

对于人类而言,将旋律和画面结合起来提升欣赏体验,是一种生而俱来的天赋。
但对于机器来说,这件事其实颇有挑战。
最近,中国人民大学高瓴人工智能学院GeWu实验室就针对这一问题提出了一种新的框架,让AI能像人一样观看和聆听乐器演奏,并对给定的视音问题做出跨模态时空推理。
目前这一成果已被CVPR2022接收并选为Oral Presentation,相关数据集和代码已经开源。
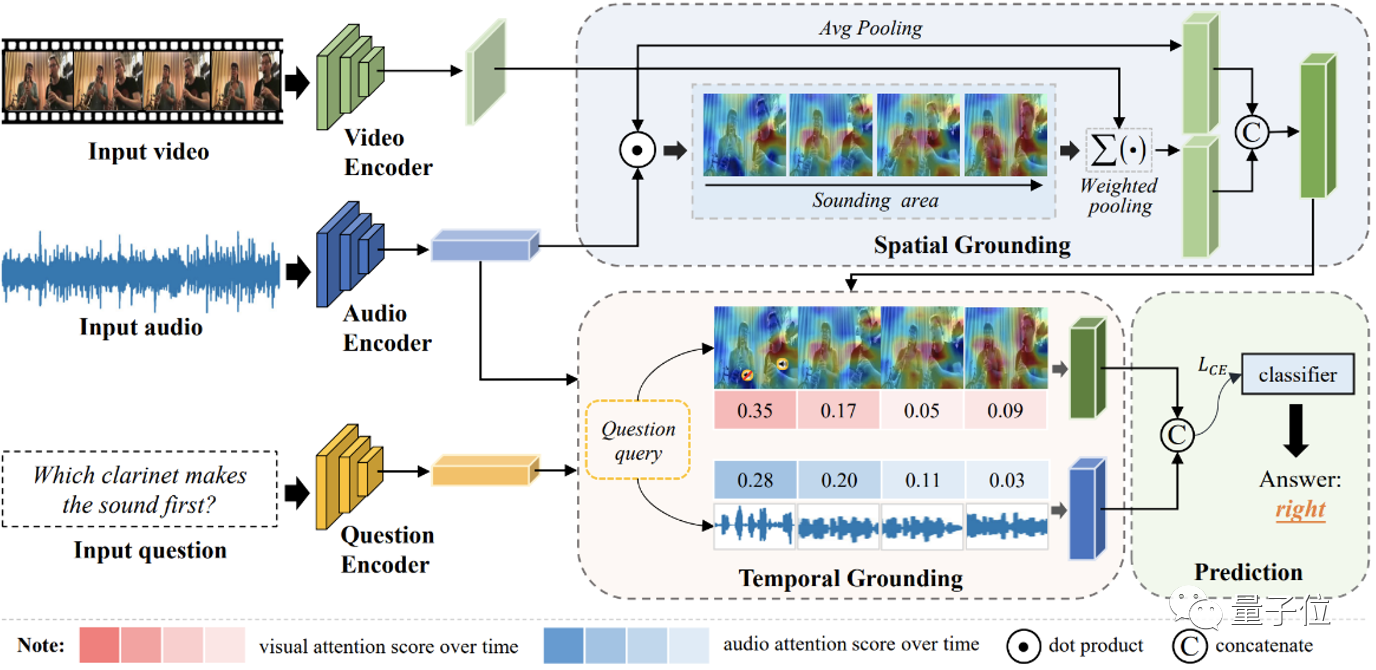
本文分别从空间和时序感知的角度出发,提出了一种动态视音场景下的空间-时序问答模型(如下图所示)。
项目地址:https://gewu-lab.github.io/MUSIC-AVQA/
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢