

论文地址
https://arxiv.org/pdf/2203.01305.pdf
项目地址
https://github.com/FengLi-ust/DN-DETR
导读
本文提出了一种新的去噪训练方法来加速 DETR(DEtection TRansformer)训练,并加深了对 DETR 类方法的缓慢收敛问题的见解。分析表明,DETR缓慢收敛是根本源域时解码器二分图匹配 (bipartite graph matching)的不稳定性,这一不稳定性使得早期训练阶段的优化目标不一致。为了解决这个问题,除了 Hungarian 损失之外,本文还向 Transformer 解码器添加了带有噪声的 ground-truth 边界框,并训练模型重建原始框,这有效地降低了二分图匹配难度并导致更快的收敛。本文提出的方法可以通过添加数十行代码轻松插入任何类似 DETR 的方法中,以实现显著的改进。实验结果证实,本文提出的 DN-DETR 在相同设置下取得了显着的改进(+1.9AP),并在使用 ResNet-50 的 DETR 类方法中取得了最好的结果(AP 43.4 和 48.6,分别训练 12 和 50 个 epoch)。与相同设置下的基线相比,DN-DETR 以 50% 的训练 epoch 实现了更好的性能。
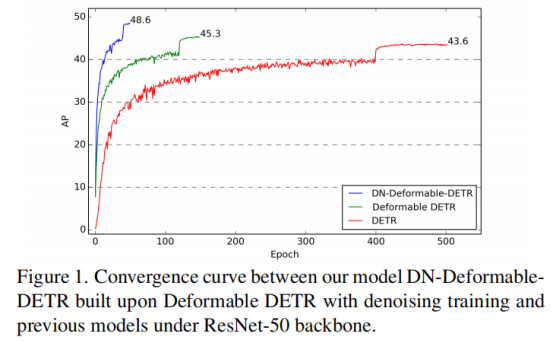
贡献
DETR把目标检测建模为一个set prediction的问题,并利用Hungarian matching算法来解决decoder输出的objects和ground-truth objects的匹配。因此,Hungarian matching算法匹配的离散性和模型训练的随机性,导致ground-truth的匹配变成了一个动态的、不稳定的过程。
要解决这个问题,首先要理解decoder到底在做什么。如今decoder queries在很多工作中被解读为anchor坐标,即一个四维的检测框:(x,y,w,h)。每一层decoder都会预测相对偏移量(dx,dy,dw,dh)并去更新检测框,得到一个更加精确的检测框预测(x’,y’,w’,h’)=(x,y,w,h)+(dx,dy,dw,dh)。
从这个思路继续延伸,decoder实际上学习了两种信息:
- anchor位置(x,y,w,h)
- 相对偏移(dx,dy,dw,dh)
其中解码器queries可以看成是anchor位置的学习,而其与keys不稳定的匹配会导致不稳定的anchor,从而使得相对偏移的学习变得困难。因此,本文使用一个去噪 task作为快捷方式(shortcut)来学习相对偏移,它跳过了匹配过程直接进行学习。如果把query看作四维坐标,可以通过在真实框附近添加一个微小的扰动作为噪声,此时去噪 task目标是直接重建真实框而不需要Hungarian matching。

本文的主要贡献可以总结如下:
- 设计了一种新的训练方法来加速 DETR 训练。 实验结果表明,本文的方法不仅加速了训练收敛,而且训练结果明显更好——在所有检测算法中取得了最好的结果,并且可以很容易地集成到其他类似 DETR 的方法中。
- 从一个新颖的角度分析了 DETR 的缓慢收敛,并对 DETR 训练进行了更深入的理解。 设计了一个度量来评估二分匹配的不稳定性,并验证本文的方法可以有效地降低不稳定性。
- 本文进行了一系列消融研究来分析本文模型的不同组件的有效性,例如噪声、标签嵌入和注意力掩码。
方法
因为DAB-DETR是目前最强的模型之一,且它显式的把decoder query表示为四维坐标很适合添加去噪 training,本文建立在DAB-DETR的基础上实现了DN-DETR。
模仿Conditional DETR,之后的工作如DAB-DETR都把decoder query设计成了content query和position query。为了更大限度利用去噪训练,本文把content query输入为label embedding,对label也添加噪声进行重构。因为去噪只是一种训练方式,不会改变模型结构,只是在输入的时候做了一些改变,如下图所示,作者把decoder embedding表示为加了噪声的标签, anchor表示为加了噪声的目标框。对于DETR原始的匹配部分,添加一个 [Unknown] label来进行区分,anchor部分保持DETR的方式不变。

加了去噪之后模型的输入变为下图。原始DETR的匹配部分命名为Matching part,新加的denosing 部分命名为去噪 part。需要注意的是,去噪 part只需要在训练的时候加上,在inference的时候去噪 part会直接移除,和原始模型一样,因此inference的时候不会增加计算量,训练的时候也只需要加入微小的计算量(decoder 部分的denosiing part)。
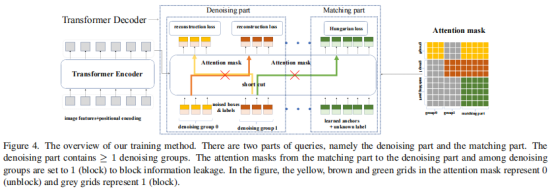
Denosing
label 噪声:本文以一定概率随机把真实label翻转为其余的任何一个label。如COCO中有80个类别,本文以一定概率将其翻转为80个中的其他label。加入label的方法类似NLP中的word embedding,把80个类别进行embedding即可。
box 噪声:box的噪声可以分为两类,即中心点漂移(center shifting)和框缩放(box scaling)。对于中心点漂移,本文可以保证中心点仍然在真实框内部并进行漂移。对于框缩放,可以随机缩放框的长和宽。漂移的强度和缩放的大小控制都由超参数进行控制。
Attention mask: 除了加噪声之外,在decoder的self-attention中需要加一个额外的attention mask防止信息泄露。因为去噪部分包含真实框和真实标签的信息,直接让matching part看到denosiing part会导致信息泄漏。因此,训练的时候matching part不能看到denosiing part,像原始模型一样训练。额外增加的denosiing part看或者不看到matching part对结果影响不大,因为denosing部分含有最多的真实框和标签。
实验
本文基于DAB实现了DN-DETR,基于Deformable DETR和DAB实现了DN-Deformable-DETR来进行实验,并在COCO上进行了实验。
50epoch setting:为了最大程度验证denoising training的提升,首先在标准的50epoch训练下做了完全相同setting下相比DAB-DETR在各个不同backbone上的提升。结果如下图
可以看到在收敛后denoising也能带来1.5-1.9的提升。
12epoch setting:为了验证denoising能够帮助模型在前期快速收敛,本文做了一个传统CNN detector经常做的实验12 epoch(在Detectron2中被称为3x)

可以看到denoising在前期可以加速收敛带来巨大提升。

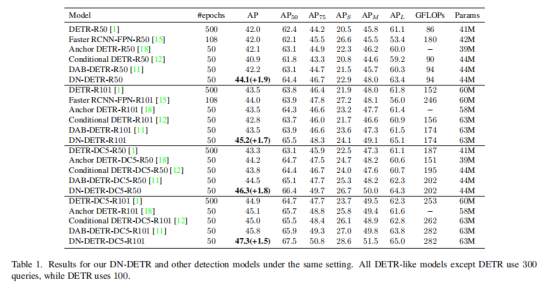
和SOAT模型相比:最后和SOTA模型进行了比较,提升依然显著。
参考
- https://arxiv.org/abs/2005.12872
- https://arxiv.org/abs/2201.12329
- https://arxiv.org/abs/2108.06152
- https://zhuanlan.zhihu.com/p/478079763
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢