

- 单位:清华大学
- 项目主页:https://finediving.ivg-research.xyz/
- 代码仓库:com/xujinglin/FineDiving
- 论文:org/abs/2204.03646
导读
现有的动作质量评估方法大多依靠整个视频的深层特征来预测分数,这一做法造成了推理过程不透明,可解释性差等缺陷。本文认为,理解竞技体育视频中动作的高级语义和内部时间结构是使预测准确且可解释的关键。为此,本文构建了第一个新的细粒度数据集,称为 FineDiving,它针对各种跳水事件并对动作程序进行了详细注释。本文还提出了一种用于动作质量评估的过程感知方法,该方法通过一个新的时间分割注意模块学习得到。具体来说,上述方法将成对的查询和示例动作实例解析为具有不同语义的连续步骤和时间序列,并通过过程感知交叉注意来学习查询和示例步骤之间的特征嵌入,以发现它们的语义、空间和时间对应关系,并进一步用于细粒度的对比回归以获得可靠的评分机制。大量实验表明,本文的方法比最先进的方法实现了实质性改进,且具有更好的可解释性。
贡献
竞技体育已成为计算机视频理解领域的重要素材,作为理解体育动作的关键技术之一,动作质量评估(AQA,Action Quality Assessment)近年来受到越来越多的应用和关注。在2020年东京奥运会的体操比赛项目中,AI 评分系统不仅能对运动员的表现进行打分,以减少在跳水、体操等诸多主观评分项目得分的争议,还能通过反馈动作质量来提高运动员的竞技水平。
AQA是一个通过分析视频中动作表现来评估其执行质量的任务。与传统的动作识别、检测不同,AQA更具有挑战性:动作识别可以从一张或几张图像中识别一个动作,AQA则需要遍历整个动作序列来评估动作的质量,即AQA需要建模大量视频序列中的时序信息。因此,现有的大多数AQA方法都是通过视频的深度特征来回归式地生成不同动作的质量得分。以跳水视频为例,选手们都是唯一同一个跳水台所组成的环境中,这使得在相似背景下评估不同微小差异动作之间的质量非常困难。例如,跳水比赛通常都是在水上运动中心拍摄的,并且视频中所有运动员都执行相同的动作程式:起跳、空中动作、入水。这些动作程式的细微差别主要体现在执行空中动作时,运动员翻腾转体的周数、空中姿势以及入水情况(e.g., 水花大小)。捕捉这些细微的差异需要AQA方法不仅能够解析跳水动作的各个步骤,还要明确量化这些步骤的动作执行质量。如果AQA仅通过整个视频的深度特征来回归动作得分,考虑到现有的AQA数据集缺少对动作过程的细粒度注释,则无法分析各个动作步骤的执行情况、解释最终得分,那么这种评估方式是不清晰不透明的。
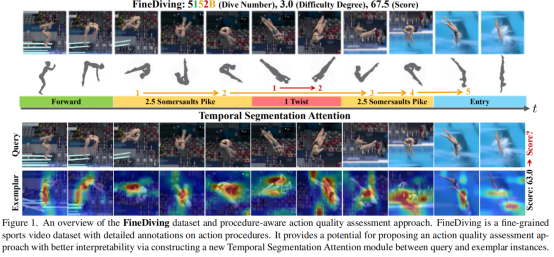
认知科学指出,人类能从通过精细的标注和可信赖的比较尝试去评价动作质量。受启发于此,本文构建一个细粒度的竞技体育视频数据集“FineDiving”,助力设计一种更可靠、更透明的评分方式。FineDiving包含如下特性:(1)两层语义结构。所有视频都在两个level上进行语义标注,即动作类型(action Type)和子动作类型(sub-action Type),其中,不同的action types由不同的sub-action types组合生成;(2)两层时序结构。每个视频中的动作实例都标注了时间边界,并且根据定义好的字典将其分解为连续的步骤(steps);(3)来自国际泳联的官方跳水得分(dive score)、裁判分数、难度系数。如图(1)所示。
基于FineDiving,本文进一步提出一种基于过程感知(procedure-aware)的AQA方法来评估动作质量。所提出的框架通过构建新的时间分割注意模块(Temporal Segmentation Attention,TSA)学习过程感知嵌入,以实现具有更好可解释性的可靠评分。首先,TSA将动作过程分割为成对的查询动作实例和参考动作实例解析为语义和时间对齐的连续步骤。其次,过程感知交叉注意通过学习发现成对query step和exemplar step之间的时空对应关系,并在这两个步骤中生成新特征。成对的步骤相互补充,以引导模型关注exemplar step和query step中的一致区域,其中,exemplar step保留了特征图的空间信息。最后,细粒度对比回归通过学习成对步骤的相对分数来量化查询动作实例和示例动作实例之间的一些列步骤偏差,以指导模型来评估动作质量。
本文的贡献可以总结如下:
- 提出了是第一个用于AQA任务的细粒度体育视频数据集FineDiving;
- 构建了一个新的TSA模块提出了一种过程感知动作质量评估方法;
- 大量实验表明,本文的方法比最先进的方法实现了实质性改进,且具有更好的可解释性。
方法
FineDiving数据集
为了构建FineDiving数据集,作者收集了奥运会、世界杯、世锦赛以及欧锦赛的跳水项目比赛视频。每个比赛视频都提供了丰富的内容,包括所有运动员的跳水记录、不同视角的慢速回放等。

FineDiving包含了两层语义结构(如上图)作为字典来标注动作级标签和步骤级标签。动作级标签(action-level labels)描述了运动员的动作类型(action types),步骤级标签(step-level labels)刻画了动作过程中连续步骤的子动作类型(sub-action types),其中,每个动作过程中的相邻步骤(steps)属于不同的sub-action types。例如,action type“5255B”,由sub-action types分别为“Back”、“2.5 Somersaults Pike”以及“2.5 Twists”的steps按顺序执行。
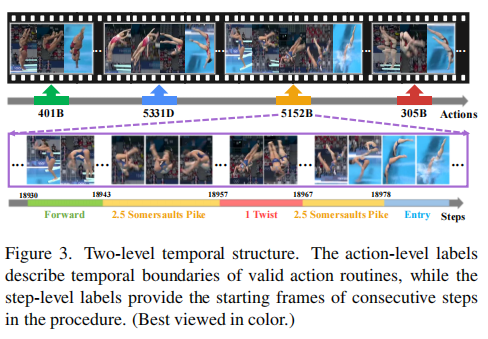
此外,它还包含一个两层时间结构(如图(3)),action-level labels标注了每个运动员执行一个完整动作实例的时间边界(在此注释过程中,丢弃所有不完整的动作实例并过滤掉慢速播放)。Step-level labels标注了动作过程中连续步骤的起始帧。例如,action type为“5152B”的动作实例,它的连续步骤的起始帧分别为18930、18943、18957、18967和18978。
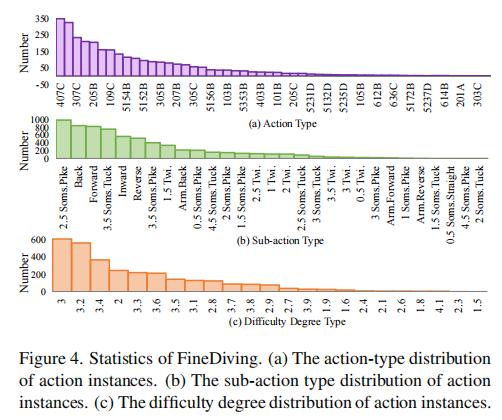
如上图所示,FineDiving数据集包含3000个样本,涵盖52种action types、29种sub-action types以及23种难度难度系数。
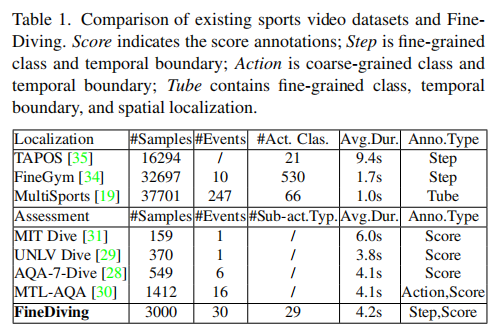
FineDiving在注释类型和数据规模上同样与现有的AQA数据集具有一定差别:MIT-Dive、UNLV以及AQA-7-Dive数据集仅提供动作分数,MTL-AQA提供粗粒度注释(即动作类型和时间边界),而FineDiving提供了细粒度注释(包括动作类型、子动作类型、粗粒度和细粒度时间边界以及动作分数)。此外,由于缺乏动作得分,其他细粒度的运动数据集不能用于评估动作质量。
时间分割注意模块(Temporal Segmentation Attention,TSA)
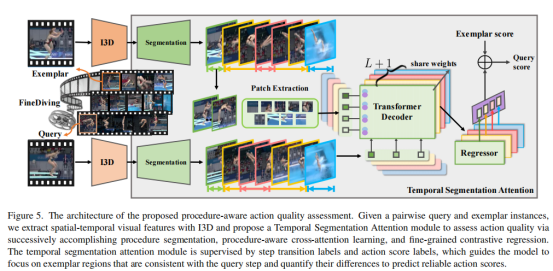
基于FineDiving,本文构建了一个新的时间分割注意模块(Temporal Segmentation Attention,TSA),以可解释的方式评估动作得分。TSA包含三个部分:动作过程分割(procedure segmentation),过程感知交叉注意(procedure-aware cross-attention)以及细粒度对比回归(fine-grained contrastive regression)。首先,动作过程分割将成对的查询动作实例和参考动作实例解析为语义和时间对齐的连续步骤。其次,过程感知交叉注意通过学习发现成对query step和exemplar step之间的时空对应关系,并在这两个步骤中生成新特征。成对的步骤相互补充,以引导模型关注exemplar step和query step中的一致区域,其中,exemplar step保留了特征图的空间信息。最后,细粒度对比回归通过学习成对步骤的相对分数来量化查询动作实例和示例动作实例之间的一些列步骤偏差,以指导模型来评估动作质量。
动作过程分割(procedure segmentation)
动作过程分割的目的是将成对的查询动作实例和参考动作实例解析为语义和时间对齐的连续步骤,它通过概率的方式实现。假设需要确定L个连续步骤,动作过程分割S通过预测在第t帧发生动作的概率p:
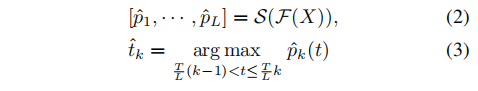
具体来说,本文使用时域卷积层和空域最大池化层实现动作过程分割(即上式中的S())。在训练时,使用如下交叉熵损失函数进行监督:
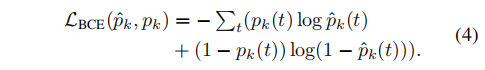
过程感知交叉注意(procedure-aware cross-attention)
过程感知交叉注意通过学习发现成对query step和exemplar step之间的时空对应关系,并在这两个步骤中生成新特征。成对的步骤相互补充,以引导模型关注exemplar step和query step中的一致区域,其中,exemplar step保留了特征图的空间信息。由此不难发现,上述成对query step和exemplar step类似于注意力机制中的query和key,因此,这一步骤可以直接用Multi-head Cross-Attention(MCA)、 MLP blocks、LayerNorm、残差连接实现:
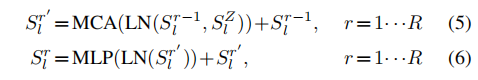
细粒度对比回归(fine-grained contrastive regression)
细粒度对比回归通过学习成对步骤的相对分数来量化查询动作实例和示例动作实例之间的一些列步骤偏差,以指导模型来评估动作质量:
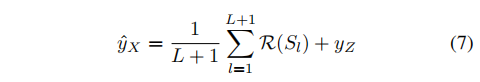
实验
本文的实验主要在所提出的FineDiving数据集上实现,作者首先给出了本文方法(TSA)与其他AQA方法的对比结果:
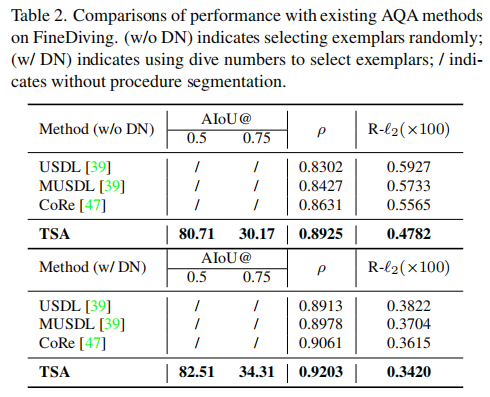
可以发现,本文的方法达到了最先进的水平。具体来说,与没有使用潜水数来选择样本(即w/oDN)的方法(USDL、MUSDL和CoRe)相比,本文的方法在Sperman等级相关性方面分别提高了6.23%、4.98%和2.94%。
作者同样给出了诸多消融实验的结果展示:
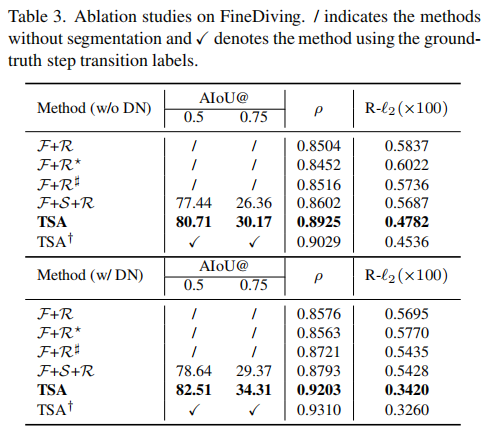
如表3所示,F+R的性能略好于F+R*,验证了对称训练策略的有效性。与F+R相比,F+R#在Sperman等级相关性上分别提高了0.12%和1.45%。同时,本文的方法在R-L2距离上也取得了0.0101和0.026的改进,证明了连接潜水数字和I3D特性可以实现积极的影响。
最后,作者给出了成对查询和参考示例之间的过程感知交叉注意的可视化对比:

结果表明,本文的方法可以专注于与查询步骤一致的参考区域,这使得逐步骤的动作质量相对差异的量化更加可靠。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢