi)−f(pj)),其中σ是MLP网络给出的感知函数。
Aggregated weights 将空间位移权值dspatial(pi, pj)和特征位移权重dfeature(pi)concatenate起来,将感知到的信息融合在一起,然后将它们放入如图2所示的MLP网络中。我们可以得到如下的最终汇总权重:

其中φ是由多个MLP层启用的感知功能。为了进一步归一化Panchor中pi与所有锚点之间的权值,最后采用softmax函数。
最后,将用于检测的目标建议pi的融合关系特征ri表述如下:
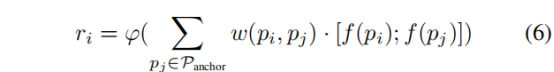
但很明显,训练f(·)、w(·)与寻找最优P anchor高度相关,是一个具有挑战性的优化问题,本文提出了一个3阶段框架来寻找最优的ri,在热身阶段,将w(pi,pj)设为非活动状态,提出的模块专注于定位最优P anchor和训练f(pi)。这个设计的重点是w(pi, pj)只有在网络已经能够提取出一些合理的提案锚点的情况下才具有功能性,下一阶段,我们冻结Panchor和f(pi)来优化w(pi)pj)。本设计将充分利用从现场提取的布局信息来衡量锚的重要性。在这两个阶段之后,w(pj, pj), Panchor和f(pi)一起进行微调,最终达到最优。
实验
由于DisARM可以应用于多种骨干网络,因此实验阶段本文简要描述了基于VoteNet的实现。本文在两个广泛使用的3D目标检测数据集上评估方法:ScanNetV2和SUNRGB-D。
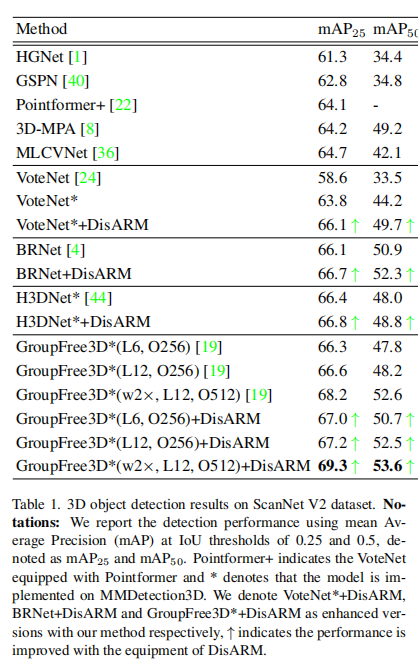
在ScanNet V2数据集上的指标对比结果如下,为了全面对比,作者还在图5中绘制了使用DisARM的不同方法的PR曲线。

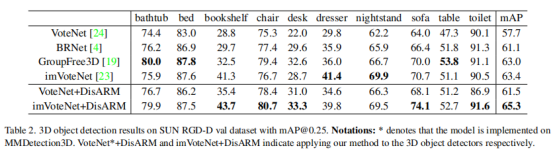
在SUN RGB-D数据集是哪个的对比结果如下表所示,基于VoteNet上DisARM的方法在mAP比VoteNet在mAP@0.25超越了2.4,在mAP@0.5上取得了5.5的性能提升。
作者最后展示了检测结果的视觉效果对比,这些结果表明,将DisARM应用于基线检测器可以获得更可靠的边界盒和方向更准确的检测结果。与基线方法相比,DisARM还消除了假阳性,并发现了更多缺失的对象。

参考资料
- DisARM: Displacement Aware Relation Module for 3D Detection
- https://zhuanlan.zhihu.com/p/490441536
- Dense Voxel Fusion for 3D Object Detection
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢