

论文链接:https://arxiv.org/pdf/2204.03883v1.pdf
代码链接:https://github.com/IDKiro/DehazeFormer
导读
图像去雾是一种具有代表性的low-level vision任务,它的目的是从有雾的图像中估计潜在的清晰图像。近年来,基于卷积神经网络的方法主导了图像去雾领域。然而,最近在高级视觉任务上取得突破的Vision Transformer似乎并没有为图像去雾领域带来新的研究潜力。本文从流行的 Swin Transformer 开始分析,发现其部分关键设计不适合图像去雾任务。为此,本文提出了 DehazeFormer,它由各种改进组成,例如修改后的归一化层、激活函数和空间信息聚合方案。作者在各种数据集上训练并对比了 DehazeFormer 的多个变体以证明其有效性。具体来说,在最常用的 SOTS 室内数据集上,DehazeFormer的小型模型仅以 25% 的参数量和 5% 的计算成本便可以超越FFA-Net。根据实验数据,本文提出的DehazeFormer大型模型是第一个在 SOTS 室内数据集上 PSNR 超过 40 dB 的方法,显著优于以前最先进的方法。本文还收集了一个大规模的现实遥感去雾数据集,用于评估该方法去除高度非均匀雾霾的能力。
贡献
雾霾是一种常见的大气现象,雾霾的存在不仅会降低场景的能见度,影响人们对物体的判断,还会影响日常生活和机器视觉系统,甚至会影响交通安全。 对于计算机视觉,雾霾在大多数情况下会降低图像的质量,影响模型在高级视觉任务中的可靠性,进一步误导自动驾驶等机器系统。这些现象使得图像去雾成为一项有意义的低级视觉任务。
图像去雾的目的是从有雾的图像中恢复潜在的清晰图像。早期研究将这一过程建模如下:
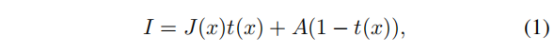
其中,I代表有雾图像,J代表清晰图像,A代表全局大气光,t代表传输率。从上式可以看出,图像去雾是一个病态的问题,即t与A有多重组合可以得到有雾图像I。因此,早期研究提出了若干先验来约束t与A的范围,这些基于先验的方法可以生成具有良好可见性的图像。然而,这些图像通常与无雾图像明显不同,并且可能在不满足先验的区域中造成不真实的表观。
近年来,基于深度学习的模型取得了显著的进展。然而,最近在高级视觉任务上取得突破的Vision Transformer似乎并没有为图像去雾领域带来新的研究潜力。为此,本文展开了一系列研究,证实中Vision Transformer常用的 LayerNorm 和 GELU 会损害图像去雾性能。
具体来说,视觉Transformer中使用的LayerNorm分别对图像patch对应的token进行归一化,导致patch之间的相关性丢失。 因此,本文移除了多层感知器 (MLP) 之前的归一化层,并提出 RescaleNorm 来代替 LayerNorm。 RescaleNorm 对整个特征图进行归一化,并重新引入归一化后丢失的特征图的均值和方差。 此外,SiLU / Swish和 GELU 在高级视觉任务中表现良好,但 ReLU在图像去雾方面的表现优于它们,作者认为这是因为它们引入的非线性在解码时不容易反转,且图像去雾不仅需要网络编码具有高度表现力的特征,还要求这些特征能够易于恢复为图像域信号。
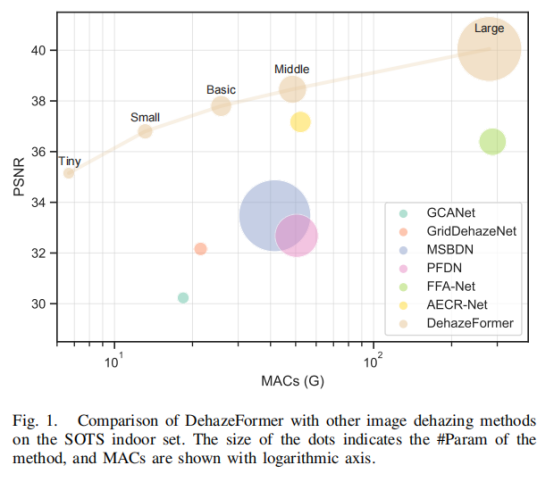
此外,作者还发现Swin Transformer中带有循环移位的窗口分区对于图像去雾中的图像边缘修复不是最优的选择。因此,提出了一种基于反射填充和裁剪的移位窗口分割方案,它允许 多头注意力机制丢弃掩码并实现恒定的窗口大小。此外,本文提出了一个基于先验的软重建模块和一个基于 SKNet [45] 的多尺度特征图融合模块,并构建了多个类似 U-Net 的图像去雾模型。本文还收集了一个大规模的现实遥感去雾数据集,用于评估该方法去除高度非均匀雾霾的能力。 图 1 显示了 DehazeFormer 与其他图像去雾方法在 SOTS 室内集上的比较。 DehazeFormer的小模型以 25% 的#Param 和 5% 的计算成本击败了 FFA-Net [18]。 据我们所知,DehazeFormer的大型模型是第一个超过 40 dB 的方法,大大优于此前提出的方法。
方法
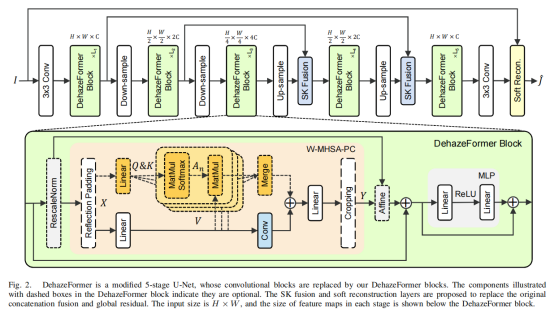
DehazeFormer是一个基于Swin Transformer的改良模型,其提升之处体现在其中的正则化层、非线性激活层、空间信息叠加机制、拼接融合与全局残差学习机制。
Rescale Layer Normalization
正则化层能够稳定深度模型的训练过程,因此LayerNorm在Transformer模型中属于重点组件之一,其操作定义如下:
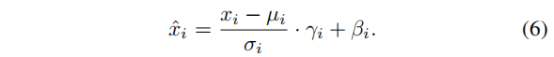
其中x表示输入特征,μ、σ表示沿着channel维度的均值与方差,后两者为可学习的参数。作者认为μ、σ为别与图像的亮度与对比度相关,因此,LayerNorm会带来上述信息的丢失,并通过图3中的实验进行了简单验证。

为解决这一问题,作者提出了Rescale Layer Normalization,操作定义如下:
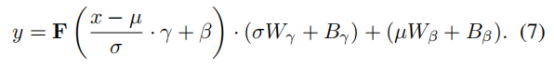
W、B表示全连接层的权重与偏置。与LayerNorm不同,Rescale Layer Normalization计算出的平均值和标准差被保存下来,并在残差块的最后引入。
Nonlinear Activation Function with Simple Inversal
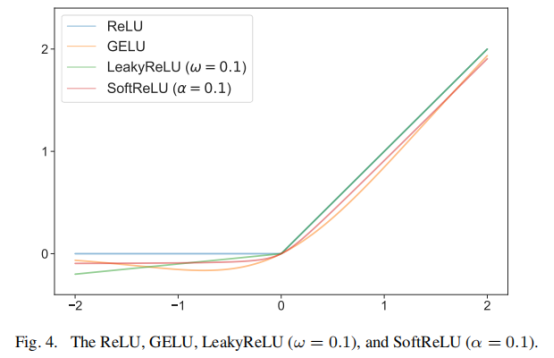
在high-level视觉模型中,GELU比ReLU具有更普遍的应用,但本文发现后者更适用于去雾任务(见下图),其原因可能是前者的非线性能力过于强大。因此,作者提出了一种平滑的ReLu层:
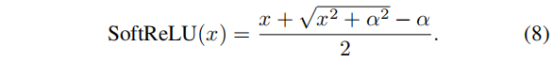
当α等于0时,上式退化为普通的ReLU操作。
Shifted Window Partitioning with Reflection Padding
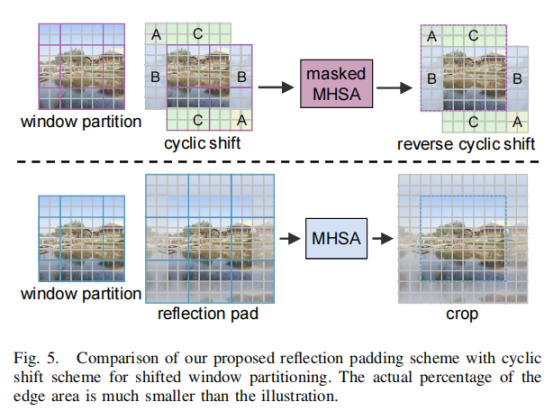
Swin Transformer 使用带有掩码 MHSA 的循环移位来实现移位窗口分区的高效批量计算,使得图像边缘的窗口尺寸小于设置的窗口尺寸。 对于高级视觉任务,目标对象通常位于图像的中心,使得图像的边缘像素对结果的贡献很小。 对于图像去雾,图像边缘与图像中心一样重要,较小的窗口大小会导致窗口中的令牌数量较少,这会使网络的训练产生偏差。 为了避免引入不合理的inter-patch交互,作者建议使用反射填充来实现移位窗口分区的有效批量计算,具体方式如下图:
模型结构
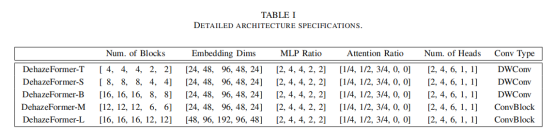
下表给出了DehazeFormer五种变量的具体配置,其参数量从上到下依次递增。
实验
本文的实验是在RESIDE数据集[52]和RS-Haze数据集上进行。
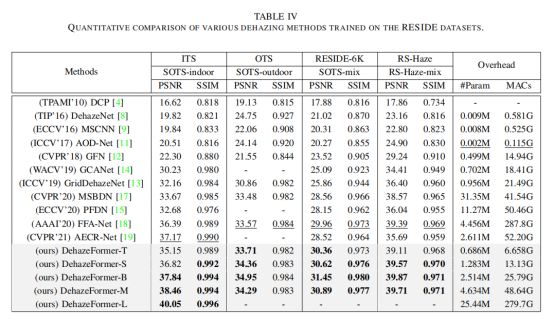
作者首先定量比较了 DehazeFormer 和基线模型的性能,结果如表 IV 所示。 总体而言,本文提出的 DehazeFormers 优于这些基线模型。其中, RESIDE-Full 室内集主要衡量模型处理高频信息的能力,室外集主要衡量模型的收敛速度。 RESIDE-6K 测量模型的稳定性以及提取低频信息的能力。 RS Haze 测量网络提取语义特征的能力。 值得注意的是,DehazeFormer-B 有时优于 DehazeFormer-M,这表明在这些实验设置中,注意力机制比卷积更为关键。
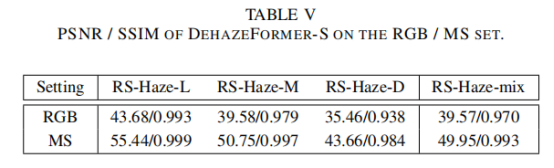
此外,DehazeFormer-S在RGB和MS图像上的比较如表v所示。如预期的那样,致密雾比轻雾更难去除。此外,更多信道和更大的比特深度提供的附加信息大大提高了该方法的性能。

作者从SOTS混合集合的不同场景中选择4个样本来评估网络的去雾性能,包括合成的室内和室外雾霾。可以观察到,几乎所有的比较方法都不能有效地去除雾霾。然而,DehazeFormer-S很好地恢复清晰的图像,保持纹理和颜色信息,包含最少的雾残留。

GCANet、PFDN、FFANet在雾霾较薄时可以有效去除雾霾,如图8前两行所示,但在颜色和细节再现方面不如DehazeFormer-S。此外,DehazeFormer-S可以去除密集的雾霾,而其他所有网络产生明显的伪影。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢