
本文介绍『文心大模型』的一项最新工作:“地理位置-语言”预训练模型ERNIE-GeoL。

论文链接:https://arxiv.org/abs/2203.09127
01 实践中的观察
近年来,预训练模型在自然语言处理、视觉等多个领域都取得了显著效果。基于预训练模型,利用特定任务的标注样本进行模型微调,通常可以在下游任务取得非常好的效果。
然而,通用的预训练语言模型在应用于地图业务(如POI检索、POI推荐、POI信息处理等)时的边际效应愈发明显,即随着预训练语言模型的优化,其在地图业务中所带来的提升效果越来越小。其中一个主要原因是地理领域的信息处理过程往往需要与现实世界的真实地理信息建立关联。例如,在地图POI搜索引擎中,当用户输入一个query时,除了文本和语义匹配,候选POI的位置,以及它与用户当前所在位置的距离,都是非常重要的排序特征。而目前通用的预训练语言模型则缺乏可以建立『地理位置-语言』之间关联的训练数据以及预训练任务。
02 我们的创新:地理预训练模型ERNIE-GeoL
NLP预训练模型(如ERNIE 3.0)主要聚焦于语言类任务建模,跨模态预训练模型(如ERNIE-ViL)主要侧重于『视觉-语言』类任务建模。为了更好地学习『地理位置-语言』之间的关联,我们提出了地理预训练模型ERNIE-GeoL(Geo-Linguistic),主要聚焦于『地理位置-语言』类任务建模。
为了训练ERNIE-GeoL,我们引入了两类地理知识来增强预训练模型效果。第一类为地名知识,地名(toponym)主要指地理实体(如POI、街道和地区)的名称。第二类为空间知识(如下图所示),空间知识来自地图业务中常见的空间数据,主要包含单个地理实体的位置信息(通常以地理坐标形式表示),两个地理实体之间的空间关系(通常以三元组的形式表示),以及人类移动数据(通常以POI序列的形式表示)。
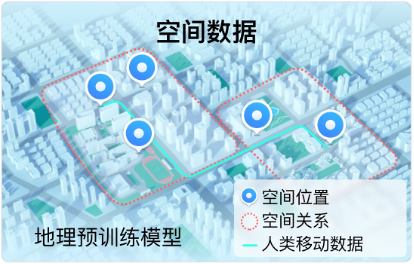
为了在预训练的过程中引入上述两类地理知识,需要解决以下两个挑战:1) 异构数据融合。蕴含地理知识的数据类型主要包含文本(包含地名知识)、三元组以及序列(包含空间知识)。如何将这些多源异构数据进行有效整合,并以统一的形式作为预训练模型的输入,是面临的首要问题。2) 『地理位置-语言』跨模态学习。现有的跨模态预训练大部分是对同一个概念的不同模态之间的关联进行学习。例如,在“视觉-语言”预训练中,主要目标是学习相同物体(如“一只猫”)的文本表示(如“可爱的猫”)和图像(如“猫的图片”)表示之间的语义关联。而在进行“地理位置-语言”预训练时,主要目标是学习一个地理实体(如“POI-ID1”)的文本属性(如该POI名称“北京西站”、POI地址“北京市丰台区莲花池东路118号”)与其对应地理坐标(该POI的经纬度)之间的关联。为了充分学习跨模态间的关联,需要设计有效的网络结构以及针对性的预训练目标。
为解决上述挑战,ERNIE-GeoL在预训练数据构建、模型结构以及预训练目标三个方面进行了针对性的设计和创新:
- 预训练数据构建
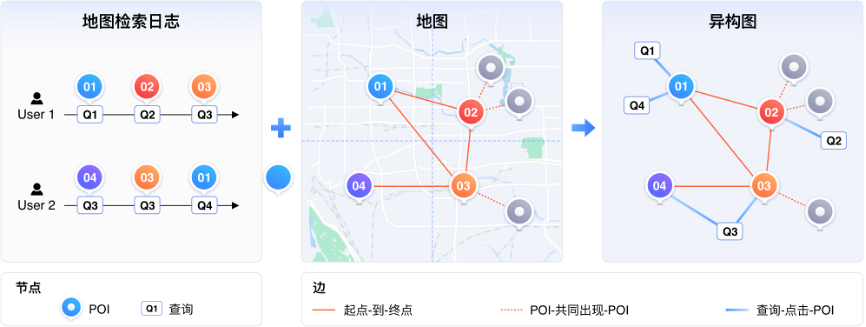
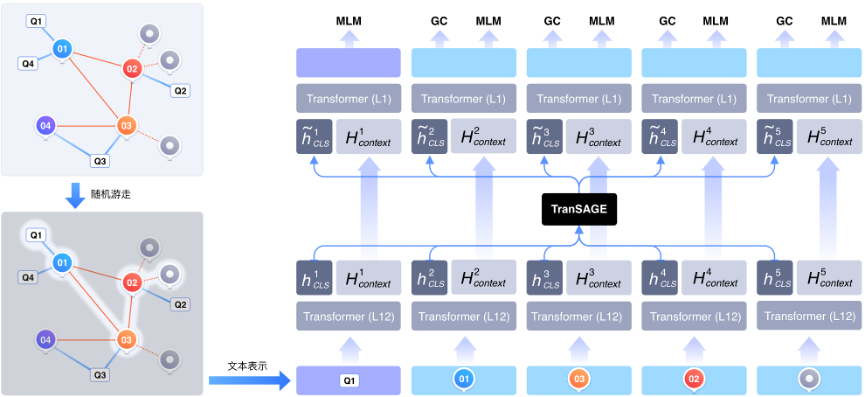
为了解决挑战1,ERNIE-GeoL以百度地图数据和POI数据库作为数据源,基于图桨PGL(Paddle Graph Learning),利用其中蕴含的空间关系构建了异构图。如下图所示,该图由两种节点(POI和查询)和以下三种不同类型的边构成:
1) 起点-到-终点,表示的是用户对两个地点的访达,蕴含了丰富的空间移动信息。
2) POI-共同出现-POI,表示共同出现在同一个地块内的两个POI,蕴含了空间共现信息。
3) 查询-点击-POI,来自于用户的地点查询日志,蕴含了丰富的地名和空间关系知识。
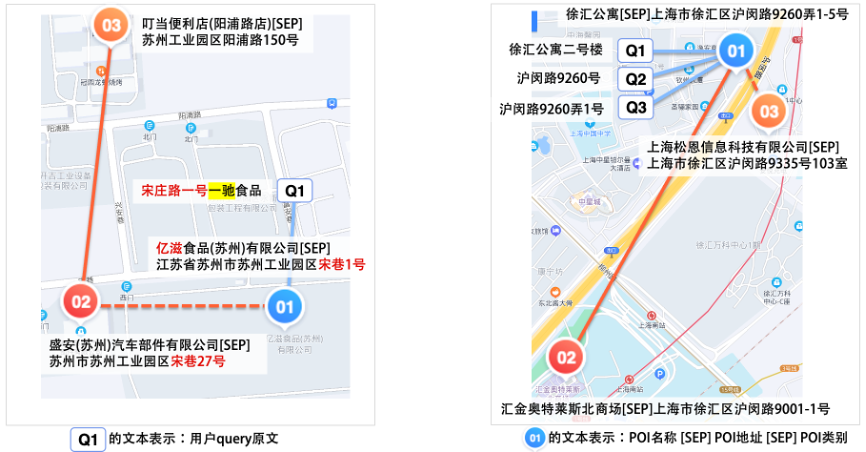
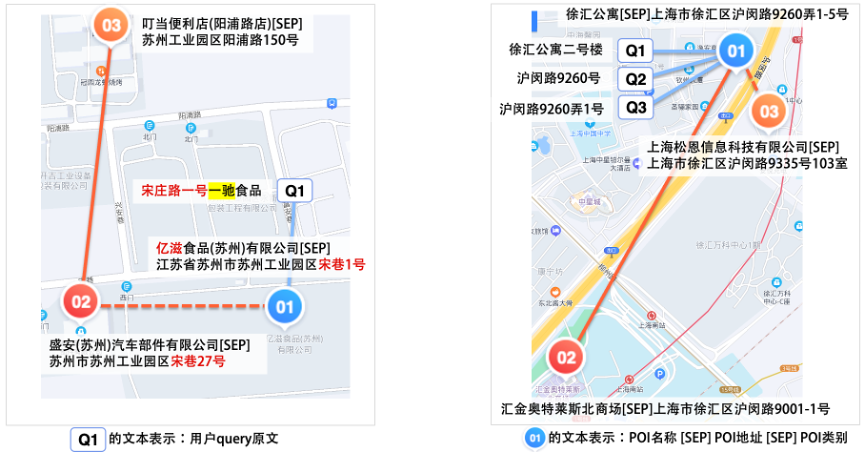
在此异构图的基础上,我们使用随机游走算法自动化地生成大量节点序列作为预训练数据。下面是两个真实的游走序列示例。
2.模型结构
以上述方式构建的数据蕴含了丰富的地理知识。为了更有效地从中学习地理知识,需要对其中的图结构进行充分建模。为此,我们在设计ERNIE-GeoL的模型结构(详见下图)时,专门引入了一个TranSAGE聚合层,用于充分学习训练数据中的图结构,同时将不同模态的数据映射到统一的表示空间。TranSAGE层使用多头注意力机制对每个节点的不同表示进行聚合,具体细节可参考文后所附论文。
3.预训练目标
为了让模型充分学习『地理位置-语言』间的关联,需要设计行之有效的预训练目标。为此,在用于学习地名知识的掩码语言模型(MLM)预训练任务之外,我们设计了用于学习文本与地理坐标关联的Geocoding(GC)预训练任务。
实现Geocoding,有两种候选方案:
1) 直接学习文本到经纬度坐标的映射关系。这种方案是回归任务,它的难点主要在于需要学习文本到唯一一个精确坐标的映射关系。若满足业务要求(误差<=20m),该坐标需要精确到小数点后4位,学习难度较大。
2) 将地图按一定范围划分格子,给每个格子编号,学习文本到编号的映射关系。这种方案是分类任务,优点是可以捕捉文本和编号间的关联,主要缺点是维度爆炸问题。例如,将全世界按4平方米的范围划分格子,会得到105万亿个编号。
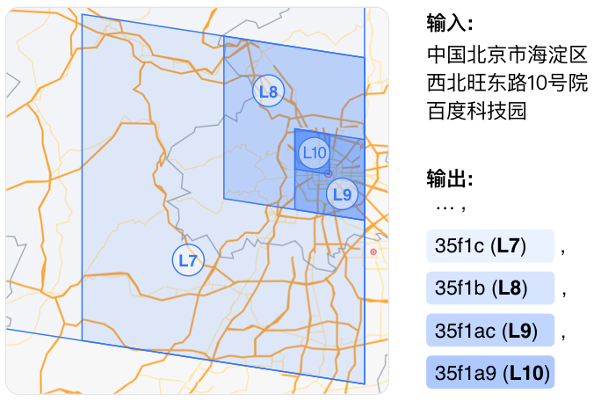
为了结合上述两种方案的优点并规避其缺点,我们选择让模型学习文本与其对应的地理实体所在的真实世界地块的多层级字符编码之间的关联。
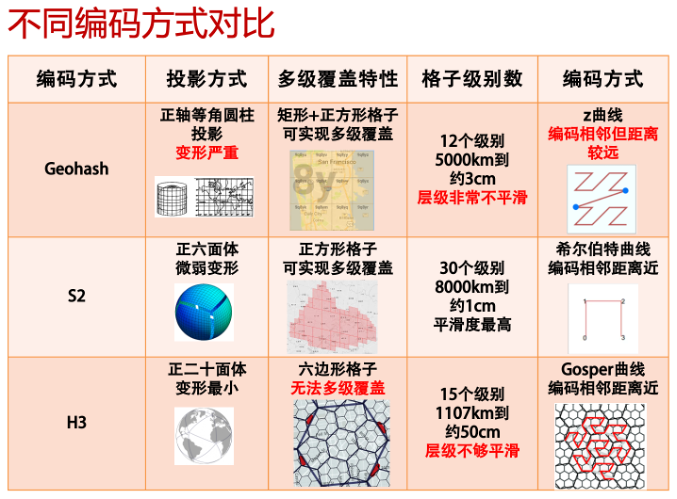
下图给出了该任务的一个示例,我们将百度科技园所在的不同层级的地块(L7至L10)表示成前缀互有关联的token(35f1c至35f1a9)。我们利用固定网格系统的地块编码方式获取其对应的token。固定网格系统是一类对地球表面按照固定位置划分格子的系统。大部分系统在进行划分时允许选择不同的层级,即用不同尺寸的格子对地表进行划分。按一种固定尺寸划分格子后,每个坐标点只落在一个格子内。我们从GeoHash、H3和S2 geometry这3种常见的固定网格系统(3种方案的具体对比见下图)中选择了S2。主要原因在于S2使用变形程度较小的球面投影方式,并具有以下特性:1) S2转换后的token层级最多;2) S2不同层级间的平滑度最高;3) S2可以实现多级覆盖,即子级别的token所代表的地块一定位于父级别的token所代表的地块之内。
依托多级覆盖特性,在训练的过程中,我们使模型按预测地块编码中每一个字符的方式一次性的预测出多个层级的地块表示。按这种方式,模型利用注意力机制可以学习到输入中描述不同层级地理概念的文本(如北京市、海定区、西北旺东路10号、百度科技园)和不同层级(如L6、L9、L15、L15)的地理编码的映射关系,从而使模型充分且高效地学习文本与地理坐标的关联,加强模型在处理不完整或不规范地理描述文本时的鲁棒性。具体训练方式详见论文。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢