
超参数调优对深度学习的重要性不言而喻,很多深度学习算法工程师都自嘲是“调参侠”,但“调参侠”面对大模型也束手无策,因为大模型训练成本高昂,GPT-3训练一次的费用是460万美元,甚至在明知有bug的情况下都无法重新训练一遍,在这种情况下,能完成模型训练已经实属不易,更不仅要说进行超参数调优了。因此,以往大模型的训练可以说都是不完整的,缺少了“超参数调优”这一重要环节,然而,最近微软和OpenAI合作的新工作μTransfer为大模型的超参数调优提供了解决方案,如图1所示,即先在小模型上进行超参数调优,再迁移到大模型,下面将对该工作进行简单介绍,详细内容可参考论文《Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer》。

论文链接:https://arxiv.org/pdf/2203.03466v1.pdf
代码链接:https://github.com/microsoft/mup

图1 μTransfer算法流程
可能有人会有疑问,先在小模型调优超参数,再迁移到大模型,这个思路好像也不难,之前没有人试过吗?从论文中的分析来看,这个方法并不是总是奏效的,得先使用μP(Maximal Update Parametrization)方法初始化模型参数,该方法可参考作者的另一篇工作《Feature Learning in Infinite-Width Neural Networks》。如图2所示,当在Transformer模型中增加模型宽度时,如果不使用μP,不同宽度的模型的最优超参并不一致,更宽的模型并不总是比窄模型效果更好,而使用μP,不同宽度模型的最优学习率基本一致,宽模型总是比窄模型效果好。
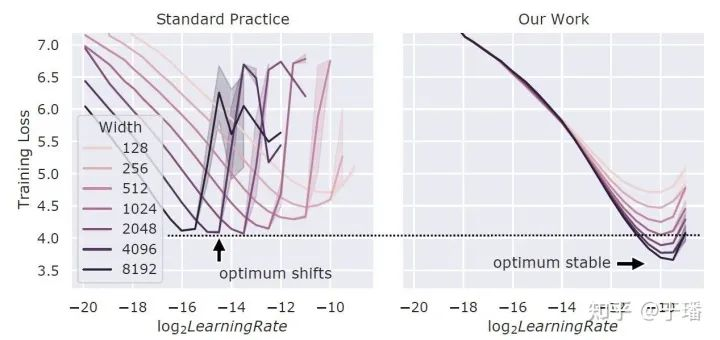
图2 用Adam训练的不同宽度Transformer模型的训练损失与学习率的关系
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢