
作者:Gokul Karthik Kumar, Abhishek Singh Gehlot, Sahal Shaji Mullappilly, 等
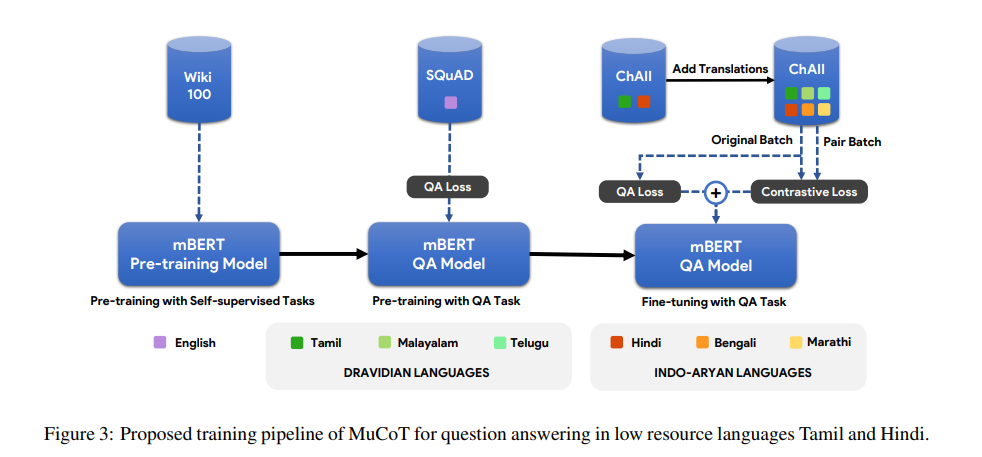
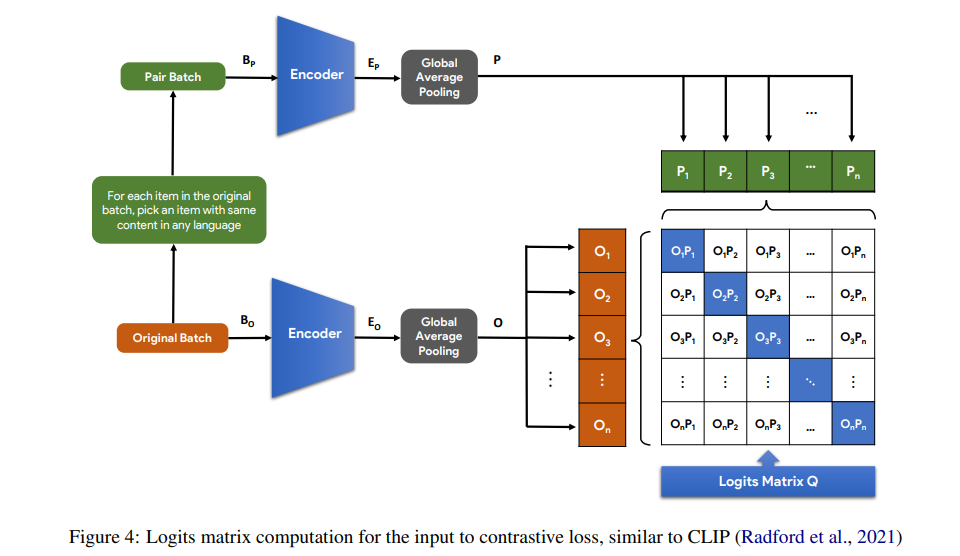
简介:近年来,随着基于Transformer的模型(如BERT)的出现,英语问答系统的准确性显著提高。这些模型以自我监督的方式进行预训练,拥有大量英文文本语料库,并通过大量英文QA数据集(如SHADK)进行进一步微调。然而,这种规模的QA数据集不适用于大多数其他语言。基于多语言BERT模型(mBERT)通常用于将知识从高资源语言转移到低资源语言。由于这些模型是使用包含多种语言的大型文本语料库预先训练的,因此它们通常学习来自不同语言的标记的语言未知嵌入。然而,由于缺乏训练数据,直接为低资源语言训练基于mBERT的QA系统具有挑战性。在这项工作中,作者通过将目标语言的QA样本翻译成其他语言,并使用增加的数据对基于mBERT的QA模型进行微调,该模型已经用英语进行了预训练。在Google ChAII数据集上的实验表明,使用来自同一语系的翻译微调mBERT模型可以提高问答性能,而在跨语系的情况下,性能会下降。作者进一步表明,在微调过程中,在翻译的问题-语境特征对之间引入对比损失,可以防止跨语言类翻译的退化、并导致边际改善。
论文下载:https://arxiv.org/pdf/2204.05814
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢