
2021年是Prompt Tuning大放光彩的一年,众多针对预训练语言模型的Prompting方法涌现。这促使计算机视觉领域的研究者从Prompting方法中吸取灵感。近日,美国康奈尔大学、MetaAI等机构研究者提出了一种Visual Prompt Tuning的方法,让人们再次开始关注视觉领域的Prompt Tuning。
知识点
1.Visual Prompt Tuning可简单指代一切通过将提示等给到视觉模型,使其在学习领域数据后,性能超过微调的方法。
2.Visual Prompt Tuning当前面临的主要两个问题是:1)设计适合图像任务的Prompt;2)解决将Prompt输入视觉模型的方法。
3.Visual Prompt Tuning目前已在图文预训练和视觉预训练模型中取得进展,但目前已有的研究还比较少。
定义
Visual Prompt Tuning可简单指代一切通过将指令、提示等给到视觉模型,使其性能超过原始微调的方法。
Visual Prompt Tuning的思路和Prompt Tuning如出一辙,但Visual Prompt Tuning需要输入的提示和图像相关,需要研究者探索适合图像任务的Prompting方法。Prompt Tuning在NLP领域快速发展的一个原因是,研究者能够很容易根据下游的NLP任务,设计对应的Prompting方法(如设计的模板,让模型进行类似“完型填空”的学习)。但目前仍缺少针对图像下游任务的Prompting方法。
此外,如何将Prompt输入模型也是一个问题,需要解决和图像数据匹配和对齐问题。
Visual Prompt Tuning主要研究
1.针对图文预训练模型的Prompt Tuning方法
Prompt Tuning技术能够从图文模型逐渐切入视觉领域。研究者可以利用图文模型中需要学习的文本数据,添加Prompt,提升模型对于文本对应图像的感知和理解能力。
例如,在论文“CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models” [1]中,研究者首先对模型输入的图像进行了增强,采用不同色块分割了语义信息,并在设计文本描述和遮盖的过程中加入了Promp信息,使模型具备了描述不同色块语义的能力。
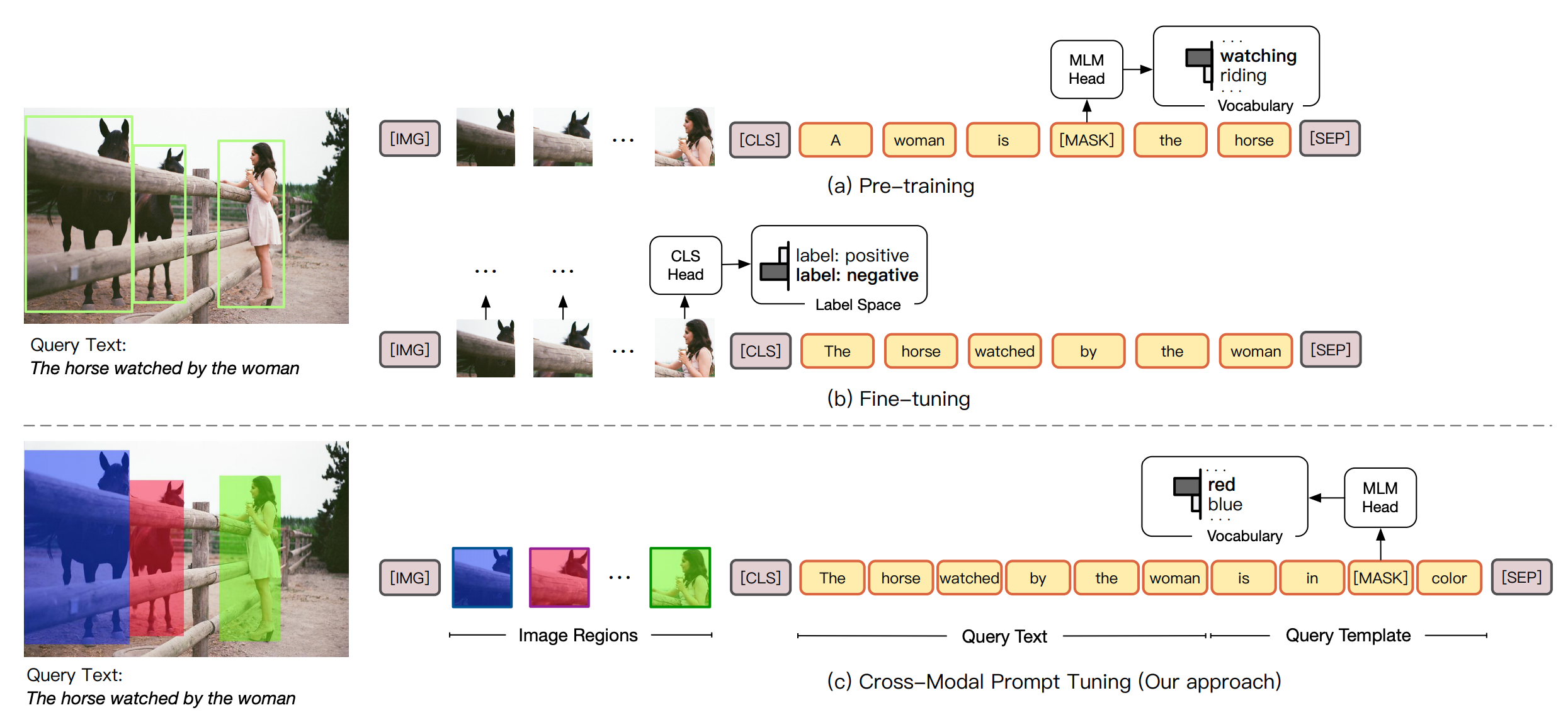
图注:CPT模型中,模型在遮盖部分需要补齐的信息中加入了Prompt,需要让模型选择合适色块的语义对象。

图注:此外,CPT也设计了根据文本中语境中的颜色信息,让模型对遮盖部分的行为进行选择的Prompt方法。
2.针对视觉预训练模型的Visual Prompt Tuning方法
将Prompt Tuning应用在视觉模型上的方法目前较少。近日,康奈尔大学、MetaAI、哥本哈根大学的研究者提出了Visual Prompt Tuning(VPT)的方法 [2],通过给视觉模型输入一组可学习的、针对下游视觉任务的参数(仅占模型规模的1%),并冻结模型的主干网络,只训练Head和可学习的参数部分,提升了模型在多种视觉任务上的性能。
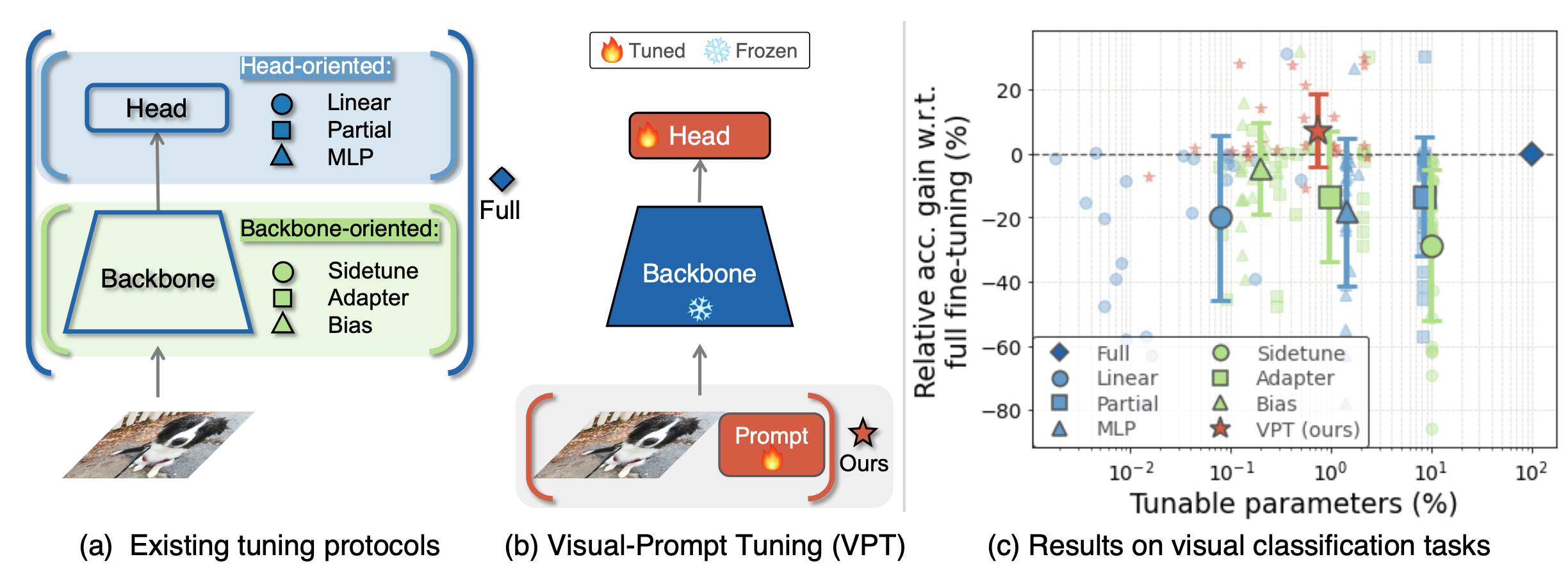 图注:VPT的基本思路
图注:VPT的基本思路
 图注:两种VPT方法:Deep(在每个Transformer层都加入Prompt)和Shallow(仅在第一层加入Prompt)
图注:两种VPT方法:Deep(在每个Transformer层都加入Prompt)和Shallow(仅在第一层加入Prompt)
参考链接
[1] Yao, Yuan, et al. "Cpt: Colorful prompt tuning for pre-trained vision-language models." arXiv preprint arXiv:2109.11797 (2021).
[2] Jia, Menglin, et al. "Visual Prompt Tuning." arXiv preprint arXiv:2203.12119 (2022).
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢