
作者:Rabeeh Karimi Mahabadi, Luke Zettlemoyer, James Henderson,等
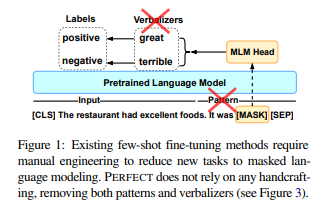
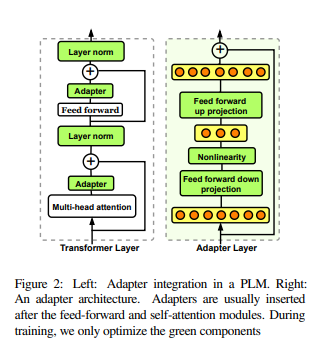
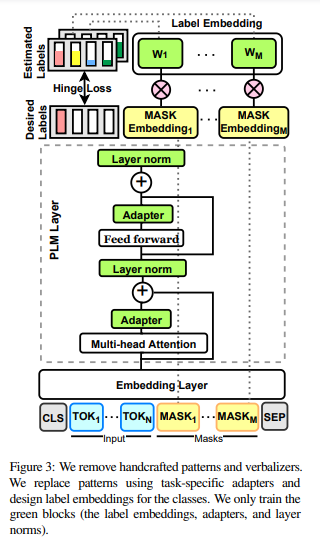
简介:本文研究多标记固定长度分类器方法、实现小样本NLP的高效微调。当前对预训练掩码语言模型 (PLM) 进行少量微调的方法需要为每个新任务精心设计提示和语言器,以将示例转换为 PLM 可以评分的完形填空格式。在这项工作中,作者提出了 PERFECT:一种简单而有效的 PLM 微调方法,无需依赖任何此类人工参与、只需 32 个数据点即可非常有效。PERFECT 做出了两个关键的设计选择:(1)作者展示了手动设计的任务提示可以替换为任务特定的适配器,这些适配器可以实现样本高效的微调,并将内存和存储成本分别降低大约 5 倍和 100 倍。(2)作者并未使用手工制作的语言器,而是在微调期间学习新的多标记标签嵌入、不依赖于模型词汇表,并且允许作者避免复杂的自回归解码。这些嵌入不仅可以从有限的数据中学习,而且可以使训练和推理速度提高近 100 倍。对各种小样本 NLP 任务的实验表明,PERFECT 在简单高效的同时也优于现有的最先进的小样本学习方法。
论文下载:https://arxiv.org/pdf/2204.01172.pdf
代码下载:https://github.com/rabeehk/perfect
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢