

论文地址:https://arxiv.org/abs/2201.02973
代码/模型/实验结果:https://github.com/google-research/maxim
中文视频讲解:https://youtu.be/gpUrUJwZxRQ(非常详细,有很多背景介绍,新手友好型)
导读
Transformer与多层感知器(MLP)在计算机视觉任务中引发了新一轮的神经网络架构探索。尽管这些模型在图像识别等任务中均取得了有效的性能提升,但它们在low-level视觉任务中仍存在一些调整,例如对高分辨图像处理不灵活、无法捕获图像的局部信息。因此,来自谷歌的研究团队提出了一种名为MAXIM的多轴(multi-axis)MLP架构,它可以作为高效灵活的通用视觉骨干用于图像处理任务。MAXIM使用UNet的对称结构,并使用空间多变(spatially-gated)MLP进行长期以来的交互。具体来说,MAXIM 包含两个基于 MLP 的模块:一个multi-axis spatially-gated MLP以对局部和全局视觉线索进行高效和可扩展的混合,一个交叉门控块(cross-gating block),用于交叉特征调节。这两个模块都完全基于 MLP,但它们均具有图像处理模型所需的两个属性:全局卷积、全卷积。广泛的实验结果表明,所提出的 MAXIM 模型在超过 10 个基准测试中实现了最先进的性能,其所支持的图像处理任务包括去噪、去模糊、去雨、去雾和增强,同时比对比模型需要更少的参数和FLOPs 。
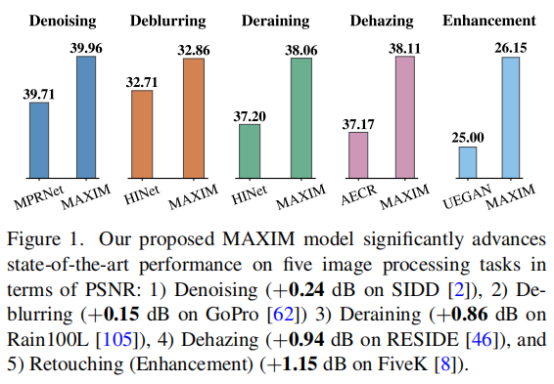
贡献
ViT, Mixer, MLP这些新的视觉网络掀起了一波与传统卷积神经网络(CNN)架构设计完全不同的模式转变(paradigm shift),即为「全局模型」(Global Models or Non-Local Networks)。这一设计模式使得模型不再依赖于长期以来人们对二维图像的先验知识(prior):平移不变性和局部依赖,而是使用全局感受野和超大规模数据预训练的强大建模能力。它们另一个重要的特性来自于注意力机制,即为能够自适应地对输入进行动态加权平均。
全局模型允许在输入的特征图上进行长期依赖的交互,即每个输出像素是由输入特征的每个点加权而来,需要O(N)次乘法。因此,输出整张大小为N的特征图需要O(N2)次乘法操作。因此,密集感受野的全局模型如 ViT, Mixer, gMLP 都具有平方计算复杂度。 这种高复杂度的大模型很难作为通用模块以广泛使用在底层视觉任务上的,例如需要在高分辨率上训练/推理的目标检测,语义分割等,甚至对于几乎所有的底层视觉任务如去噪、去模糊、超分、去雨、去雾、去雪、去阴影、去摩尔、去反射、去水印、去马赛克等。
为解决这一问题,华为北大等联手打造的IPT模型第一次把ViT模型应用在多个底层视觉任务,刷新了各大榜单并发表在CVPR 2021。虽然性能很好,但IPT使用的全局注意力机制具有一些明显的局限性:(1)需要大量数据预训练(如ImageNet),(2)无法直接在高分辨率图片上进行推理。在实际推理时,往往需要对输入图像进行切块,分别对每个图像块进行推理,然后再进行拼接来还原大图。这种办法往往会导致输出图片中有一些明显的“块状效应”,同时推理速度也比较慢,限制了其实际落地和部署能力。
为了克服这些问题,本文提出了一个通用的图像处理网络,称为 MAXIM,用于低级视觉任务。 MAXIM 的一个关键设计元素是使用多轴方法并行捕获局部和全局交互。 通过在每个分支的单个轴上混合信息,这个基于 MLP 的算子变得“完全卷积”并且相对于图像大小,这显着增加了其在密集图像处理任务中的灵活性。本文的主要贡献可以总结如下:
- 提出了通用的图像修复/增强任务骨干网络 MAXIM,第一次把最近爆火的 「MLP」[1]应用在底层视觉,在五大图像处理任务(去噪,去模糊,去雨,去雾,增强)超过10个数据集达到SOTA性能;
- 提出一个「即插即用」的多轴门限MLP模块(Multi-Axis gMLP block),实现了线性复杂度下的全局 / 局部的空间信息交互,解决了MLP/Transformer无法处理不同分辨率图片的痛点[2],并且具有全卷积[3]特性,为底层视觉任务量身定做,也可以应用在其他的密集预测任务(留给未来填坑);
- 提出另一个「即插即用」的交叉门控模块(Cross-Gating MLP block),可以无痛替代交叉注意力机制,并且同样在线性复杂度享有全局 / 局部感受野和全卷积特性。
方法
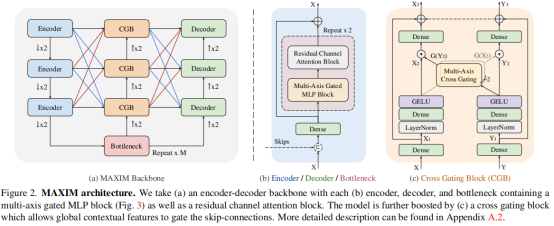
MAXIM架构如上所示,其具有一个对称UNet的基本结构,包含降采样的Encoder模块,最底层的Bottleneck, 和上采样的Decoder模块。其中,每一块Encoder/Decoder/Bottleneck均采用同样的设计如Figure 2(b):多轴门控MLP块(全局交互)和残差卷积通道注意力块(局部交互)。受启发于Attention-UNet,MAXIM在UNet的中间层加入了交叉门控模块(Cross-gating block),使用Bottleneck输出的高阶语义特征来调制编码器到解码器之间的跳跃连接特征。值得注意的是,MAXIM具有以下几个优点:
- MAXIM 在任意尺寸图片上都具有全局感受野,并且只需要线性复杂度;
- MAXIM 可以在任意尺寸图片上直接推理,具有“全卷积”属性;
- MAXIM 平衡了局部和全局算子的使用,使得网络在不需要超大数据集预训练的情况下达到SOTA性能。
多轴门控MLP模块(multi-axis spatially-gated MLP)
本文提出的多轴门控MLP模块是一个即插即用的并行模块,可进行全局/局部的空间交互,并且具有线性复杂度。受启发于HiT-GAN中提出的多轴自注意力模块可在低分辨率特征图上进行有效的全局/局部信息交互,作者认为多轴门控MLP模块要能够使用在高分辨率底层视觉任务上,同时需要具有“全卷积”属性。
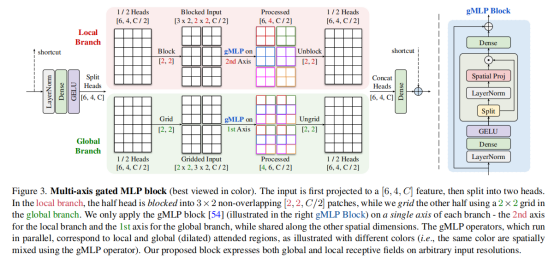
如上图所示,多轴门控MLP模块输入的特征首先进行通道映射,然后分成两个头,分别进行全局和局部交互。 其中一半的头进入局部分支(图中红色)使用 gMLP 算子在固定的窗口大小内进行局部空间交互;另一半头进入全局分支(图中绿色)使用 gMLP 算子在固定的网格位置进行全局空间交互。在两个并行分支结构中,每次只对固定维度的坐标进行操作,而在其他坐标都共享参数,从而实现了同时具有“全卷积”属性和全局/局部感受野。
交叉门控模块(cross-gating block)
受Attention-UNet启发,本文提出了交叉门控模块,如 Figure 2(c)所示。其设计理念与多轴门控MLP模块一致,同样采用多轴全局/局部交互的gMLP模块。唯一的区别是在提取了gMLP算子的空间门权重(gating weights) 后,采用了交叉相乘的方式来进行信息交互:
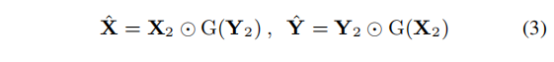
多阶段多尺度架构
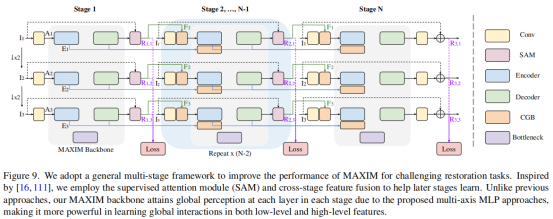
为了平衡性能-计算复杂度,MAXIM采用了一个改进的多阶段网络,并且采用了深度监督策略来监督多阶段多尺度的输出们。本文中针对不同的任务分别使用了2和3阶段网络:MAXIM-2S,MAXIM-3S。虽然MAXIM是多阶段网络,其仍然是可以进行端到端训练而不需要分步或渐进训练。在推理阶段,只需要把最后阶段的最大尺寸输出保留作为最终的结果即可。
实验
MAXIM旨在建立一个大一统的骨干网络可以适用于广泛的底层视觉/图像处理任务:
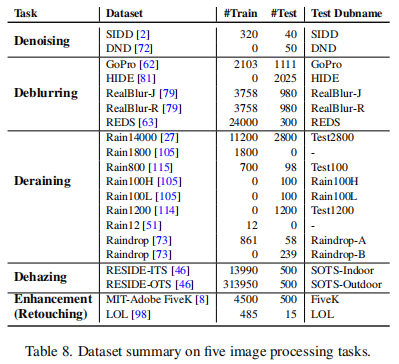
因为实验量巨大,接下来看看主要的实验结果,未尽部分请查看原文。
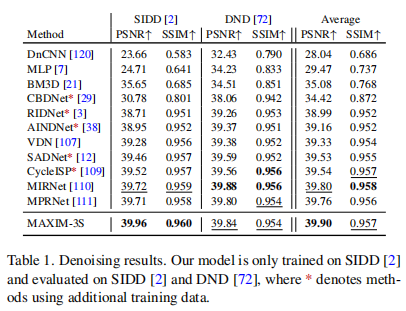
去噪(Denoising) on SIDD, DND 数据集
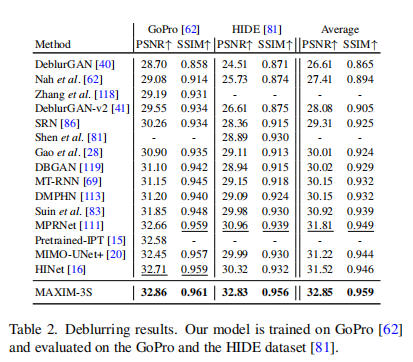
去模糊(Deblurring) on GoPro, HIDE,RealBlur,REDS数据集
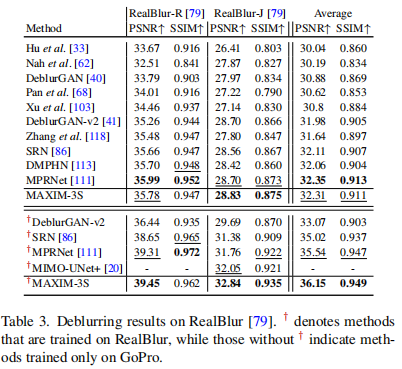
去雨(Deraining)on Rain100L, Rain100H, Test100, Test1200, Test2800, RainDrop数据集
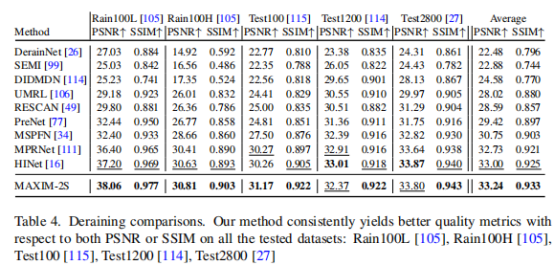
去雾(Dehazing)on RESIDE indoor,outdoor数据集
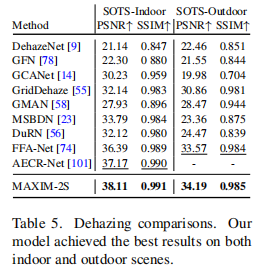
在SOTS的室内和室外套装上,MAXIM的模型比之前的最佳模型多出了0.94dB和0.62dB的PSNR。
增强(Enhancement)on MIT-Adobe FiveK,LOL数据集
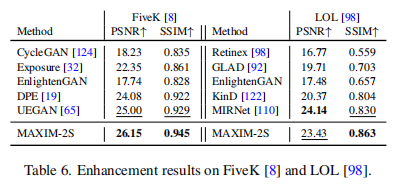
上图说明,MAXIM的不同模型分别在FiveK[8]和LOL[98]上获得了最佳的PSNR和SSIM值。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢