
包括刘知远、唐杰、孙茂松等在内来自智源、清华的研究者对大模型的参数高效微调进行了全方位的理论和实验分析。
预训练语言模型 (PLM) 已经毫无疑问地成为各种 NLP 任务的基础架构,而且在 PLM 的发展中,呈现出了一个似乎不可逆的趋势:即模型的规模越来越大。更大的模型不仅会在已知任务上取得更好的效果,更展现出了完成更复杂的未知任务的潜力。然而,更大的模型也在应用上面临着更大的挑战,传统方法对超大规模的预训练模型进行全参数微调的过程会消耗大量的 GPU 计算资源与存储资源,巨大的成本令人望而却步。
这种成本也造成了学术界中的一种「惯性」,即研究者仅仅在中小规模模型上验证自己的方法,而习惯性地忽略大规模模型。
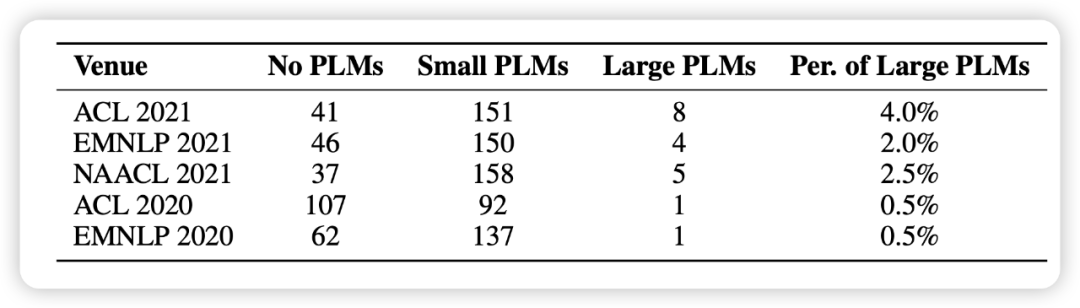
在近期论文《Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models》中,来自北京智源人工智能研究院、清华大学的研究者随机选取了 1000 篇来自最近五个 NLP 会议的论文,发现使用预训练模型已经成为了研究的基本范式,但涉及大模型的却寥寥无几(如下图 1 所示)。
-
论文地址:https://arxiv.org/pdf/2203.06904.pdf -
OpenDelta工具包:https://github.com/thunlp/OpenDelta
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢