
作者:Thomas Wang, Adam Roberts, Daniel Hesslow,等
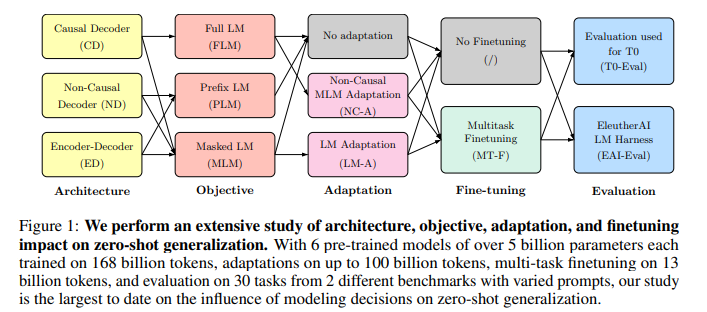
简介: 本文针对预训练语言模型进行零样本泛化方向的研究。大型预训练的Transformer语言模型已被证明具有零样本泛化能力,即它们可以执行各种各样的任务,而这些任务并没有经过明确的训练。然而,在最先进的模型中使用的架构和预训练目标存在显著差异,对这些因素的系统比较也有限。在这项工作中,作者对建模选择及其对零样本泛化的影响进行了大规模评估。特别是,作者关注文本到文本模型,并使用三种模型架构(仅因果/非因果解码器和编码器-解码器)进行实验,使用两种不同的预训练目标(自回归和掩蔽语言建模)进行训练,并在有和无多任务提示微调的情况下进行评估。作者为1700多亿个token训练了超过50亿个参数的模型,从而增加了作者的结论转移到更大范围的可能性。作者的实验表明,在完全无监督的预训练后,仅基于自回归语言建模目标训练的因果解码器模型表现出最强的零样本泛化能力。然而,在作者的实验中,对输入进行非因果可视性训练的模型在经过多任务微调后,表现最好。因此,作者考虑适应训练的模型跨架构和目标。作者发现,使用自回归语言建模作为下游任务,预训练的非因果解码器模型可以适应性能生成的因果解码器模型。此外,作者发现预先训练的因果解码器模型可以有效地适应非因果解码器模型,最终在多任务微调后获得具有竞争力的性能。
论文下载:https://arxiv.org/pdf/2204.05832.pdf
代码下载:https://github.com/bigscience-workshop/architecture-objective
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢