
作者:Payal Bajaj, Chenyan Xiong, Guolin Ke, 等
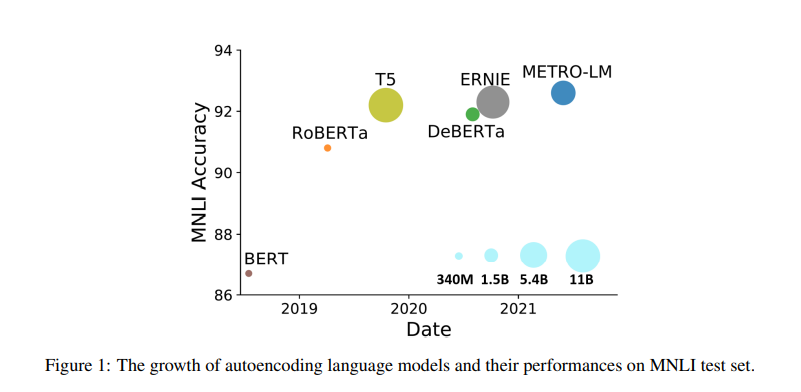
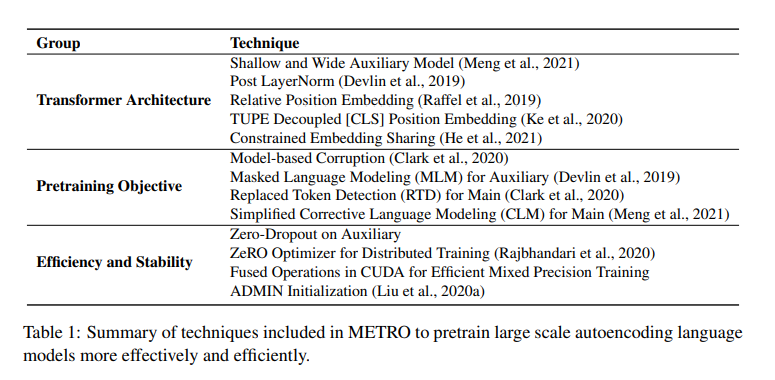
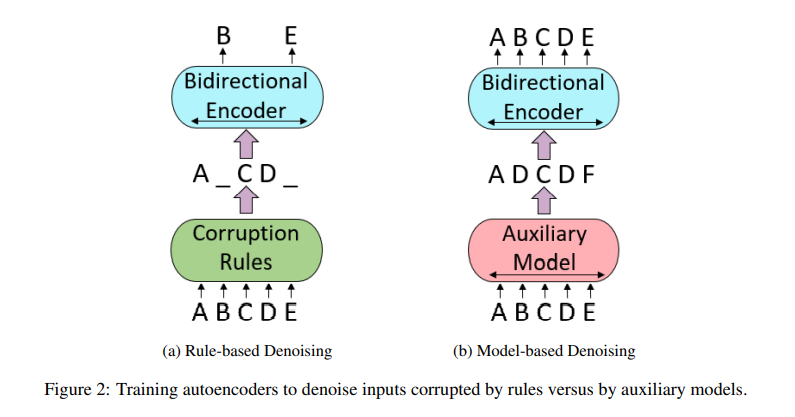
简介:本文提出了一种利用辅助模型生成的训练信号、预训练大规模自动编码语言模型的有效方法。该训练策略起源于ELECTRA,在数亿个参数的规模下,已经证明了对预训练模型的样本效率。在这项工作中,作者进行了全面的实证研究,并提出了一个方法、即“模型生成去噪训练目标”(METRO),它结合了最近开发的一些最佳建模技术,以加速、稳定和增强预训练语言模型,同时又不影响模型的有效性。由此产生的模型METRO-LM由多达54亿个参数组成,实现了 GLUE、 SuperGLUE、和SQuAD 基准上最新的SOTA水平。更重要的是,METRO-LM的效率高,因为METRO-LM通常比以前的大型模型表现更好、尺寸更小、预训练成本更低。
论文下载:https://arxiv.org/pdf/2204.06644
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢