
近年来,许多研究者开始将大型AI模型部署在分布式训练系统上进行计算。随着模型参数规模和数据的快速增加,让整个系统进行AI模型的训练变得更加困难。因此,通过协调多个系统设备,提升分布式训练系统的效率和可扩展性,成为当前一些研究者关注的重点。并行技术在其中就起到了关键的作用。
知识点
1.并行通过将数据、模型、计算流程等进行分割,使其能够在分布式计算系统中的多个工作节点(服务器)上同时开始进行计算,因此具有更高的效率。
2.并行可分为数据并行、模型并行、Pipeline并行和专家并行四种,每一种都有特定的数据、模型、任务的分割计算方法。
定义
并行指的是在分布式计算系统内,对需要处理的数据和计算任务进行分配,使整个系统能够更为高效、均衡地完成大规模的AI训练和推理任务。简单理解,并行通过将数据、模型、计算流程等进行分割,使其能够在分布式计算系统中的多个工作节点(服务器)上同时开始进行计算,因此具有更高的效率。
根据并行方式的不同,可以分为以下四种方法[1]:
1.数据并行
数据并行可以定义为采用同一个模型,在不同的节点上用不同的数据进行训练,并统一更新参数的方法。例如,设置一个参数服务器(Parameter Server),由该服务器保存模型,并让其他工作节点服务器拷贝该模型。当进行数据并行时,各个工作服务器训练不同的数据,并在更新了梯度后,传回参数服务器进行参数更新。
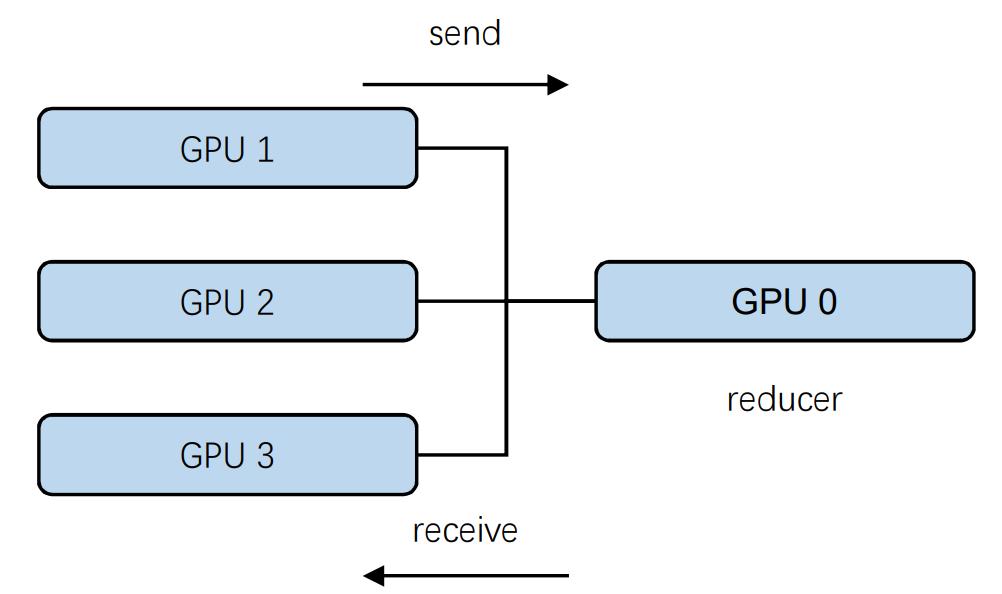
但是,如果采用这种同步更新的策略,参数服务器就需要等待所有的子节点回传参数,如果某个子节点计算过于缓慢,可能会成为整个系统的计算瓶颈。
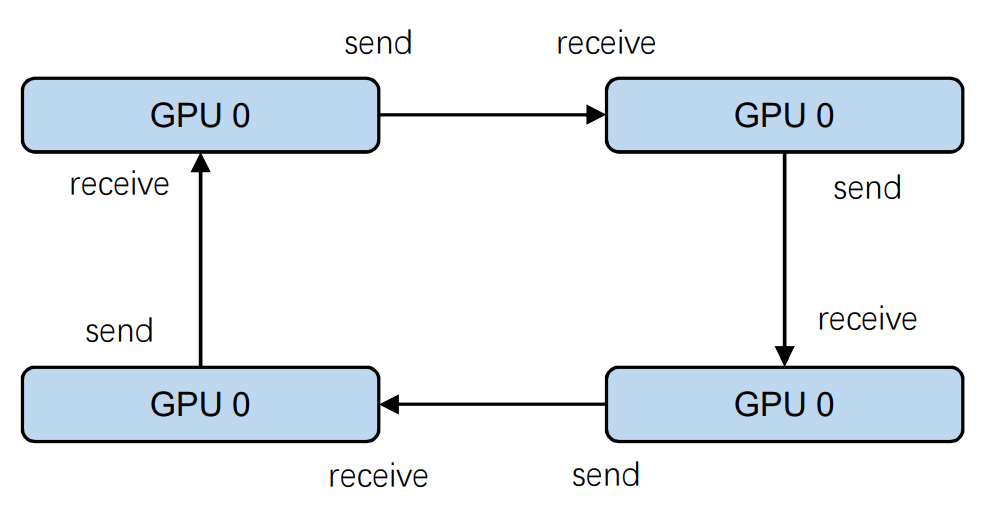
为了解决这个问题,数据并行方法中也有采用“Ring All-Reduce”的方法[2],解决上述问题。
2.模型并行
模型并行采用的则是将模型分为多份,同时进行计算的方法。例如,将模型张量的参数根据特定的维度进行分割,根据手工设计,由系统分配对应训练数据和特征图(可以是分割或复制的方法)。例如,Megatron-LM[3]模型在训练中采用更为手工的方式,将每个transformer块都进行了分割,实现了高性能的计算。
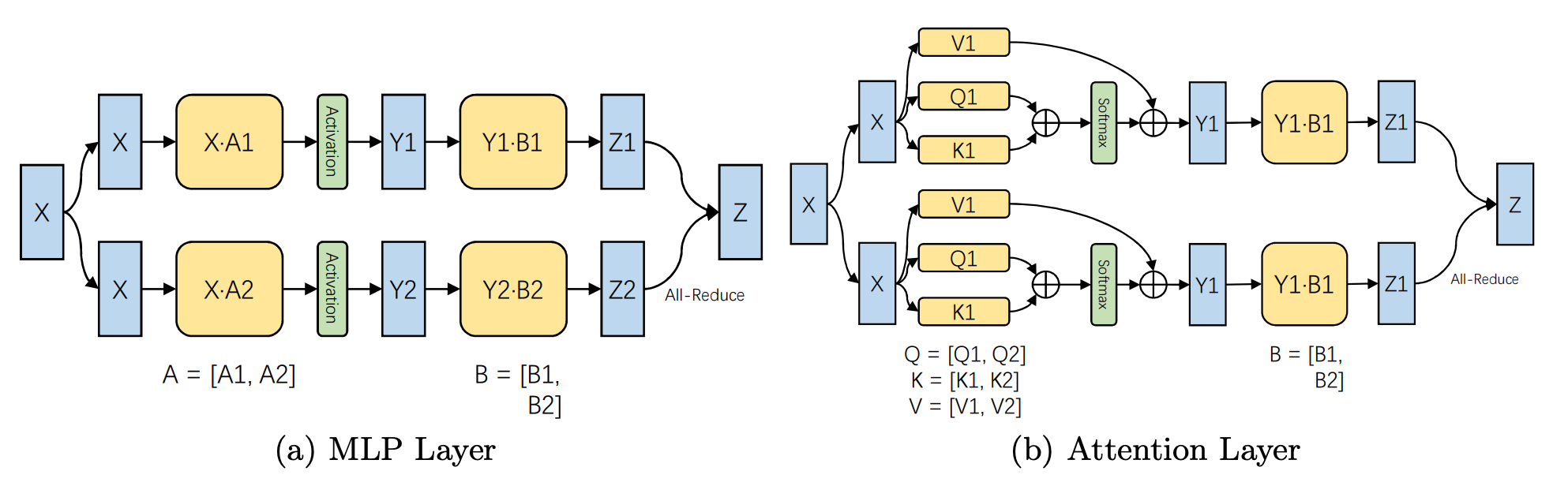
此外,Colossal-AI[6]采用了2D、2.5D、3D的张量分割方法,同样具有模型并行的计算能力。
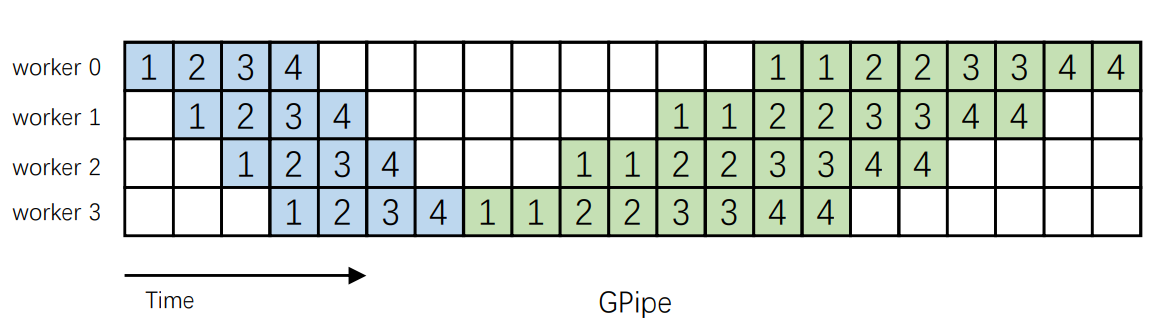
3.Pipeline并行
Pipeline(管道)可以理解为整个计算的流程。Pipleline并行便是通过对整个计算流程进行加速。例如,GPipe[4]引入了两个新的概念:全局Batch和局部Batch。一个全局Batch中包括了多个局部Batch,局部Batch会一个接一个通过Pipeline。中间的特征图会被传到邻近的工作节点上,而无需全局同步梯度。同时,大模型可以在系统中存储,因此无需复制模型参数。
 4.专家并行
4.专家并行
混合专家系统(MoE)成为近来很多大模型的网络架构,对于MoE模型的并行也成为研究热点。例如,GShard[5]引入了专家并行机制。模型中的专家模块(Expert)被部署在多个工作节点上,而在专家层之外,则保存着模型的大部分参数。当进行训练时,专家层之外采用数据并行的方法,专家层需要被激活时才进行计算。
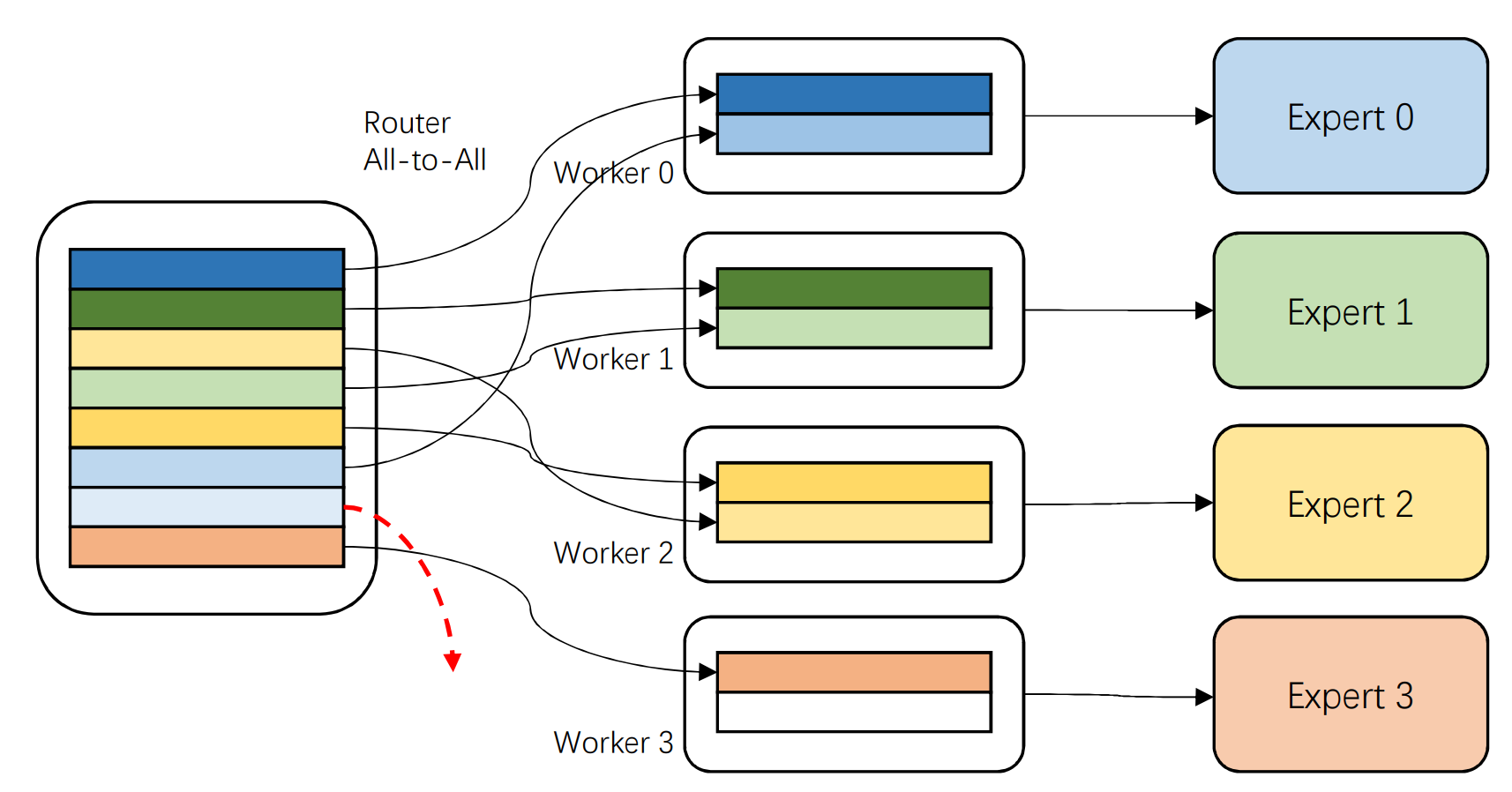 由于在分配给专家处理任务时可能出现某个专家负载过高或过低,导致系统低效的情况,研究者还会引入软限制和硬限制,强制负载均衡。
由于在分配给专家处理任务时可能出现某个专家负载过高或过低,导致系统低效的情况,研究者还会引入软限制和硬限制,强制负载均衡。
在训练规模达千亿和万亿的模型过程中,研究者会采用多种并行策略,完成计算任务。例如,2021年10月,微软和英伟达联合提出了 PTD-P(Inter-node Pipeline Parallelism, Intra-node Tensor Parallelism, and Data Parallelism)训练加速方法[7],通过数据并行、张量并行和 Pipeline 并行“三管齐下”的方式,将模型的吞吐量提高 10%以上。该并行方法可以在3072个GPU 上,以502P的算力对一万亿参数的GPT 架构模型进行训练,实现单GPU吞吐量52%的性能提升。
利用该技术,微软和英伟达在 3000 多块 GPU 上训练出 5300 亿参数的超大规模预训练语言模型Megatron-Turing。
参考链接
[1] Roadmap of Big Model:https://arxiv.org/pdf/2203.14101.pdf
[2] Alexander Sergeev and Mike Del Balso. Horovod: fast and easy distributed deep learning in tensorflow. CoRR, abs/1802.05799, 2018.
[3] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019.
[4] Narayanan, Deepak, et al. "Efficient large-scale language model training on GPU clusters using megatron-LM." Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 2021.
[5] Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668, 2020.
[6] Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems, 32:103–112, 2019.
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢