

论文链接:https://arxiv.org/pdf/2204.07141v1.pdf
代码链接:https://github.com/facebookresearch/msn
导读
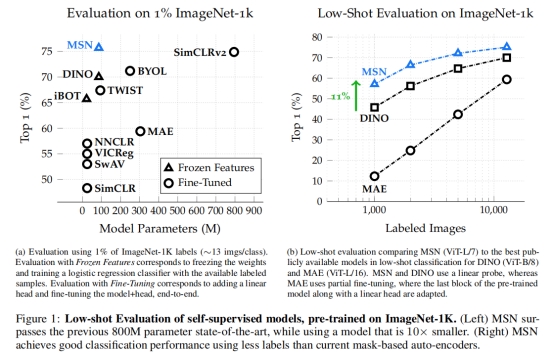
自监督学习近期一直是Transformer等大模型的重要研究内容,它通过约束模型对不同样本输入的特征表达能力更新参数,使模型能够更关注样本本身的特征。其中,何凯明老师提出的MAE算法揭示了图像掩盖-修复这一简单而有效的思路是自监督学习的一种有效方式,越来越多的研究人员开始关注这一方法思路。本文提出了Masked Siamese Network,一张用于学习图像表征的自监督学习框架,其实现思路是将图像随机掩盖后的特征与原始图像的特征进行匹配。当模型只处理未掩盖图像块时,这一策略特别适用于Vision Transformer模型,可以使联合映射架构(joint-embedding architecture)的泛化性能到提升,同时为少样本分类模型提供高语义相关的图像特征表达。实验表明,在ImageNet-1K数据集上,基准MSN模型只需要5000张标注图像就可以取得72.4%的准确率,将可用数据提升至1%的比例后,准确率更可以上升至75.7%,创建了小样本图像分类领域的新标准。

贡献
小样本学习的目的是消除人工标注数据的需求,近期成为了无监督学习中的重要策略。通过在无标签数据上进行训练大模型,小样本学习希望能够得到有效、泛化性强的模型参数并可以用于下游任务。
正如MAE的技术路线一样,SSL的一个核心思想就是去除输入的一部分内容并要求模型进行修复。在视觉模型中,Auto-regressive、denoising antu-encoder通过像素、token层面的修复实施了这一原则。然而,优化上述修复过程需要建模图像的low-level纹理特征,但这一特征对于分类等语义相关的任务并不适用。
因此,联合映射结构(joint-embedding architecture)似乎是一种有效的替代方案。Siamese网络便是其中的代表模型,它通过一个编码器模块对图像的不同视角学习相似的映射,而上述不同视角则是通过随机裁剪、缩放等手段得到。但这种方式可能呢会引入推理偏差(inductive bias),破坏模型的训练效果。
因此,本文提出Masked Siamese Network(MSN)这一自监督学习框架,它利用了mask-denoising的思路,同时毕淼的像素、token级别的重构流程。给定一个图像的两个视图,MSN 随机屏蔽一个视图,同时保持另一个视图不变,要求训练神经网络编码器使用Vision Transformer为两个视图输出相似的嵌入。 在这个过程中,MSN 不会在输入级别预测掩码补丁,而是通过确保掩码输入的表示与未掩码的表示匹配,在语义级别隐式执行去噪步骤。实验结果证明 MSN 学习了强大的现成表示,特别适用于小样本学习任务(参见图 1)。
方法
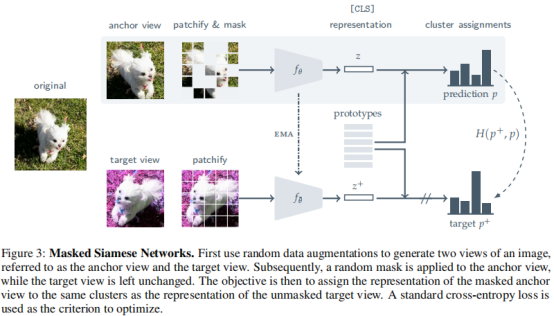
MSN的整体流程如上图所示,首先使用随机的数据增广方法生成图像的不同视角,即锚点视角和目标视角。接着,对锚点视角进行随机掩盖,通过计算掩盖后锚点视角与目标时间的软分布来实现自监督学习。
输入视角
假设在每个训练的迭代过程中,MSN采样B>=1张图像,对于每张图像,进行随机的数据增广方式,产生目标视角x+。
分块与掩盖
接着,MSN将每个视角的图像转化为非重叠的N * N个小块,并使用使用不同的策略掩盖目标视角:1)随机掩盖(下图b);2)局部掩盖(下图c)。

训练目标
为了训练Siamese网络中的编码器,MSN要求锚点视觉得到的预测与目标视角得到的预测尽量不同,主要通过交叉熵函数实现。此外,MSN在训练过程中对目标视角引入了视觉原型这一概念,并使用平均熵最大化进行监督:
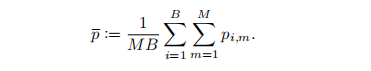
因此,整体监督函数定义如下:
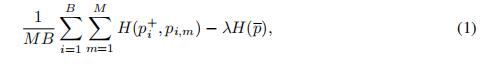
实验
本文采用ImageNet-1K数据集进行实验验证,作者首先给出了每个类别仅包含1-5张图像时的小样本分类结果:
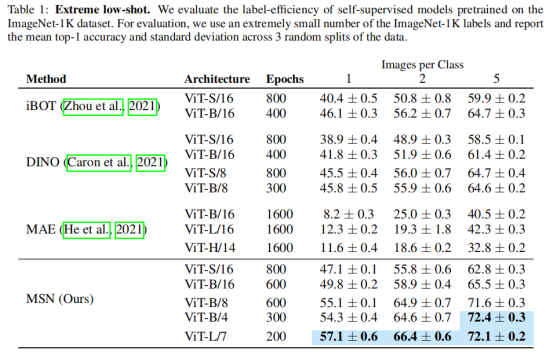
MSN 在所有监督级别上都优于其他表示学习方法。 此外,MSN 提供的改进随着可用标记数据量的减少而增加。 MSN 的性能也受益于模型大小的增加——标记数据较少的设置似乎从增加的模型中受益更多模型深度和更小的补丁大小。
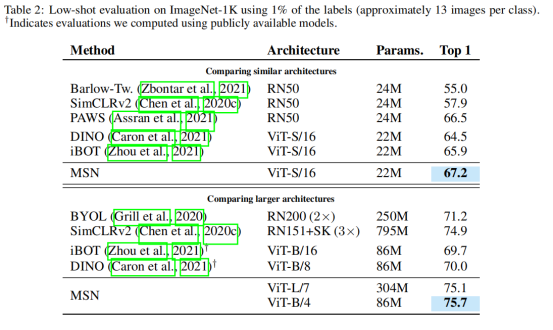
表 2 报告了 1%可用训练数据设定下的比较结果。已有文献中关于 1% 标记数据的最佳结果是 76.6%,这是通过从具有 3 倍宽通道和选择性的微调 ResNet-152 中得到的。当将比较重点放在相似的架构(具有相似FLOP计数的模型)上时,MSN也不断地改进了以前的方法。
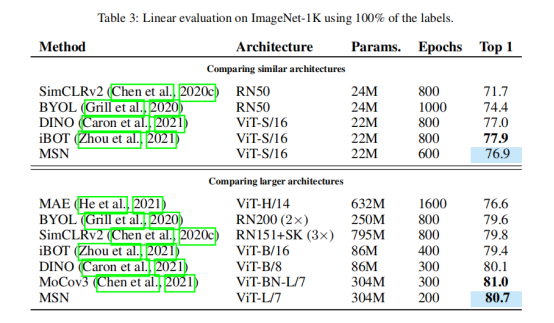
作者还通过冻结自监督预训练模型的权重和训练一个线性分类器来评估自监督预训练模型。表3报告了对ImageNet-1K的线性评价结果。可以观察到,MSN的表现与最先进的技术相竞争。最佳的MSN模型可达到80.7%的前1位精度。

表4报告了使用ImageNet-1K上100%标签的微调评估的比较。MSN与DINO和MAE等生成式自动编码方法相比具有竞争力。
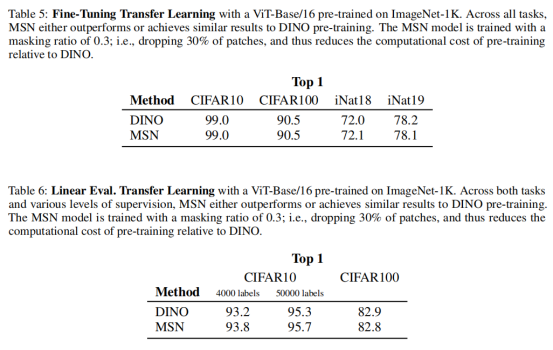
作者最后在表5和表6中提供了使用预训练的自监督ViT-B/16在CIFAR10、CIFAR100和iNaturitat数据集上的迁移学习实验。在所有任务和不同级别的监督中,MSN要么优于或达到类似于DINO的结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢