

论文链接:https://arxiv.org/abs/2105.09996
项目链接:https://github.com/pytorch/fairseq/tree/main/examples/MMPT
摘要
我们提出了一种简单的、任务无关的多模态预训练方法,可以接受视频或文本输入,或同时接受视频或文本输入,用于各种最终的下游任务。现有的预训练是针对特定任务的,通过采用需要两种模态的单一交叉模态编码器,这限制其用于检索式任务,或采用两个单模态编码器进行更复杂的多任务学习,这限制早期交叉模态融合。
相反,我们引入了新的预训练mask方案,可以更好地跨模态混合(例如,通过强制文本mask来预测最近的视频嵌入),同时保持可分性(例如,有时只需要单模态预测,而不使用所有输入)。
实验结果表明,与之前的任何方法相比,本文提出的VLM在更广泛的任务范围内表现出色,通常优于特定任务的预训练。
Motivation
我们研究了在多模态视频理解中实现任务无关预训练的挑战,以最近的单模态方法为基础。尽管某些语言模型在NLP任务上接近于任务不可知,但由于文本视频检索等跨模态任务,在多模态任务上不可知任务更具挑战性。
现有的视频和语言预训练是特定于任务的,它们采用(1)需要跨模态推理(例如视频字幕)的任务的单个跨模态编码器,或(2)多个单模态编码器/解码器,来结合需要单独嵌入每个模态的特定任务。相反,我们提出了一种称为视频语言模型(video language model,VLM),证明了任务无关模型的预训练是可能的,该模型可以接受文本、视频或两者作为输入。
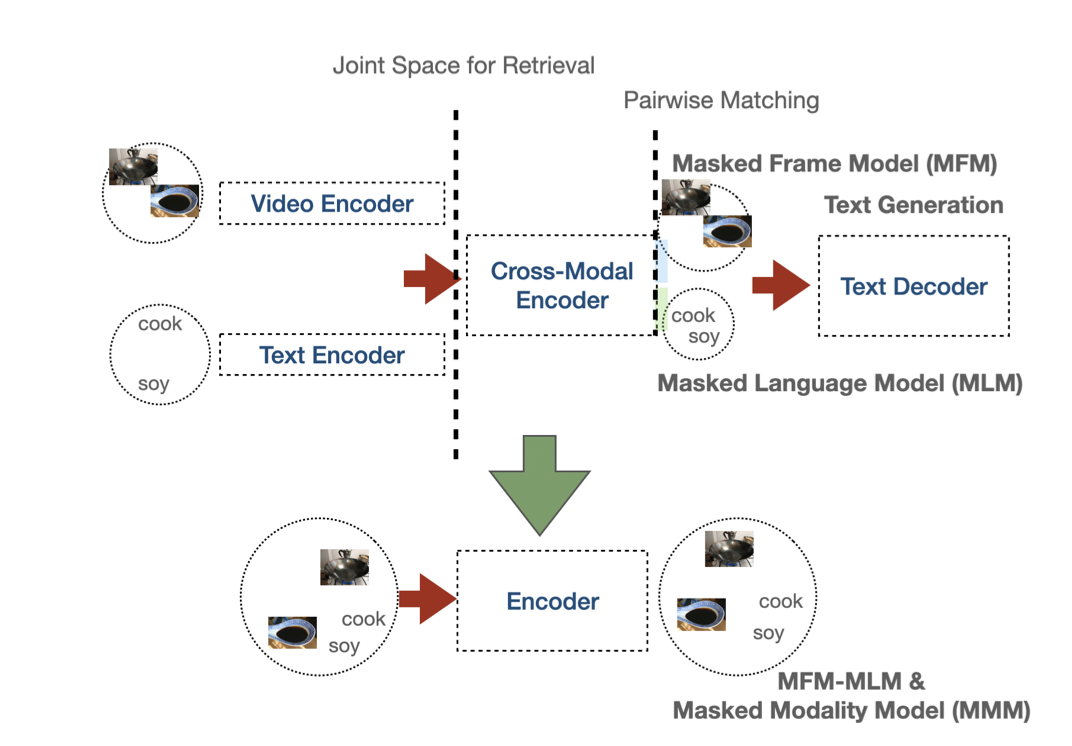
如上图所示,这种与任务无关的单一编码器方法有几个优点:(1) 它通过多种损失和模型降低了预训练的复杂性;(2) 与基于检索的预训练相比,它对接近下游任务的假设较少,并且与经典LMs一样通用(3) 它鼓励模态间的特征共享,而不具有很强的可分性;(4) 它的参数效率更高。下表总结了最新模型的设计选择。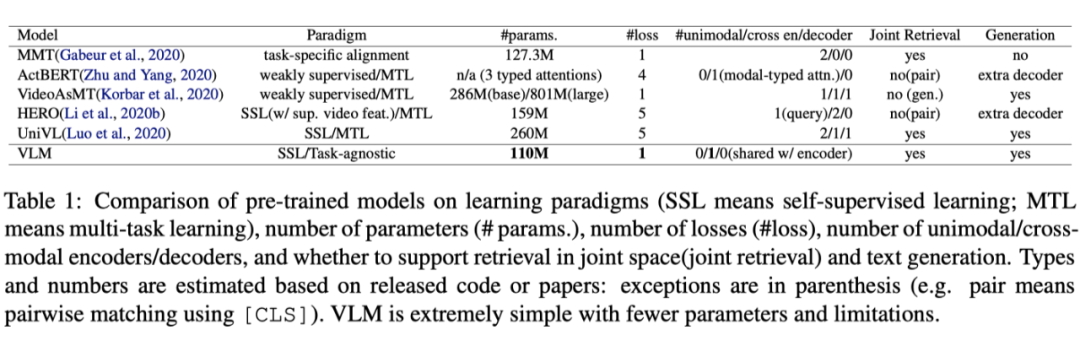
我们的编码器是一个Transformer块,结合了现有的mask帧模型和mask语言模型(MFM-MLM),并用两种改进多模态融合学习的新方法。首先,我们引入了一种称为mask模态模型(MMM)的mask方案,该方案为一部分训练样本(其余样本用于传统的MFM-MLM)随机样本整个模态,从而迫使编码器使用来自另一模态的token来生成mask模态的token。
然后,我们引入一个masked token loss,以分别替换MFM-MLM在视频和文本上的两个丢失函数。masked token loss使用视频和文本token的嵌入来学习编码器的联合隐藏状态。
我们还展示了通过使用任务特定的注意掩码来为广泛的任务调整单个编码器是可能的。实验表明,与以前的模型相比,它在更大范围的任务上表现良好,包括在检索任务和视频字幕方面,它比具有类似超参数的单峰编码器的特定任务预训练baseline的表现要好2%以上。与以前的方法相比,这些结果也是通过一个小得多的模型实现的,进一步证明了改进的融合方法和跨模态共享的有效性。
综上所述,本文的主要贡献如下:(1)提出了一种用于视频理解的任务无关编码器的预训练方案;(2) 我们引入了mask模态模型(MMM)和masked token loss,用于预训练的跨模态融合,无需牺牲可分性;(3) 实验结果表明,所提出的简单baseline以显著较少的参数实现了具有竞争力的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢