
论文链接:https://openreview.net/forum?id=VBZJ_3tz-t
代码链接:https://github.com/VITA-Group/Random_Pruning
随机剪枝可以说是在神经网络中获得稀疏性的最简单的方法。但无论是训练后剪枝还是训练前剪枝都被认为是最没有竞争力的。在本文中,我们想告诉大家一个可能违反直觉的发现,即训练前的随机剪枝可以取得很不可思议的表现。在没有任何精细的剪枝标准或精雕细琢的稀疏结构的情况下,我们凭经验证明,从头开始稀疏训练一个随机剪枝的网络可以匹配相同模型结构的稠密网络的性能。有两个关键因素促成了这种现象:
i) 网络规模很重要:随着网络变得越来越宽和越来越深,一个随机剪枝的稀疏网络的性能将迅速提高到与其等效的稠密网络的水平。在高稀疏率情况下这种现象依然存在;
ii) 为稀疏训练预先选择适当的层间稀疏率。
实验发现,同时满足这两个条件下,随机修剪得到的稀疏Wide ResNet-50可以取得和稠密Wide ResNet-50一样的在ImageNet数据集上的分类精度。
我们还观察到,这种随机修剪的网络在某些方面甚至优于原先的稠密网络,例如OoD detection(分布外检测)、不确定性预测和对抗鲁棒性。简而言之,本文用大量的实验结果说明了大规模稀疏训练的潜力可能比预期的要大得多,并且稀疏训练不仅使得模型更高效,还有其他附赠的好处。
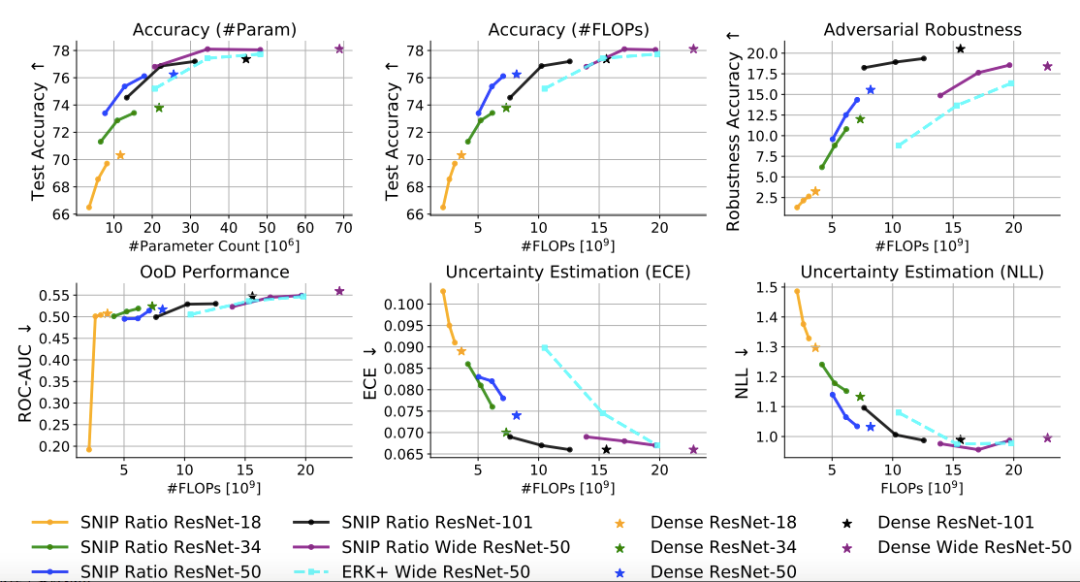
随着模型大小改变, ImageNet的测试精度
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢