

介绍一篇 ACL'22 的论文,来自清华大学刘知远老师组。本文解决的问题是如何在预训练语言模型中引入任务所需的实体知识。此前常见的解决方法大致可以分为两种。
一种是在领域相关的语料上再做 further pretraining,比如 BioBERT。这种方法的缺点主要在于需要大量的额外训练,V100 上的训练时长可达数千小时。
另一种是直接引入知识图谱,比如 ERNIE。本文则认为:使得预训练模型具备实体知识,可以不完全依赖于引入外部知识图谱。已经有许多相关工作证明预训练模型自身就具备存储知识的能力,我们需要的只是一种调用出模型知识存储的方法。于是本文就提出了一种轻量的方法 PELT,能够非常简单有效的达到引入实体知识的效果。
论文标题:
A Simple but Effective Pluggable Entity Lookup Table for Pre-trained Language Models
论文链接:
https://arxiv.org/pdf/2202.13392.pdf
代码链接:
https://github.com/thunlp/PELT
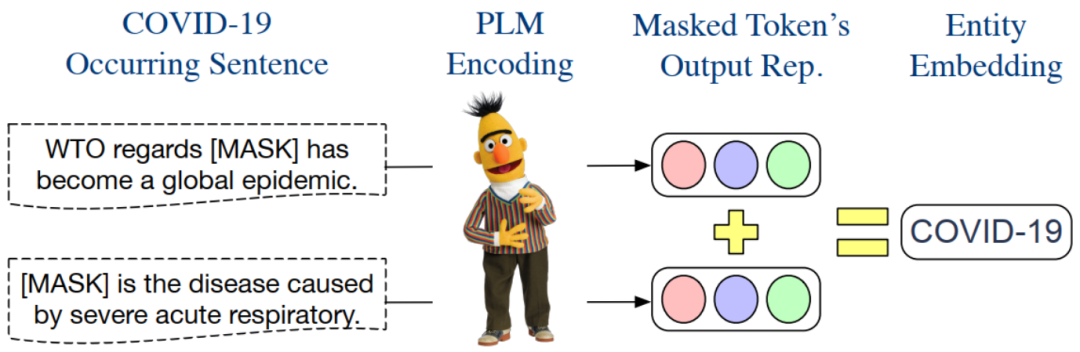
PELT 构建实体嵌入信息的过程
本文获取实体嵌入的方法非常简单。上图以实体 COVID-19 为例,说明了构建其嵌入的过程:

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢