
【标题】Modularity benefits reinforcement learning agents with competing homeostatic drives
【作者团队】Zack Dulberg, Rachit Dubey, Isabel M. Berwian, Jonathan D. Cohen
【发表日期】2022.4.13
【论文链接】https://arxiv.org/pdf/2204.06608.pdf
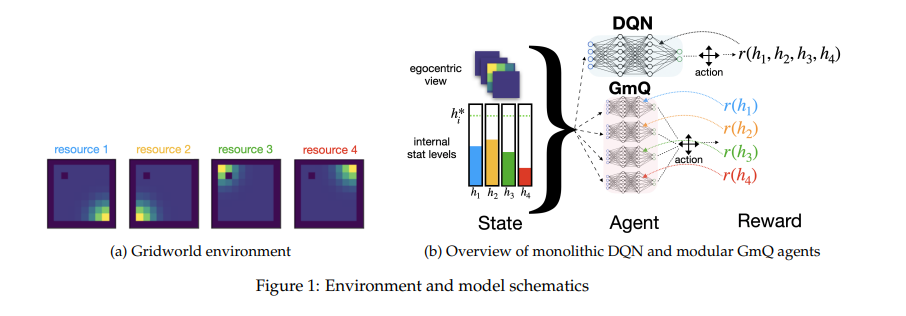
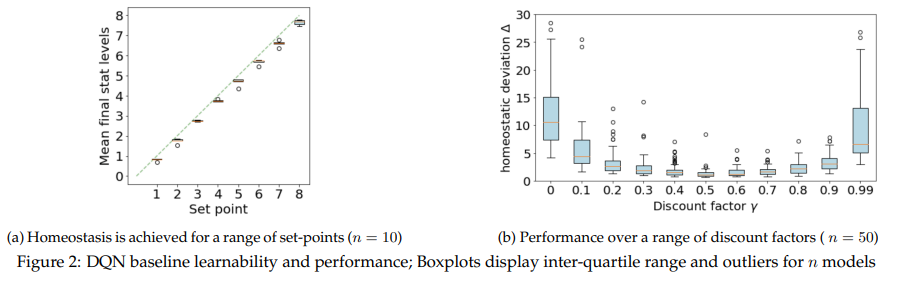
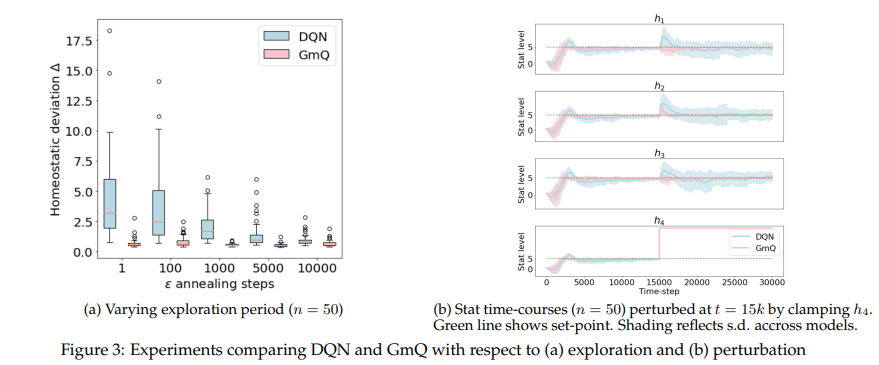
【推荐理由】平衡冲突需求的问题是智力的基础。标准强化学习算法最大化标量奖励,这需要将不同的目标特定奖励组合成一个数字。或者,不同的目标也可以在行动价值的层面上进行组合,这样负责不同目标的专家模块向决策过程提交不同的行动建议,每一个都基于相互独立的奖励。本文探讨了这种替代策略的潜在好处。并研究了一个与生物学相关的多目标问题,即一组变量的持续稳态,并将单一深度 Q 网络与每个变量都有专用 Q 学习器的模块化网络进行比较。研究发现模块化智能体:a)需要最少的外源性探索;b) 提高了采样效率;c)对域外扰动更具鲁棒性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢