
转自:OpenBMB
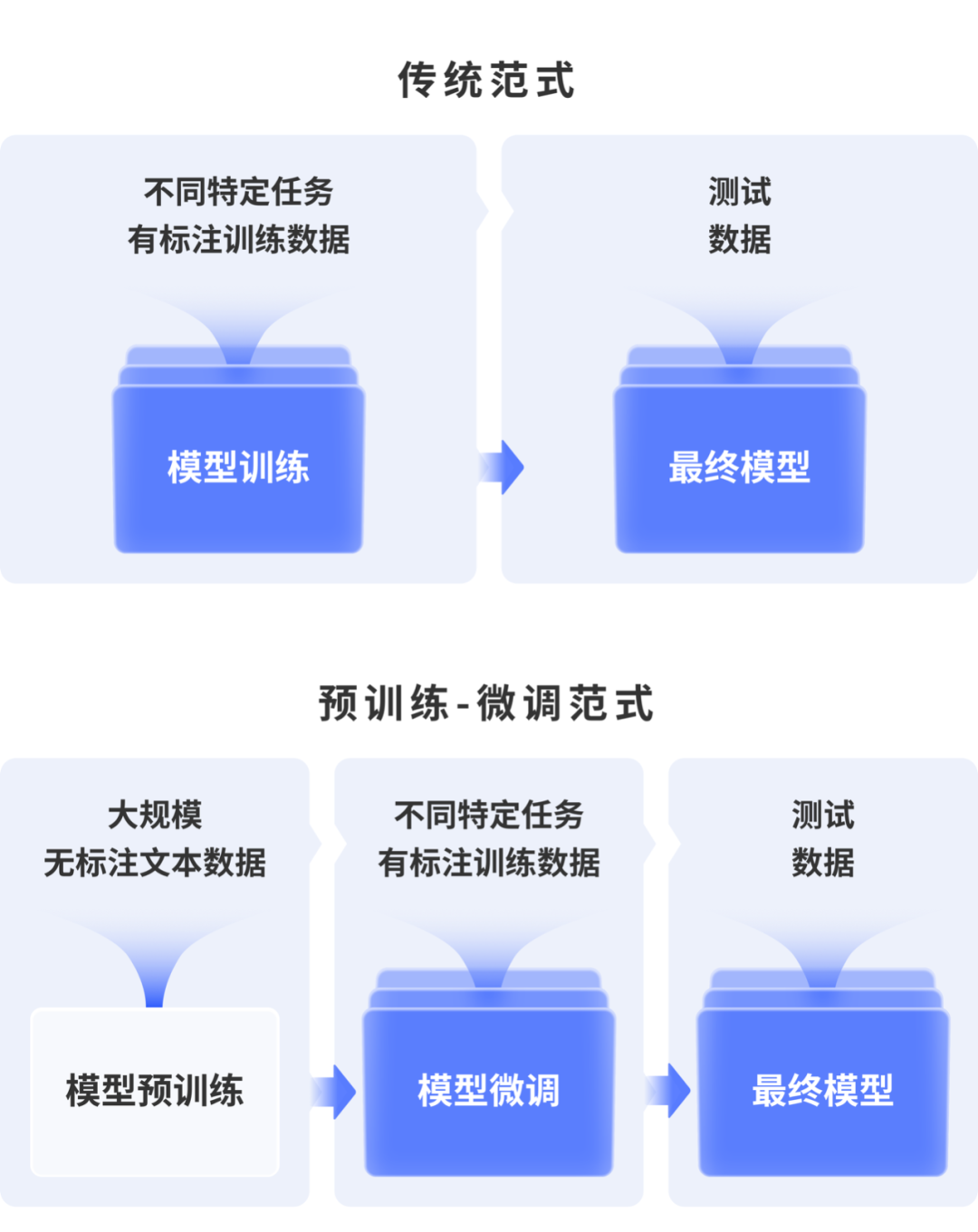
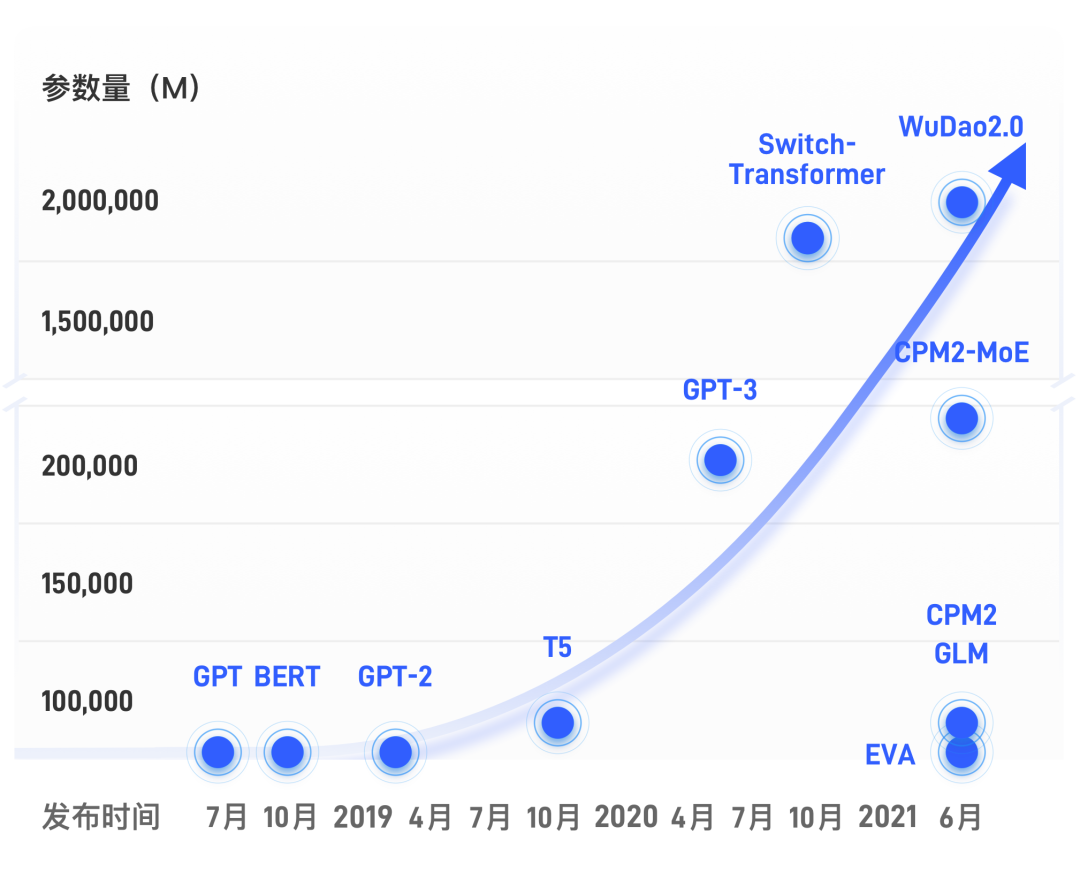
▶ 训练难:训练数据量大,算力成本高。
▶ 微调难:微调参数量大,微调时间长。
▶ 应用难:推理速度慢,响应时间长,难以满足线上业务需求。
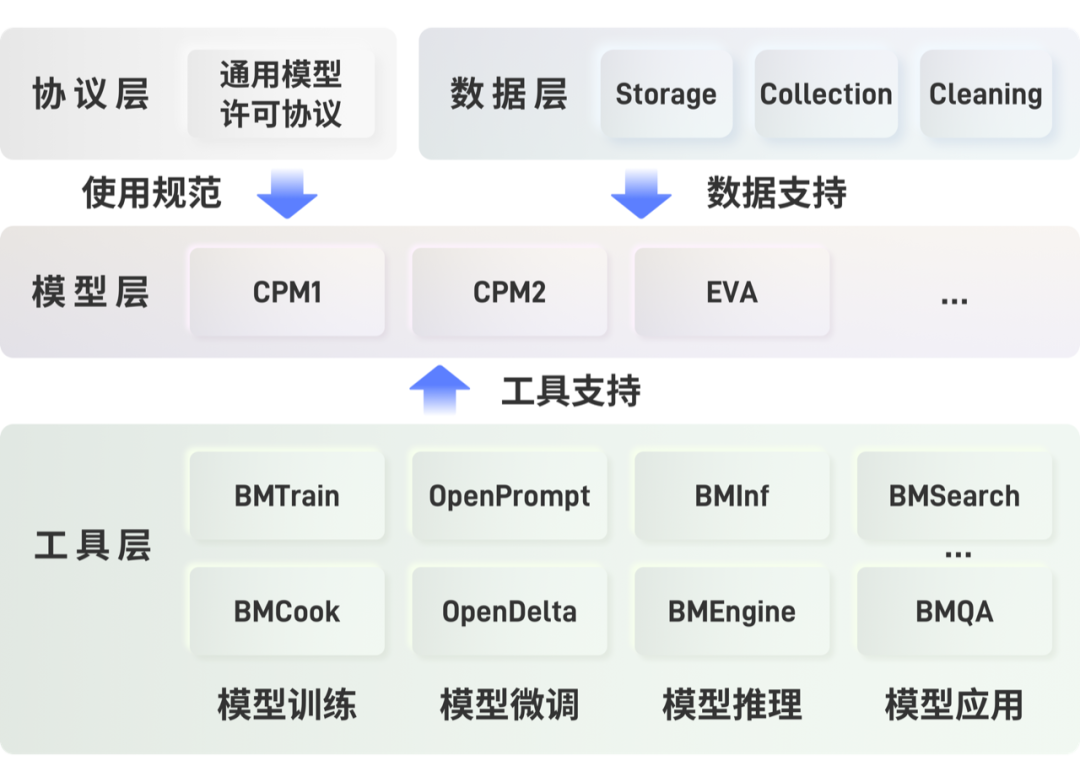
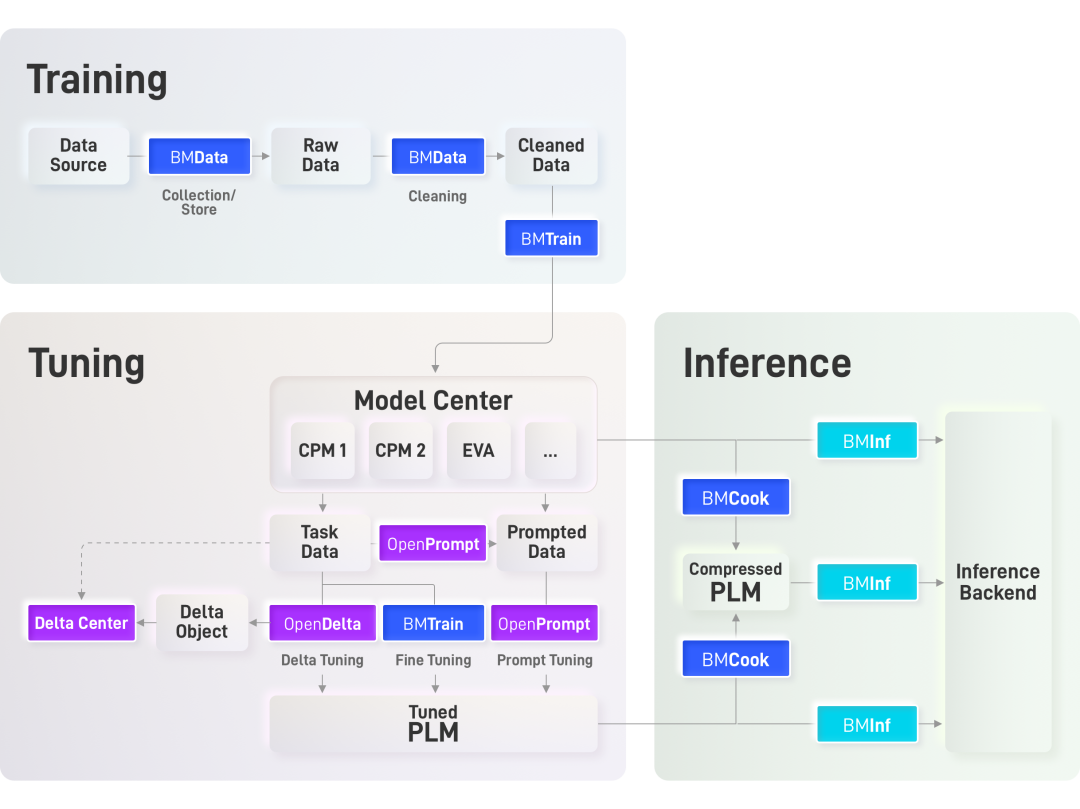
1. Zhengyan Zhang, Xu Han, Zhiyuan Liu et al. ERNIE: Enhanced Language Representation with Informative Entities. ACL 2019.
2. Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu et al. KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation. TACL 2021.
3. Yujia Qin, Yankai Lin, Ryuichi Takanobu et al. ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning. ACL-IJCNLP 2021.
4. Xu Han, Zhengyan Zhang, Ning Ding et al. Pre-Trained Models: Past, Present and Future. AI Open 2021.
5. Zhengyan Zhang, Xu Han, Hao Zhou et al. CPM: A Large-scale Generative Chinese Pre-trained Language Model. AI Open 2021.
6. Zheni Zeng, Yuan Yao, Zhiyuan Liu, Maosong Sun. A Deep-learning System Bridging Molecule Structure and Biomedical Text with Comprehension Comparable to Human Professionals. Nature Communications 2022.
7. Ning Ding, Yujia Qin, Guang Yang et al. Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models. Arxiv 2022.
8. Zhengyan Zhang, Yuxian Gu, Xu Han et al. CPM-2: Large-scale Cost-effective Pre-trained Language Models. AI Open 2022.
9. Ganqu Cui, Shengding Hu, Ning Ding et al. Prototypical Verbalizer for Prompt-based Few-shot Tuning. ACL 2022.
10. Shengding Hu, Ning Ding, Huadong Wang et al. Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification. ACL 2022.
11. Yujia Qin, Jiajie Zhang, Yankai Lin et al. ELLE: Efficient Lifelong Pre-training for Emerging Data. Findings of ACL 2022.
12. Yuan Yao, Bowen Dong, Ao Zhang et al. Prompt Tuning for Discriminative Pre-trained Language Models. Findings of ACL 2022.
13. Ning Ding, Shengding Hu, Weilin Zhao et al. OpenPrompt: An Open-source Framework for Prompt-learning. ACL 2022 Demo.
14. Han Xu, Guoyang Zeng, Weilin Zhao et al. BMInf: An Efficient Toolkit for Big Model Inference and Tuning. ACL 2022 Demo.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢