

论文链接:https://arxiv.org/abs/2203.03831
数据集和代码链接:https://github.com/nie-lang/DeepRectangling
导读
图像拼接提供了宽视角图像的合成(FoV),但输出图像中会存在不规则的像素边界。 为了解决这个问题,现有的图像矩形化(image rectangle)方法致力于搜索初始边界和优化目标边界以实现边界修正, 然后通过拼接图像来生成标准的矩形图像。 然而,这些解决方案仅适用于具有丰富线性结构的图像,导致具有非线性对象的拼接图像明显失真。在此背景下,本文提出了第一个拼接图像rectangling的深度学习解决思路,同时构建了第一个带标签的rectangling数据集,将计算机图形学问题结合新的深度学习范式并带至计算机视觉顶会。

贡献
图像拼接技术在获得广视角的同时也会带来了不规则的边界问题(如上图b)。为了获得规则的矩形边界,裁剪(如上图c)和图像补全(如上图d)为两种常见的方法,但这两种方法会减少原始图像内容或增加新的图像内容,使得这些结果在实际应用中并不完全可靠。为了解决上述问题,何恺明老师早在2013年就提出了第一个方法——rectangling(矩形化),并发表于计算机图形学顶会SIGGRAPH。该方法在不增加、不减少图像内容的基础上,通过网格变形的方式将不规则的拼接图映射为矩形。然而,该算法受限于LSD检测的性能同时也无法提取有效的语义感知特征,对结构复杂的场景并不鲁棒,其结果往往呈现出部分扭曲(如上图e)。
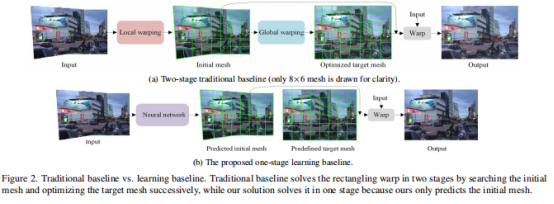
如上图所示,传统方法分为两个阶段:local warping和global warping:
- 在local warping阶段,首先借助seam-carving,通过不断向拼接图中插入感知不明显的seam,来使得拼接图逐渐变化为矩形,然后放置一个刚性的初始网格在其中,随后去掉之前插入的seam,使得该矩形逐渐退化为拼接图的形状。这样一插一抽的过程帮助获得了一个紧贴着拼接图边界的初始网格(initial mesh);
- 在global warping阶段,设计3个约束项来优化拼接图边界的网格 (optimized target mesh):直线保持项(约束warp后直线不会扭曲),形状保持项(鼓励mesh中每个网格的变形为相似变换)和边界项(强制约束最终mesh边界紧贴矩形边界);
- 通过从initial mesh到target mesh的warp,实现拼接图的矩形化。
不难发现,上述方法个两阶段的每一步都操作繁复,最后两个warp过程由于mesh的不规则也无法采用矩阵加速。
因此,本文提出了第一个拼接图像rectangling的深度学习解决思路,同时构建了第一个带标签的rectangling数据集。首先定义target mesh的形状(图2b “predefined target mesh”)为一个刚性的规则矩形,这种定义有助于矩形加速实现mesh warp,从而为深度学习实现mesh warp提供可能。随后rectangling被简化为了只需预测一个初始的mesh,并且这个初始的mesh必须和预定义的target mesh匹配。为此,利用神经网络从数据中学习mesh预测的能力。
方法
深度学习解决思路
与从单张图像中预测光流或深度类似,利用神经网络从单张图像中学习mesh预测是一个病态的问题。为了验证该问题的可解决性,本文没有设计复杂的网络结构,而是采用简单的特征提取+回归的思路。
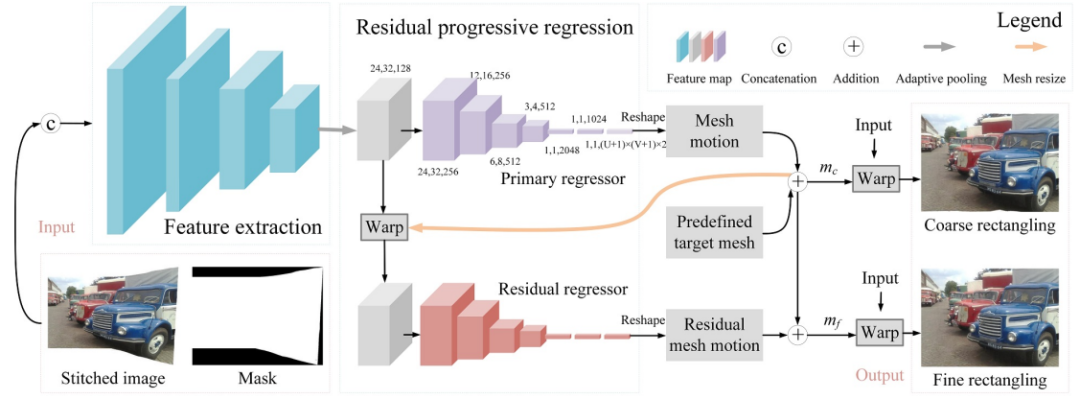
具体网络结构如上图,首先将拼接图与mask进行拼接作为输入,然后堆叠了卷积-池化模块来提取特征,随后再通过简单的卷积来实现mesh的预测回归。其中mesh(U×V)被表示成了(U+1)×(V+1)个顶点,每个顶带包含x和y方向的偏移量,即mesh可被表示成(U+1)×(V+1)×2的volume。
为了对应何恺明方法中优化的3个能量项,本文也将损失函数分为3个部分:content term,mesh term和boundary term:
- content term采用深度学习image generation任务中常见的L1 loss和感知损失,约束网络聚焦于语义感知明显的位置;
- mesh term设计了一个网格间和网格内loss,约束相邻网格的相似性;
- boundary term通过mask来约束rectangling的结果逼近标准矩形。
第一个带标签的rectangling数据集DIR-D

数据集的生成过程主要包括5个步骤:
- 采用ELA算法从UDISD数据集中拼接图像以收集广泛的真实拼接图像,去除了新增内容小于10%面积的图像;
- 使用何凯明老师的方法生成大量的变形mesh;
- 应用变形mesh的逆矩阵处理真实矩形图像(来自MS-COCO和收集的视频帧)以生成合成拼接图像,如图5(左)所示;
- 人工消除变形图像;
- 将真实的拼接图像混合到合成拼接图像的训练集中,以提高泛化能力。
简单说来,为了获得rectangling的数据集,DIR-D从正常的矩形图像出发,反向warp出非矩形的结果,来模拟拼接图的不规则边界。为了使得反向warp出的模拟拼接图更加真实且无畸变,DIR-D人工对warp的结果进行了严格的筛选,最终从六万多张样本中挑选出了5839个训练样本和519个测试样本,每个样本的分辨率为512×384。
实验
本文在提出的数据集(DIR-D)上对深度学习解决思路与传统方法进行全面的对比,如定量评估、无参定量评估、定性结果比较、user study等。
定量评估
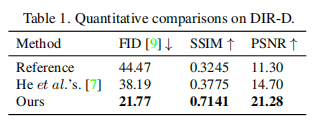
从这个表中可以看出,所提出的学习方案在DIR-D的每个度量上都明显优于传统解。这一显著的改进归因于我们的内容保留特性,它可以保持线性和非线性结构。
无参定量评估
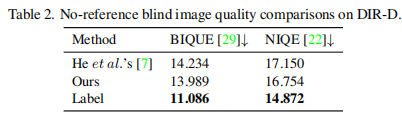
如表2所示,本文采用BIQUE[29]和NIQE[22]作为“无参考”的评估指标,其中我们的解决方案可以产生更高质量的结果。
user study
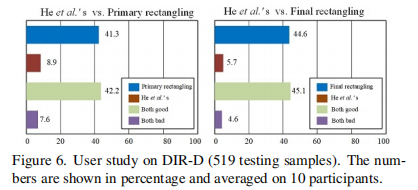
在这项研究中,共邀请了10名参与者,包括5名具有计算机视觉背景的研究人员/学生和5名在这个社区以外的志愿者。结果如图6所示,其中本文的解决方案是更多用户的首选。
定性结果比较

从图7的结果中可以观察到,本文的方法在两个场景中明显优于传统方法,其优势归功于内容保存能力,可以保持网格形状保存和内容的感知自然。

除此之外,本文还在经典的图像拼接数据集上展示了从拼接到rectangling的过程来验证本文算法的泛化性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢