
【标题】Temporal Alignment for History Representation in Reinforcement Learning
【作者团队】Aleksandr Ermolov, Enver Sangineto, Nicu Sebe
【发表日期】2022.4.7
【论文链接】https://arxiv.org/pdf/2204.03525.pdf
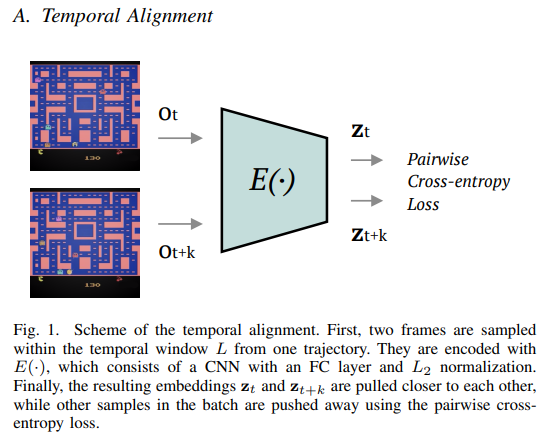
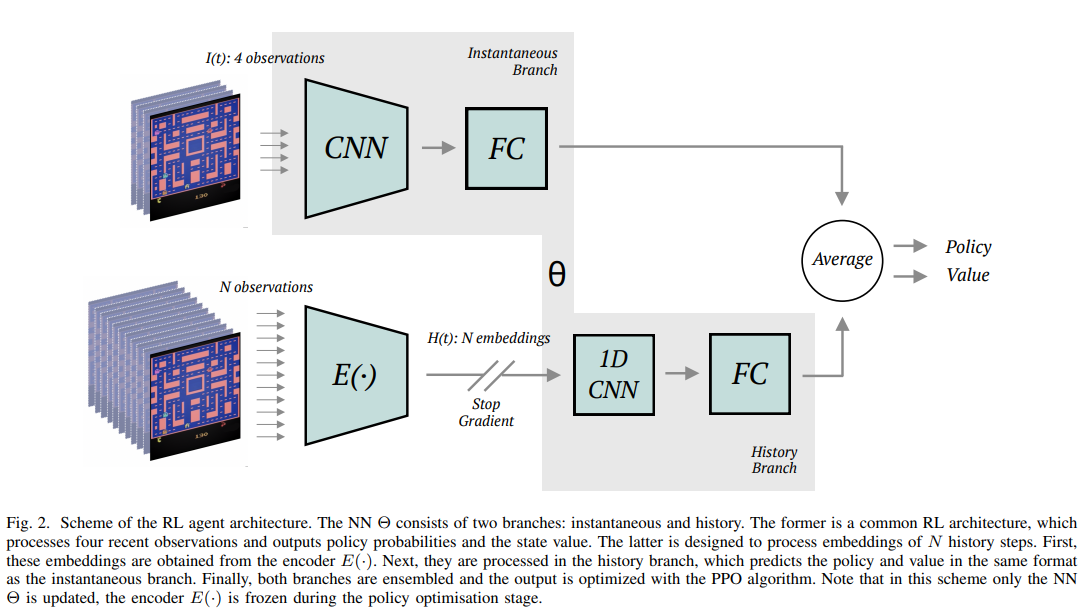
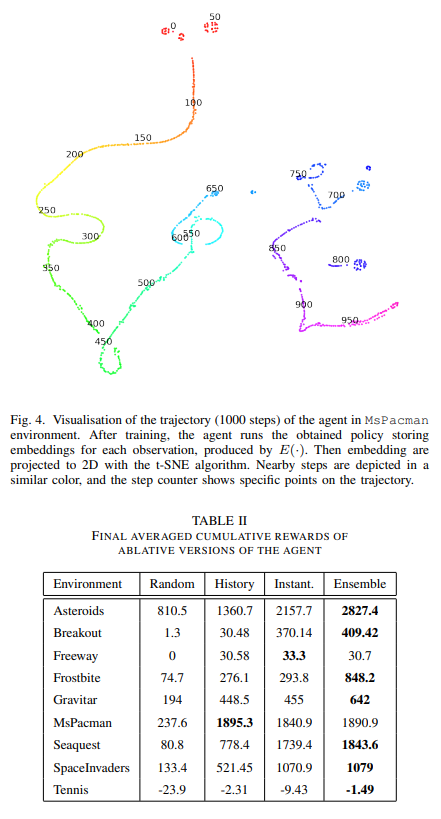
【推荐理由】强化学习中的环境通常只能部分观察到。为了解决这个问题,一个可能的解决方案是向智能体提供有关过去的信息。然而,提供对许多步骤的完整观察可能是多余的。受人类记忆的启发,本文建议只通过环境中的重要变化来表现历史,并且在该方法中,通过自监督自动获得这种表现。(TempAl)方法将时间上紧密的帧对齐,揭示了环境的一般、缓慢变化的状态。这一过程基于对比损失,它将附近观测值的嵌入相互拉离,同时将其他样本从批次中推离。它可以被解释为一个度量,捕捉观测的时间关系。我们建议结合常见的瞬时和历史表现,并在街机学习环境中评估所有可用的Atari游戏的TempAl。TempAl在49种环境中的35种环境中超过了瞬时唯一基准。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢