
【标题】Jump-Start Reinforcement Learning
【作者团队】Ikechukwu Uchendu, Ted Xiao, Yao Lu, Banghua Zhu, Mengyuan Yan, Joséphine Simon, Matthew Bennice, Chuyuan Fu, Cong Ma, Jiantao Jiao, Sergey Levine, Karol Hausman
【发表日期】2022.4.5
【论文链接】https://arxiv.org/pdf/2204.02372.pdf
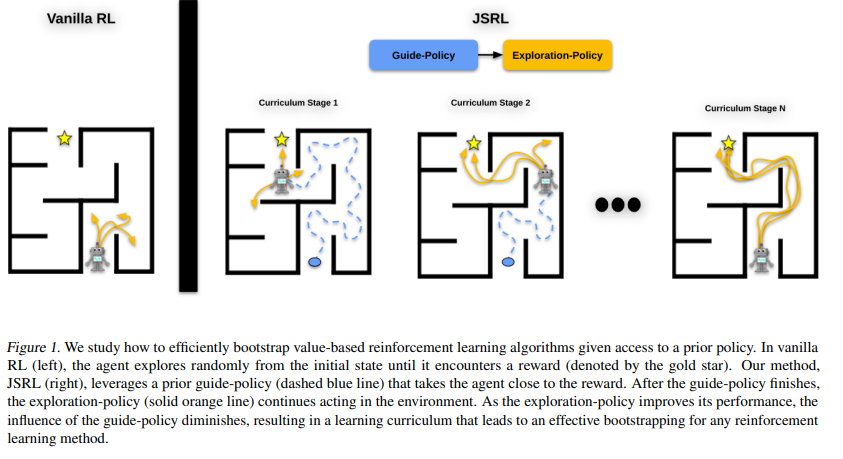
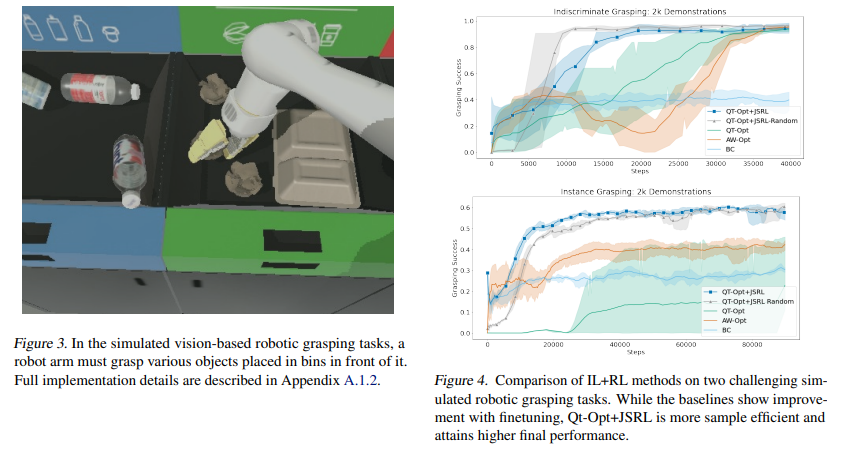
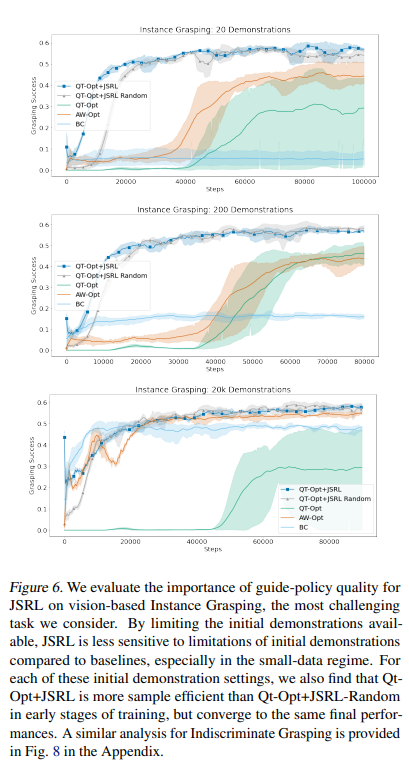
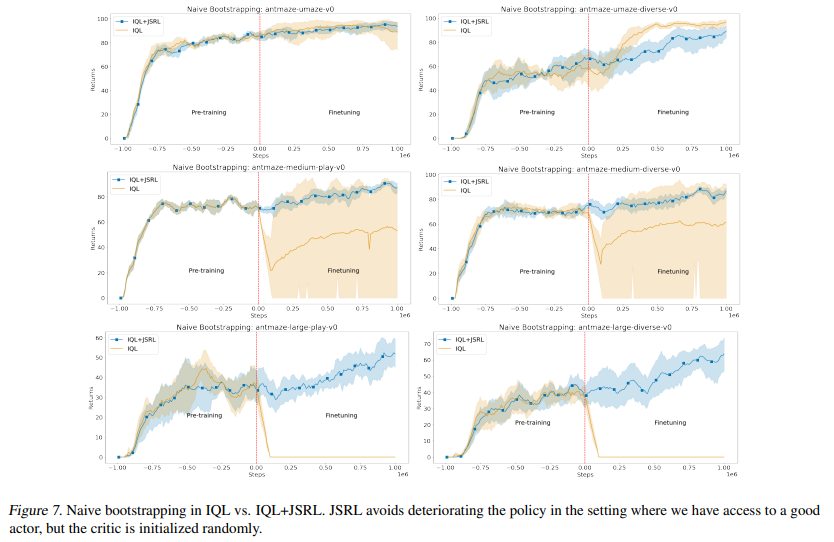
【推荐理由】强化学习(RL)提供了一个理论框架,通过通过反复试验持续改进智能体的行为。然而,从零开始有效地学习策略可能非常困难,尤其是对于具有探索挑战的任务。其可能需要使用现有策略、离线数据或演示来初始化RL。在RL中仅执行此类初始化通常效果不佳,尤其是对于基于值的方法。本文提出了一种元算法,它使用离线数据、演示或预先存在的策略来初始化RL策略,并且与任何RL方法兼容。并提出了 Jump-Start Reinforcement Learning(JSRL),通过使用两种策略来解决任务的算法:引导策略和探索策略。使用向导策略形成探索策略的起始状态课程,其有效地提高一组模拟机器人任务的性能。实验证明,JSRL能够显著优于现有的模仿和强化学习算法,尤其是在小数据区域。本文还提供了 JSRL 样本复杂度的上限,并证明了在引导策略的帮助下,可以将非乐观探索方法的样本复杂度从水平指数提高到多项式。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢