
近日,谷歌研究者提出一种名为「self-consistency」(自洽性)的简单策略,不需要额外的人工注释、训练、辅助模型或微调,可直接用于大规模预训练模型。
尽管语言模型在一系列 NLP 任务中取得了显著的成功,但它们的推理能力往往不足,仅靠扩大模型规模不能解决这个问题。基于此,Wei et al. (2022) 提出了思维提示链(chain of thought prompting),提示语言模型生成一系列短句,这些短句模仿一个人在解决推理任务时可能采用的推理过程。
现在来自 Google Research 的研究者们提出了一种称为「自洽性(self-consistency)」的简单策略,它显著提高了大型语言模型的推理准确率。

该论文的作者之一、Google Brain 的创始成员 Quoc Le 今天在推特上发文表示:这种自洽方法能够解决 GSM8K 基准中 75% 的数学问题,大幅超越现有方法。

图源:https://twitter.com/quocleix/status/1513632492124663808
简单来说,复杂的推理任务通常有多个能得到正确答案的推理路径,自洽方法通过思维提示链从语言模型中采样一组不同的推理路径,然后返回其中最自洽的答案。
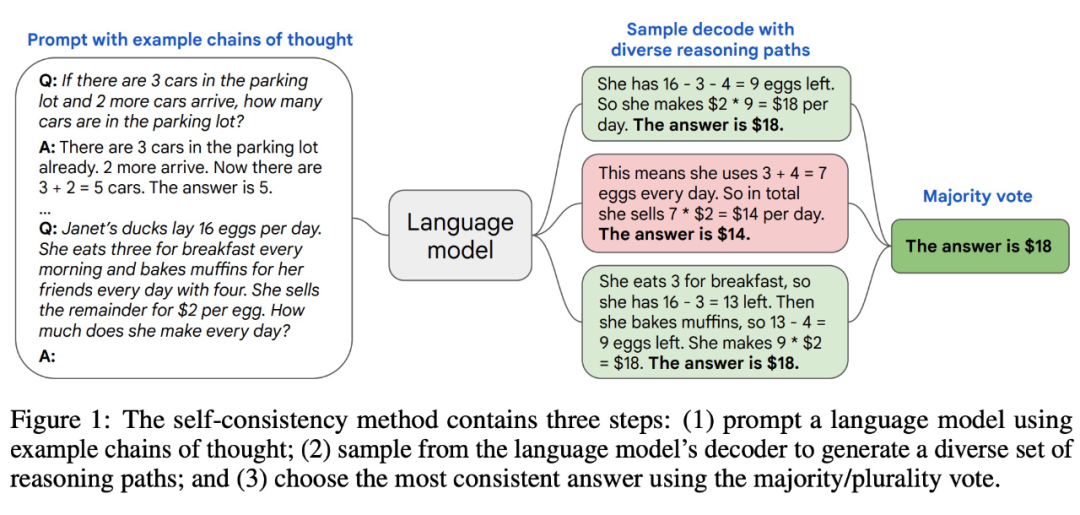
该方法在一系列算术和常识推理基准上评估自洽性,可以稳健地提高各种语言模型的准确性,而无需额外的训练或辅助模型。当与最近的大型语言模型 PaLM-540B 结合使用时,自洽方法将多个基准推理任务的性能提高到 SOTA 水平。
该方法是完全无监督的,预训练语言模型直接可用,不需要额外的人工注释,也不需要任何额外的训练、辅助模型或微调。
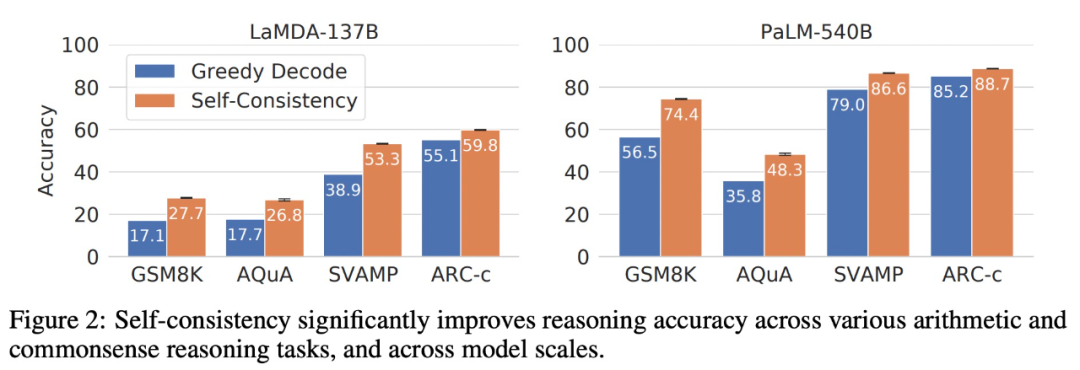
该研究在三种大型语言模型上评估一系列算术推理和常识推理任务的自洽性,包括 LaMDA-137B (Thoppilan et al., 2022)、PaLM-540B (Chowdhery et al., 2022) 和 GPT-3 175B (Brown et al., 2020)。研究者发现,对于这几种规模不同的语言模型,自洽方法都能显著提高其推理能力。与通过贪心解码(Wei et al., 2022)生成单一思维链相比,自洽方法有助于在所有推理任务中显著提高准确性,如下图 2 所示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢