
近日,谷歌公开了其Pathways系统的论文[8],并训练了5400亿参数的大模型PaLM。其中,稀疏激活(Sparse Activation)被反复提及。今天我们就讲讲这个概念。
知识点
1.稀疏激活指的是如果模型在应对特定的任务或给定特定的数据样本时,仅有一部分被激活。这种模型就是稀疏激活的模型。
2.稀疏激活模型能够在提升模型容量的同时,降低所需的算力。同时,稀疏激活模型的多任务能力更强。
3.稀疏激活技术起源于谷歌2017年提出的稀疏门控专家混合层技术,在Switch Transformer上得到了改进并发扬光大,目前已在多种大模型上得到应用。
定义
对于一个超大规模的预训练模型,如果模型在进行特定的任务或给定特定的数据或样本时,模型仅有部分被激活,这个模型就是稀疏激活的模型。
稀疏激活模型的优势在于,其能够极大降低模型的算力成本。以往的超大规模预训练模型都是“密集”(Dense)的,即模型在训练和推理的过程中,所有的参数都会被激活。当模型的规模增大的时候,全激活的模型带来的算力成本也会急剧升高。
但稀疏激活模型在训练和推理过程中不需要激活整个模型,因此模型虽然容量很大(参数规模大),但计算成本相比同等规模的密集模型更低。
此外,由于选择激活的部分由模型本身决定,模型能够在应对不同的任务时激活不同的部分,因此具有多任务能力。而密集模型在应对不同的任务时使用的都需要激活所有的,同一套的参数,这样反而会出现“多而不精”的问题——如灾难性遗忘(模型在学习新任务后,忘掉了之前学习过的任务)。
稀疏激活技术的发展过程
稀疏激活技术仍在快速发展,目前主要经历了以下三个过程[9]:
1.稀疏门控专家混合层:起源
稀疏激活的技术最早是谷歌在2017年提出的稀疏门控专家混合层(Sparsely-Gated Mixture-of-Experts Layer,MoE)。[1]
这是一种能够增加模型的容量(参数规模)和能力,但不用成比例地提升计算量的方法。
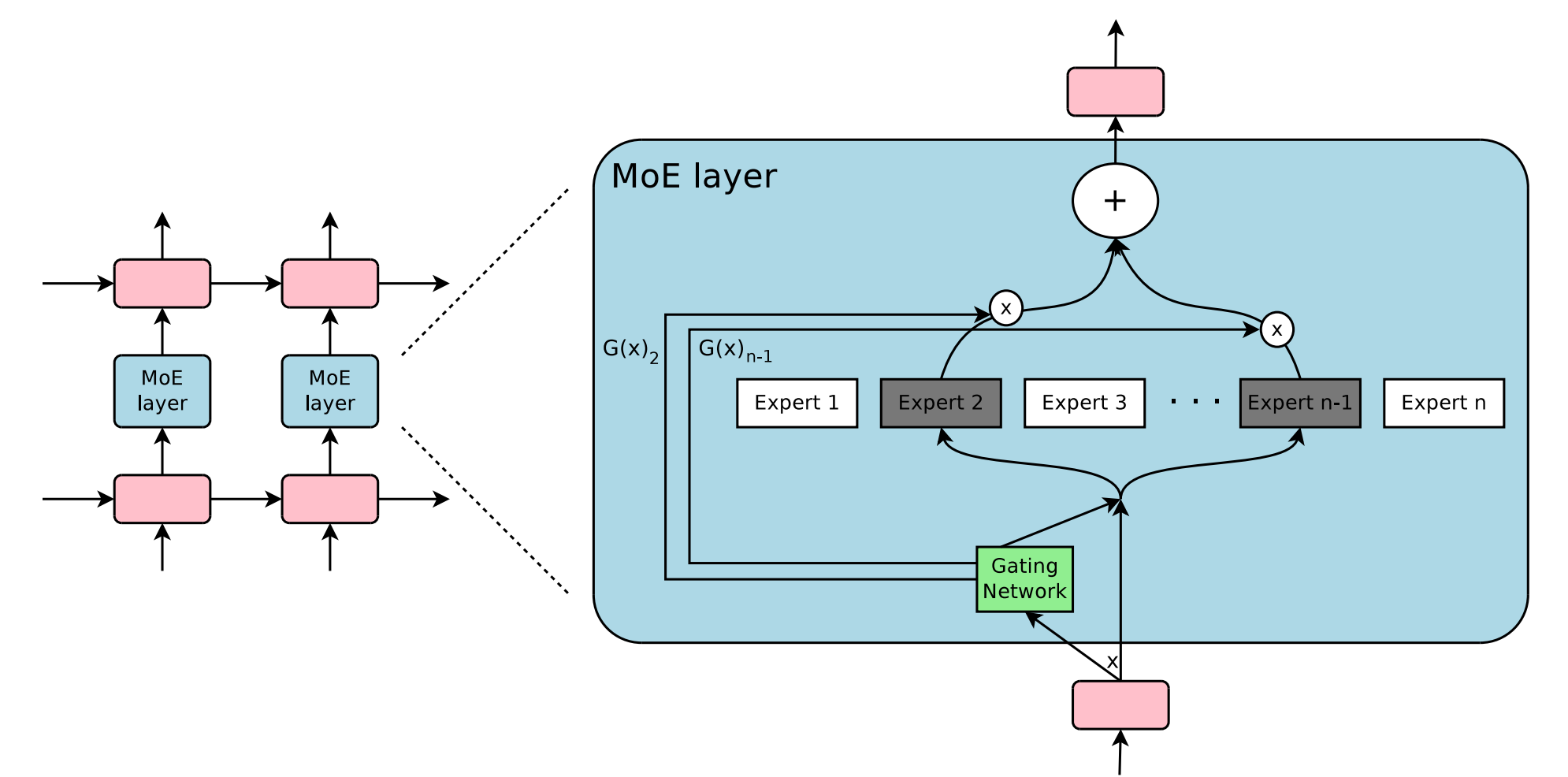
MoE模块由多个专家(Expert)组成,其中包含一个可训练的门控网络(Gating Network),由该网络选择合适的专家,组成稀疏组合,来处理输入样本。专家模块本身可以是前馈神经网络等。
MoE提出后,谷歌在GShard上进行了应用,训练出一个1600亿参数的翻译模型。[2]
2.Switch Transformer:扩展到万亿参数模型
Switch Transformer也采用了MoE技术,但将规模扩展到了万亿参数规模。并解决了MoE的复杂性、通信成本高、训练不稳定等问题。[3]
其中最直观的改进在于更为简化的MoE架构,用Switching FFN 层替代了Transformer中的密集前馈网络,并使用路由(Router)将任务分配给单个的专家。
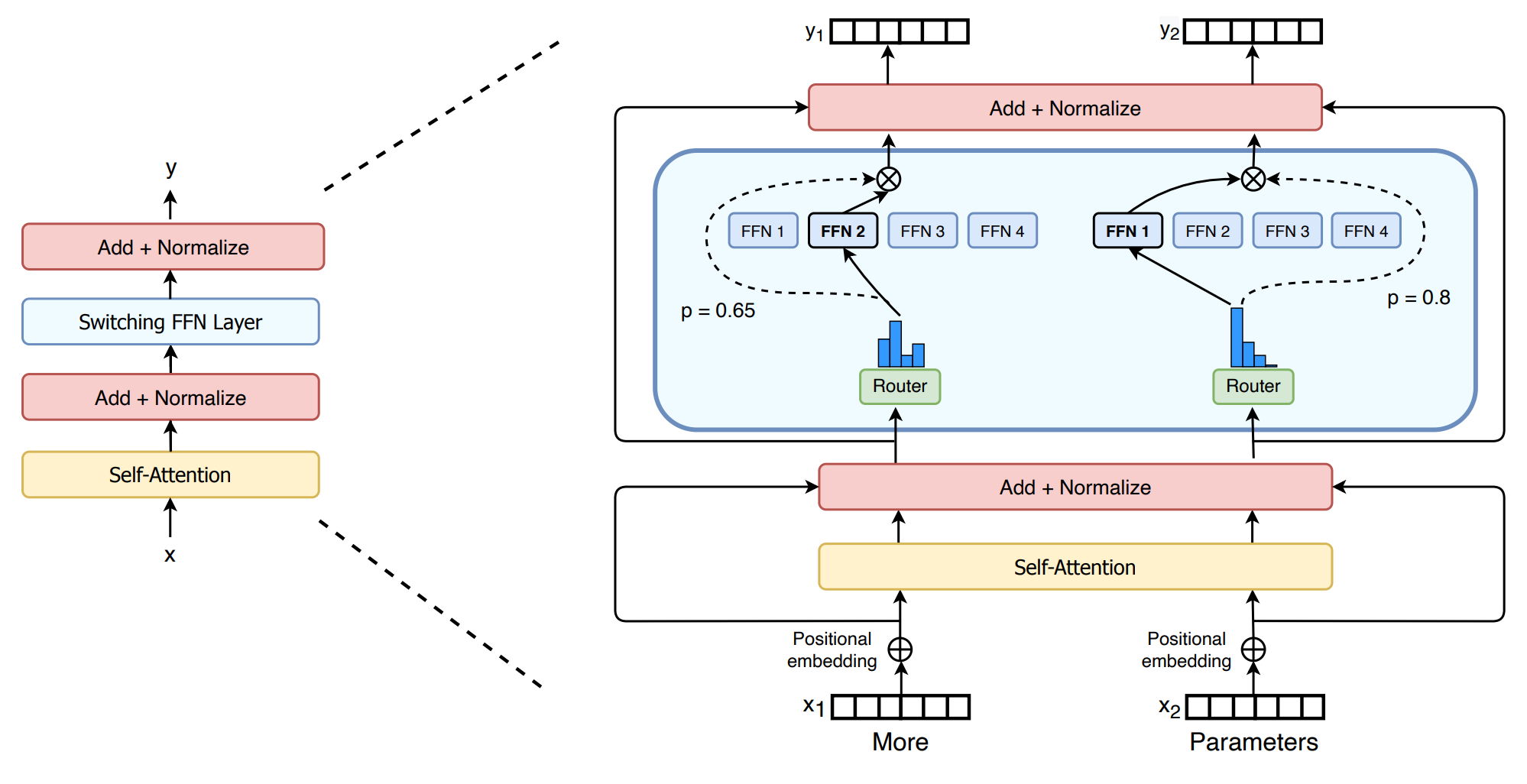 同时,Switch Transformer层中也引入了Capacity Factor,用于调控每个专家能够处理的任务量。当一些专家的任务过多,能够动态地调整计算和通信成本。
同时,Switch Transformer层中也引入了Capacity Factor,用于调控每个专家能够处理的任务量。当一些专家的任务过多,能够动态地调整计算和通信成本。
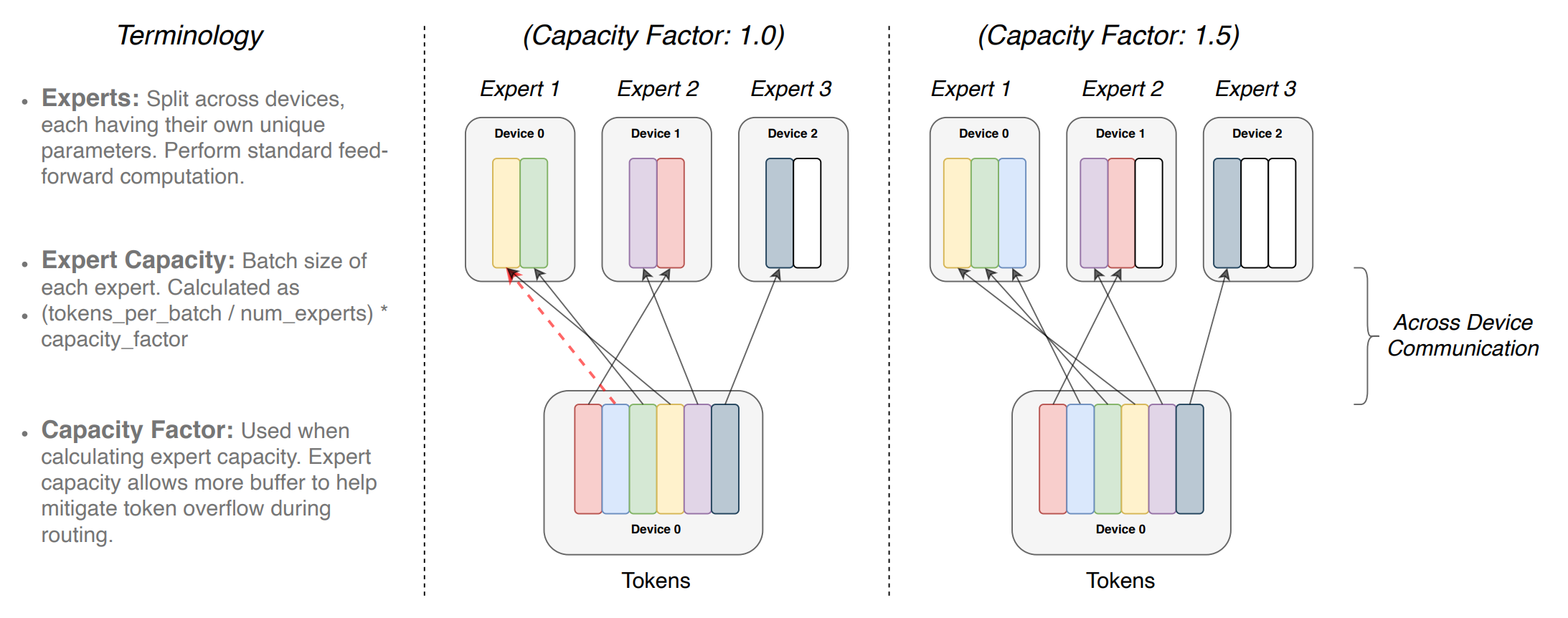 Capacity Factor的计算公式如下:
Capacity Factor的计算公式如下:
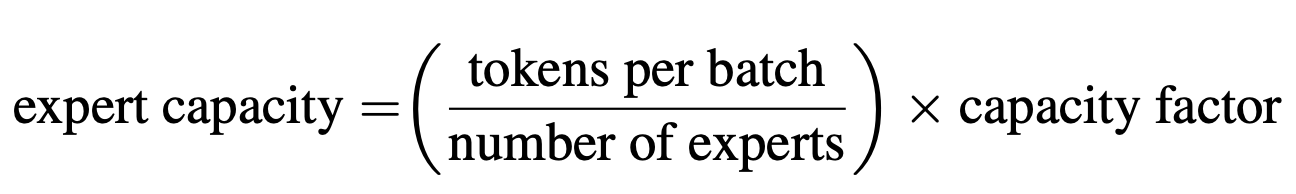 3.多种稀疏激活模型涌现
3.多种稀疏激活模型涌现
近来,有大量采用稀疏激活技术的模型不断涌现。典型的案例包括:
(1)悟道2.0:1.75万亿参数,基于自研的FastMoE技术,在国产超算上完成训练。[4]
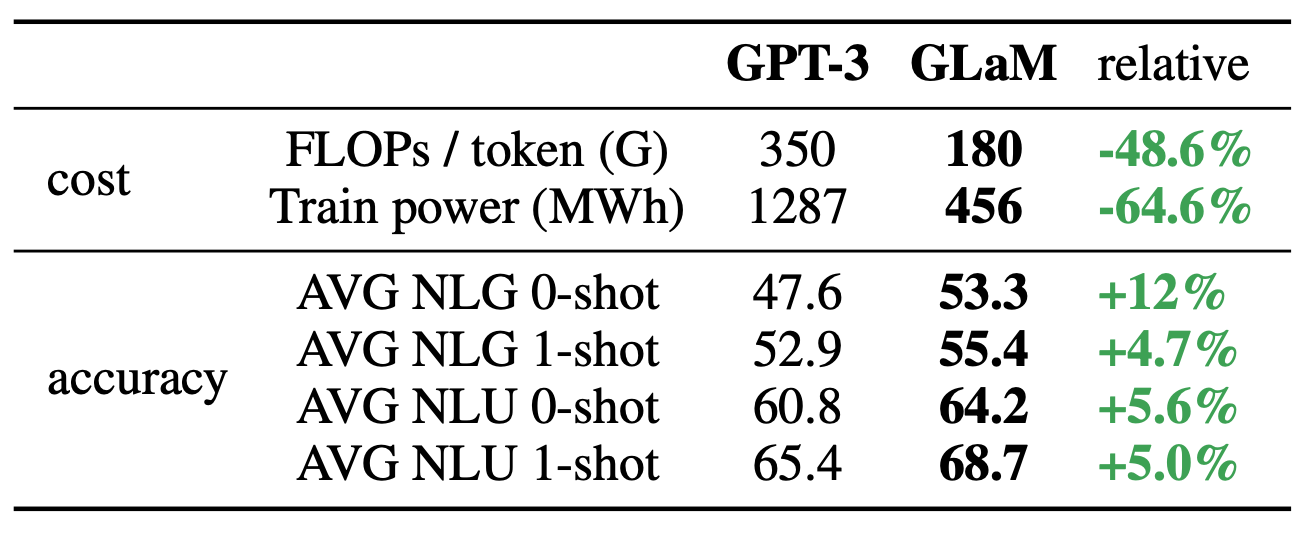
(2)GLaM:1.2万亿的通用稀疏语言模型,在7项小样本学习领域性能超过GPT-3。[5]
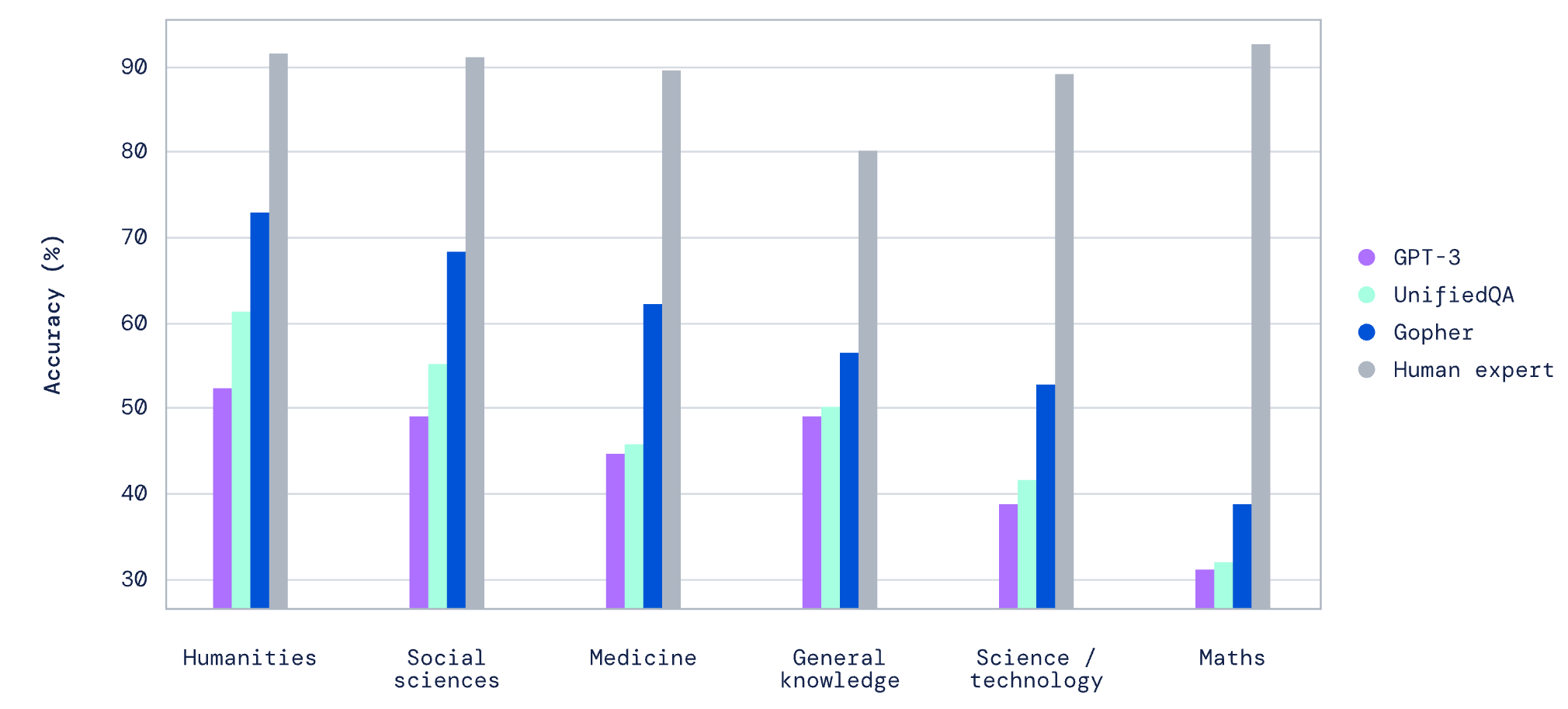
(3)Gopher:2400亿参数,具备小样本多任务语言理解能力。[6]
(4)PaLM:5400亿参数,基于Pathways系统进行训练,在数百个语言理解和生成基准上都取得了最先进的小样本学习结果,还包括推理、多语言任务、源代码生成等任务。[7]
参考链接
[1] Shazeer, Noam, et al. "Outrageously large neural networks: The sparsely-gated mixture-of-experts layer." arXiv preprint arXiv:1701.06538 (2017).
[2] Lepikhin, Dmitry, et al. "Gshard: Scaling giant models with conditional computation and automatic sharding." arXiv preprint arXiv:2006.16668 (2020).
[3] Fedus, William, Barret Zoph, and Noam Shazeer. "Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity." arXiv preprint arXiv:2101.03961 (2021).
[4] 第三届北京智源大会开幕,全球最大智能模型“悟道2.0”重磅发布:https://hub.baai.ac.cn/view/8375
[5] Du, Nan, et al. "GLaM: Efficient Scaling of Language Models with Mixture-of-Experts." arXiv preprint arXiv:2112.06905 (2021).
[6] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[7] PaLM: Scaling Language Modeling with Pathways:https://storage.googleapis.com/pathways-language-model/PaLM-paper.pdf
[8] Introducing Pathways: A next-generation AI architecture:https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
[9] 稀疏性在机器学习中的发展趋势——Sparsity,稀疏激活,高效计算,MoE,稀疏注意力机制:https://zhuanlan.zhihu.com/p/463352552
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢