

论文链接:
https://storage.googleapis.com/pathways-language-model/PaLM-paper.pdf
论文PDF多达83页,作者阵容光看数量也很惊人,14行……作者之一Liam Fedus在Twitter上说,这个项目跨了多个部门(基础架构、数据、硬件等),搞了1年多。
最前面三位作者是主要贡献者:
- Aakanksha Chowdhery(LinkedIn), IIT德里本科,斯坦福大学硕博(2012年毕业),曾在微软和普林斯顿工作数年,2018年加入Google。她也是Pathways论文的第二作者,系统的主要实现者之一。
- Sharan Narang (LinkedIn),孟买大学本科,佐治亚理工硕士(2009年毕业),曾在NVidia和百度工作,2018年加入Google。
- Jacob Devlin(LinkedIn),是的,就是那位非常低调的BERT之父。马里兰大学硕士(2013年毕业),2017年从微软加入Google没多久就发了BERT论文,现在引用数达到可怕的3.6万多次。
此外,作者团队里也有之前在OpenAI任工程副总的David Luan,他也是项目最初发起者之一。
除了强大的Pathways系统之外,训练使用了高质量7800亿token的数据集,其中有一定比例的非英文多语种语料。
论文摘要
大型语言模型已被证明可以在使用小样本学习的各种自然语言任务中实现卓越的性能,这大大减少了使模型适应特定应用所需的特定任务训练示例的数量。为了进一步了解规模对小样本学习的影响,我们训练了一个 5400 亿参数、密集激活的 Transformer 语言模型,我们称之为 Pathways 语言模型 (PaLM)。
我们使用 Pathways 在 6144 TPU v4 芯片上训练 PaLM,Pathways是一种新的机器学习系统,可以跨多个 TPU Pod 进行高效训练。我们通过在数百个语言理解和生成基准上实现最先进的小样本学习结果来展示模型规模扩大的持续优势。在其中的许多任务中,PaLM 540B 取得了突破性的表现,在一套多步推理任务中超越了最先进的微调技术,并在最近发布的 BIG-bench 基准测试中超越了人类的平均表现。大量 BIG-bench 任务显示出模型规模的不连续改进,这意味着随着我们扩展到最大的模型,性能急剧提高。 PaLM 在多语言任务和源代码生成方面也具有强大的能力,我们在广泛的基准测试中展示了这些能力。我们还提供了对偏见和毒性的全面分析,并研究了训练数据记忆与模型规模相关的程度。最后,我们讨论了与大型语言模型相关的伦理问题,并讨论了潜在的缓解策略。
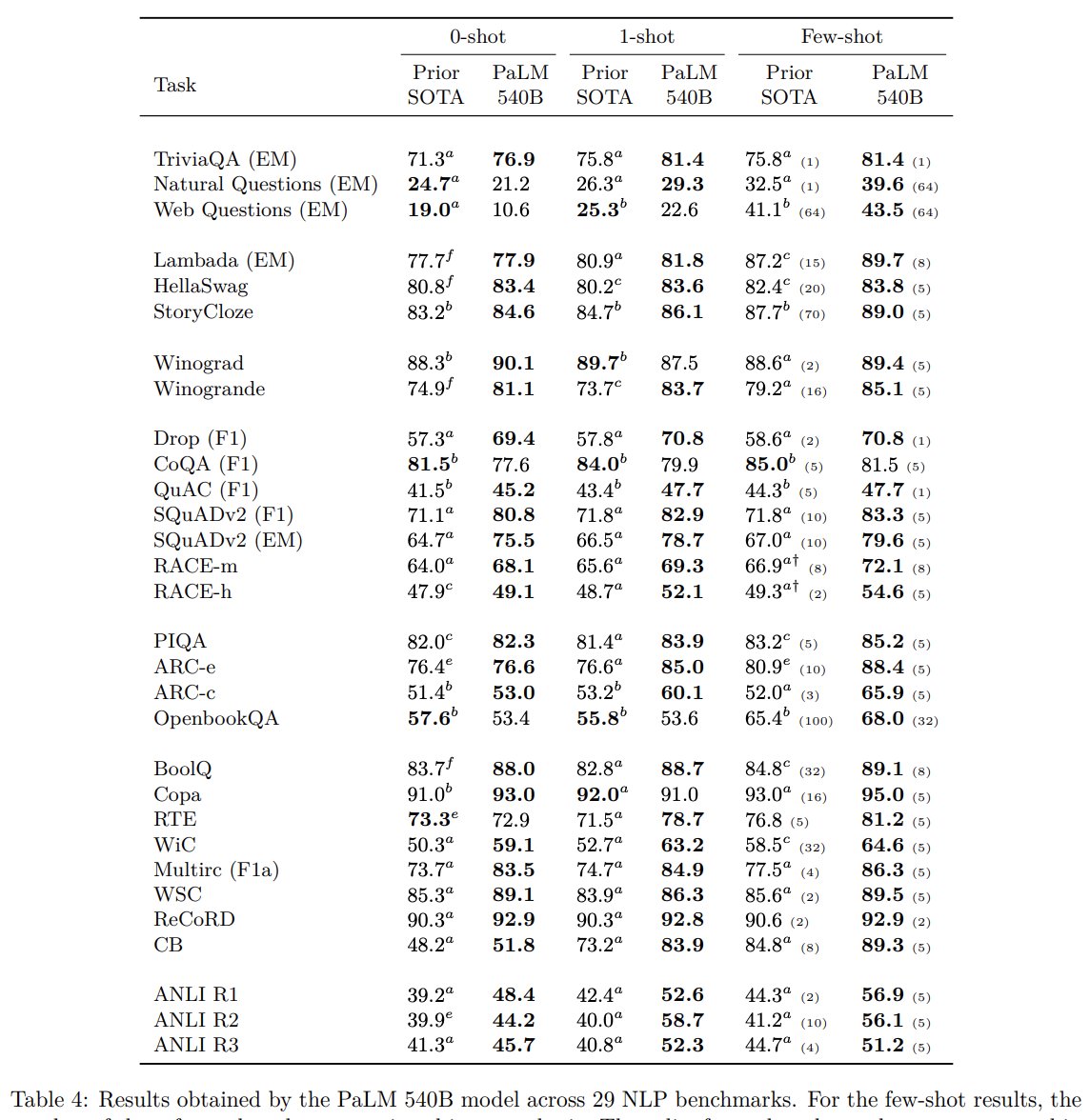
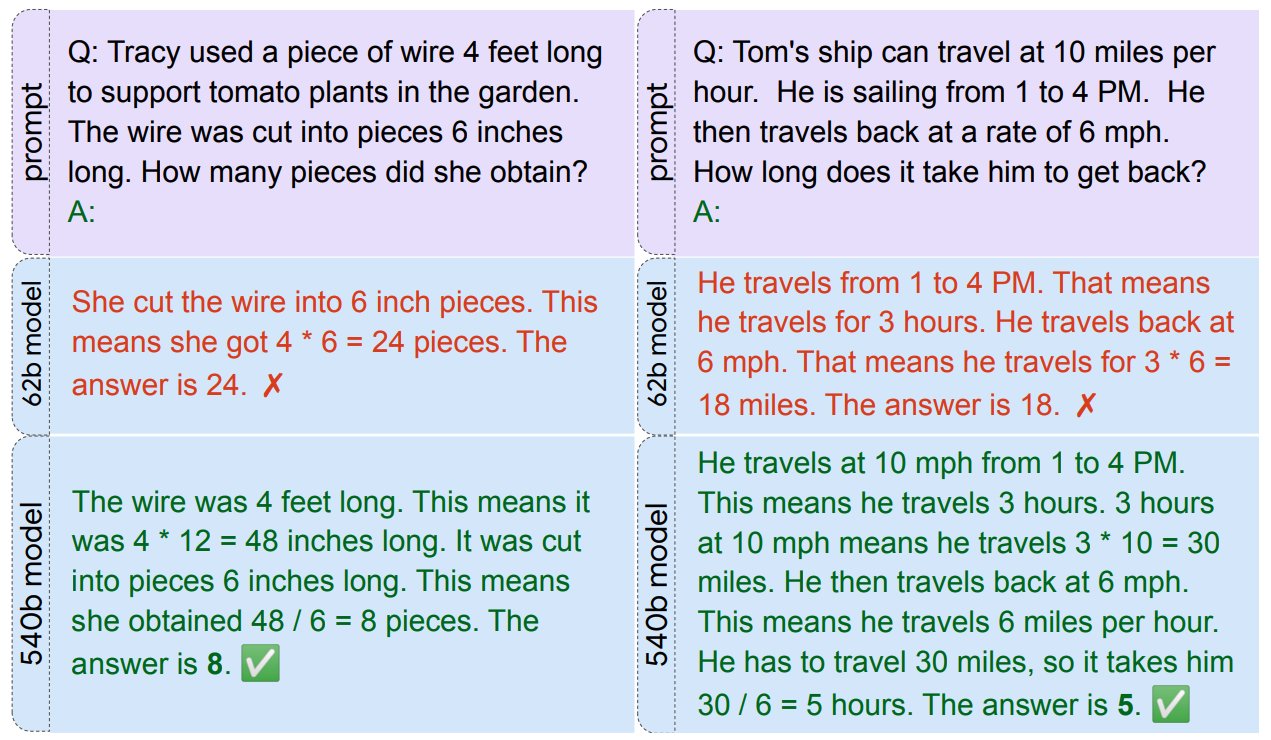
几幅体现模型能力的图:
解释笑话和推断链


另外参考:
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢