

论文链接: https://arxiv.org/abs/2111.15193
代码链接(已开源):https://github.com/OliverRensu/Shunted-Transformer
导读
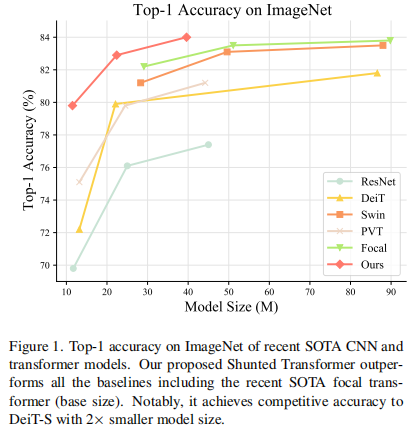
近期提出的诸多Vision Transformer (ViT) 模型在各种计算机视觉任务中展示了令人鼓舞的结果,这要归功于它们可以通过自注意力对图像块或标记的远程依赖关系进行建模。然而,这些模型通常为每一层内每个标记特征指定相似的感受野。这种做法不可避免地限制了每个自注意力层捕获多尺度特征的能力,从而导致在处理具有不同尺度多对象的图像时性能下降。为了解决这个问题,本文提出了一种新颖的通用策略,称为分流自我注意 (SSA),它允许 ViT 在每个自注意力层的混合尺度上对感受野进行抽象建模。 SSA 的关键思想是将异构感受野的大小注入到Token中,在计算自注意力权重之前选择性地合并Token以得到更大尺度的对象特征,同时保留部分Token细粒度的特征。这种新颖的合并方案使自注意力层能够学习不同尺度大小对象之间的关系,同时减少Token数量和计算成本。各种任务的广泛实验证明了 SSA 的优越性。具体来说,基于 SSA 的 Transformer 实现了 84.0% 的 Top-1 准确率,并在 ImageNet 上以只有一半的模型大小和计算成本超过了最先进的 Focal Transformer,在 COCO 上超过了local Transformer 1.3 mAP ,在ADE20K 上取得了2.9 mIOU的性能提升。
贡献
基于自注意力机制(Self-Attention)的Vision Transformer (ViT)在多个计算机视觉任务上取得了令人惊艳的成果。然而自注意力机制的内存消耗是和Token数量的平方相关的,这导致ViT需要在第一层进行16x16下采样,并对采样结果进行一致的离散化处理,这使得每个Token对应的特征是粗糙的和单一尺度的,同时每个tokens的感受野固定,因此无法同时捕获不同尺度的特征。

上图中,作者对多种Transformer模型中的注意力机制进行了比较,包括ViT、Pyramid Vision Transformer(PVT)、SSA。其中圆点的数量表示计算量,圆点的大小表示每个token的感受野。不难发现,ViT需要很大的计算量,对于捕捉大的物体是多余的,PVT通过融合tokens来降低计算量,但是这样会使得来自小物体的tokens和背景噪音混合,不利于捕捉小物体。但SSA能准确捕捉多尺度的物体。
SSA将多头注意力机制分成不同的group。每一个group都负责一个注意力粒度,对于细粒度的group,SSA学习去融合较少的tokens,并且保证更多的细节,对于粗粒度的group,SSA则自适应地去融合大量tokens,因此减少了计算量,同时又保证了捕捉大物体的能力,这样的多粒度的组联合的去学习多粒度的信息,让整个模型能够捕捉多尺度的物体。
本文主要贡献可以总结如下:
- 提出了Shunted Self-Attention (SSA),它通过在每一个注意力层内集成多尺度的特征提取能力,自适应地合并针对大物体的tokens以提高计算效率,并保留针对小物体上的特征捕捉能力;
- 基于SSA,提出了Shunted Transformer,这一模型在捕捉多尺度物体时具有显著的优势;
- 对Shunted Transformer在分类、目标检测以及语义分割上做了验证。实验结果表明在类似的模型大小下,Shunted Transformer始终优于以前的Vision Transformer。
方法
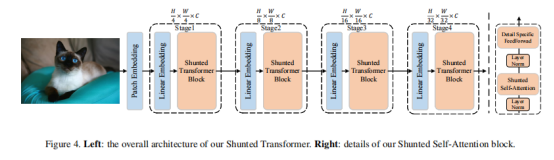
作者首先给出了Shunted Transformer的整体结构图,其主要区别在于SSA注意力机制,它与 ViT 中的传统自注意力块之间有两个主要区别:1)SSA 为每个自注意力层引入了分流机制,以捕获多尺度信息以更好地不同大小的模型对象,特别是小物件; 2)它通过增加Token之间的信息交互来增强在前馈层中提取局部信息的能力。 此外,Shunted Transformer还部署了一种新的补丁嵌入方法,以便为第一个注意块获得更好的输入特征图。
Shunted Self-Attention注意力层
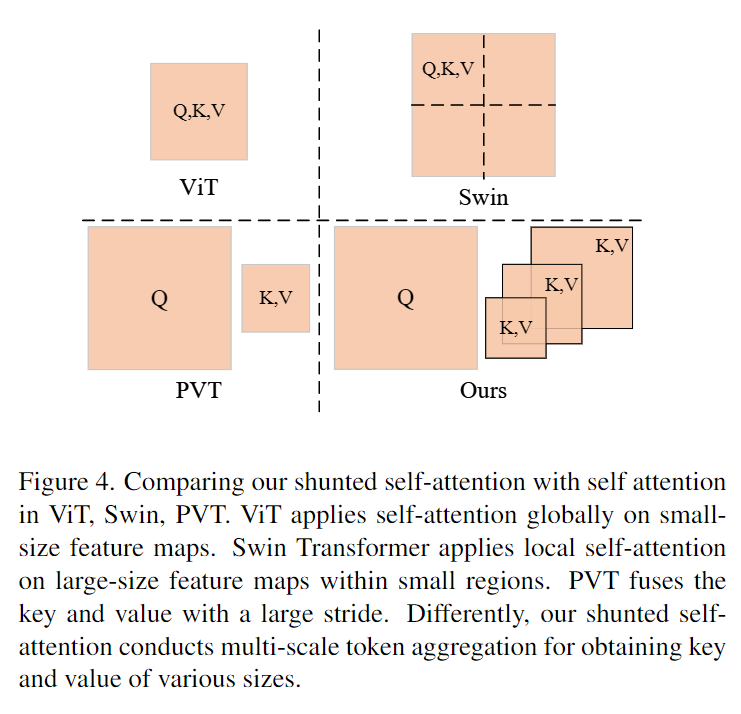
不同于ViT应用注意力机制在小尺寸特征图上,Swin分割特征图局部自注意力,PVT只有单尺度粗颗粒度特征融合。SSA借鉴了PVT的提出要通过token融合产生不同大小的{Key, Value},同时使用local enhancing layer强化value:
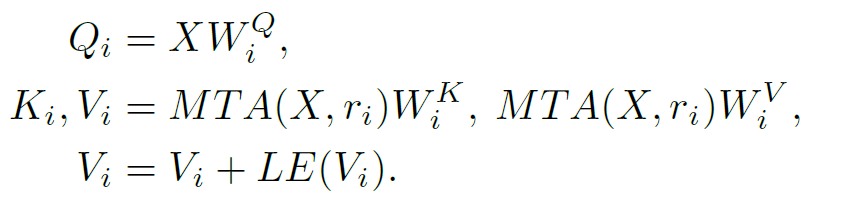
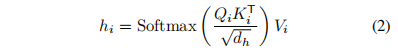
其中MAT指多尺度特征融合在第i个head的下采样率为ri。当r变大的时候,K和V里面的更多的token被融合在了一起,因此K和V的长度就变短了,计算量就减少了,但是仍然保持了捕捉大物体的能力,相反当r变小的时候,更多的细节就被保存在K和V里面。通过整合多种多样的r在一个注意力层里,就能够实现一个注意力层捕捉多粒度的特征。
Detail-specific Feedforward Layers
传统的feedforward layer是point-wise的,没有跨token的信息,因此本文提出通过明确细节来补充局部信息:
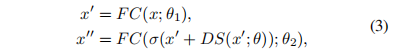
其中DS()表示细节明确层,通过一个深度卷积模块实现。

Conv-Stem Patch Embedding
和之前的只用一层7x7,步长为4的卷积作为patch embedding不同,Shunted Transformer采用了多层卷积作为patch embedding。其中第一层为7x7步长为2的卷积紧接着一些3x3的卷积,其数量取决于模型大小。最后,一个步长为2的不重叠映射生成输入到注意力的特征。

实验
本文在分类、检测、分割三个任务上进行了Shunted Transformer的性能比较,分别采用ImageNet-1K、COCO、ADE20K数据集。
分类
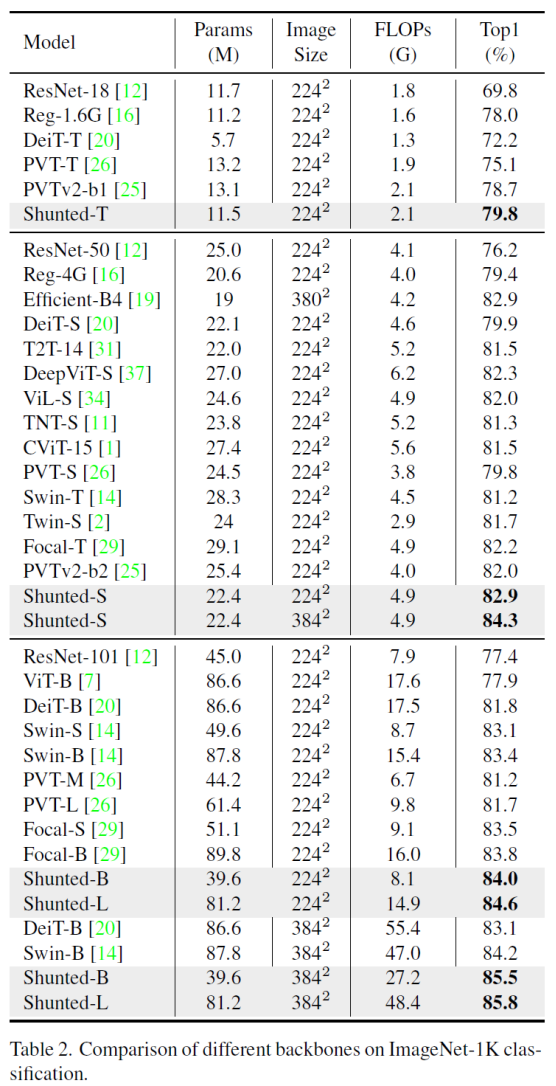
相比之前的Transformer模型,Shunted Transformer无论在大参数量或者小参数量、224x224和384x384的输入尺寸下都显著超越了之前的方法。
目标检测及实例分割
本文在 COCO 2017上评估目标检测和实例分割的实验结果,将Shunted Transformer作为主干插入 Mask R CNN,并与其他 SOTA 主干网络进行比较,包括 ResNet、Swin Transformer、Pyramid Vision Transformer、Twin 和 Focal Transformer。
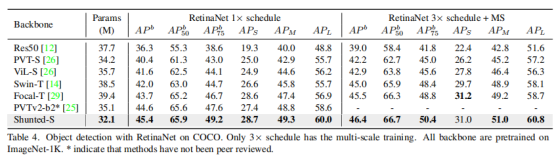
在表3中,本文采用Mask-RCNN进行目标检测,并报告了不同CNN和变压器骨干的bbox mAP(APb)。在相同参数的条件下,Shunted Transformer明显优于之前的SOTA。
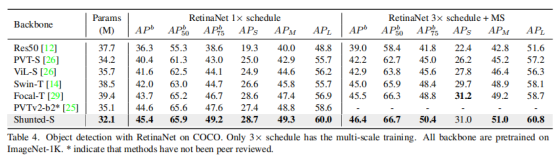
论文还在表4中展示了 RetinaNet的结果。以最小的参数,Shunted Transformer明显优于之前的所有方法。
分割
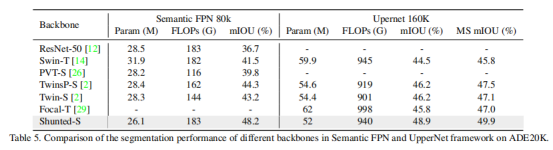
结果见表5。Shunted Transformer在性能上优于已有方法,且在参数量上取得了较大的优势。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢