

Mobile-Former: Bridging MobileNet and Transformer
论文:https://arxiv.org/abs/2108.05895
最近,Vision Transformer(ViT)展示了全局处理的优势,与cnn相比实现了显著的性能提升。然而,当将计算预算限制在1G FLOPs内时,增益维特减少。如果进一步挑战计算成本,基于depthwise和pointwise卷积的MobileNet和它的扩展仍然占据着一席之地(例如,少于300M的FLOPs图像分类),这又自然而然地提出了一个问题:
如何设计有效的网络来有效地编码局部处理和全局交互?
一个简单的想法是将卷积和Vision Transformer结合起来。最近的研究表明,将卷积和Vision Transformer串联在一起,无论是在开始时使用卷积,还是将卷积插入到每个Transformer块中都是有益的。
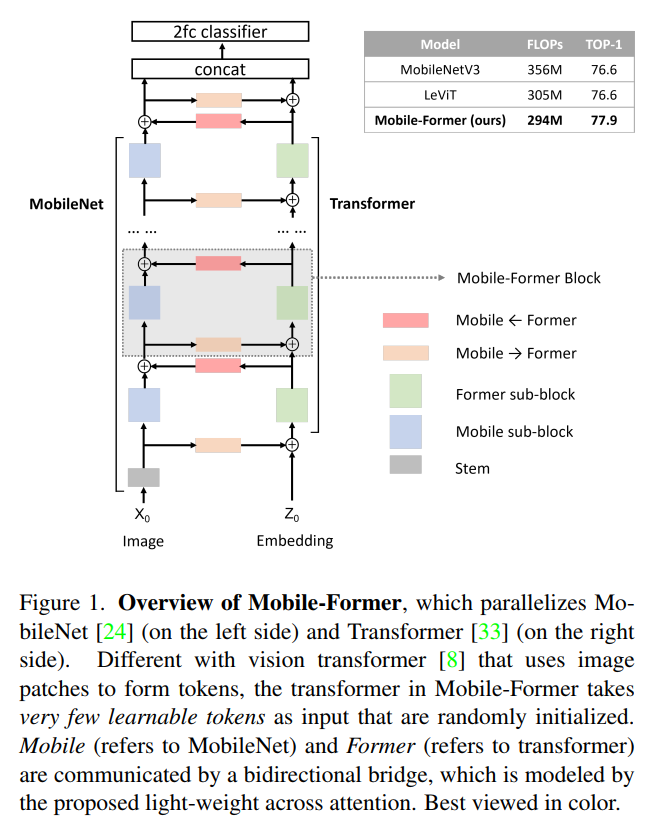
图1
在本文中,作者将设计范式从串联向并联转变,提出了一种新的MobileNet和Transformer并行化,并在两者之间建立双向桥接(见图)。将其命名为Mobile-Former,其中Mobile指MobileNet, Former指transformer。Mobile以图像为输入堆叠mobile block(或inverted bottleneck)。它利用高效的depthwise和pointwise卷积来提取像素级的局部特征。前者以一些可学习的token作为输入,叠加multi-head attention和前馈网络(FFN)。这些token用于对图像的全局特征进行编码。
Mobile-Former是MobileNet和Transformer的并行设计,中间有一个双向桥接。这种结构利用了MobileNet在局部处理和Transformer在全局交互方面的优势。并且该桥接可以实现局部和全局特征的双向融合。与最近在视觉Transformer上的工作不同,Mobile-Former中的Transformer包含非常少的随机初始化的token(例如少于6个token),从而导致计算成本低。
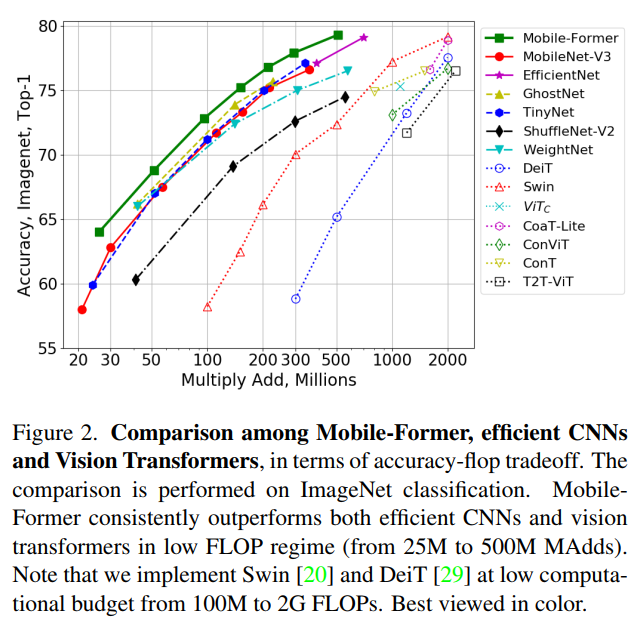
结合提出的轻量级交叉注意力对桥接进行建模,Mobile-Former不仅计算效率高,而且具有更强的表示能力,在ImageNet分类上从25M到500MFLOPs的低 FLOPs机制下优于MobileNetV3。例如,它在294M FLOPs下实现了77.9%的top-1准确率,比MobileNetV3提高了1.3%,但节省了17%的计算量。在转移到目标检测时,Mobile-Former 比MobileNetV3高8.6 AP。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢