
近日,悉尼大学等机构的研究者发布了视觉-语言预训练模型综述文章,今天我们谈谈视觉-语言预训练模型领域的一些基本概念和知识。
知识点
1.视觉-语言预训练模型可以被定义为同时对图像和语言数据进行建模和表示,在视觉、语言和跨模态等多种任务上进行应用的预训练模型。
2.从架构上,视觉-语言预训练模型可分为单流和双流两种。此外,根据跨模态表示模块架构的不同,还可以分为自注意力、联合注意力和视觉-语义嵌入跨模态对比学习模型三种。
3.视觉-语言预训练模型的下游任务包括但不限于:视觉问答、跨模态抽取、视觉对话、视觉常识推理等。
定义
近年来,预训练模型在视觉和语言领域都取得了进展。许多研究者开始探索跨模态的预训练模型在多种任务上的性能表现。
视觉-语言预训练模型可以被定义为同时对图像和语言数据进行建模和表示,在视觉、语言和跨模态等多种任务上进行应用的预训练模型。同时,论文[1]对视觉-语言预训练模型领域的多个概念进行了定义:
1.视觉-语言原始输入数据:包含一组文本和对应的一组图像的数据
2.视觉-语言表示:处理原始数据后形成的跨模态表示
3.视觉-语言交互模型:往往基于Transformer架构,对视觉和文本表示进行联合建模的模型
4.视觉-语言表示:对于一种模态或多种模态数据的跨模态表示
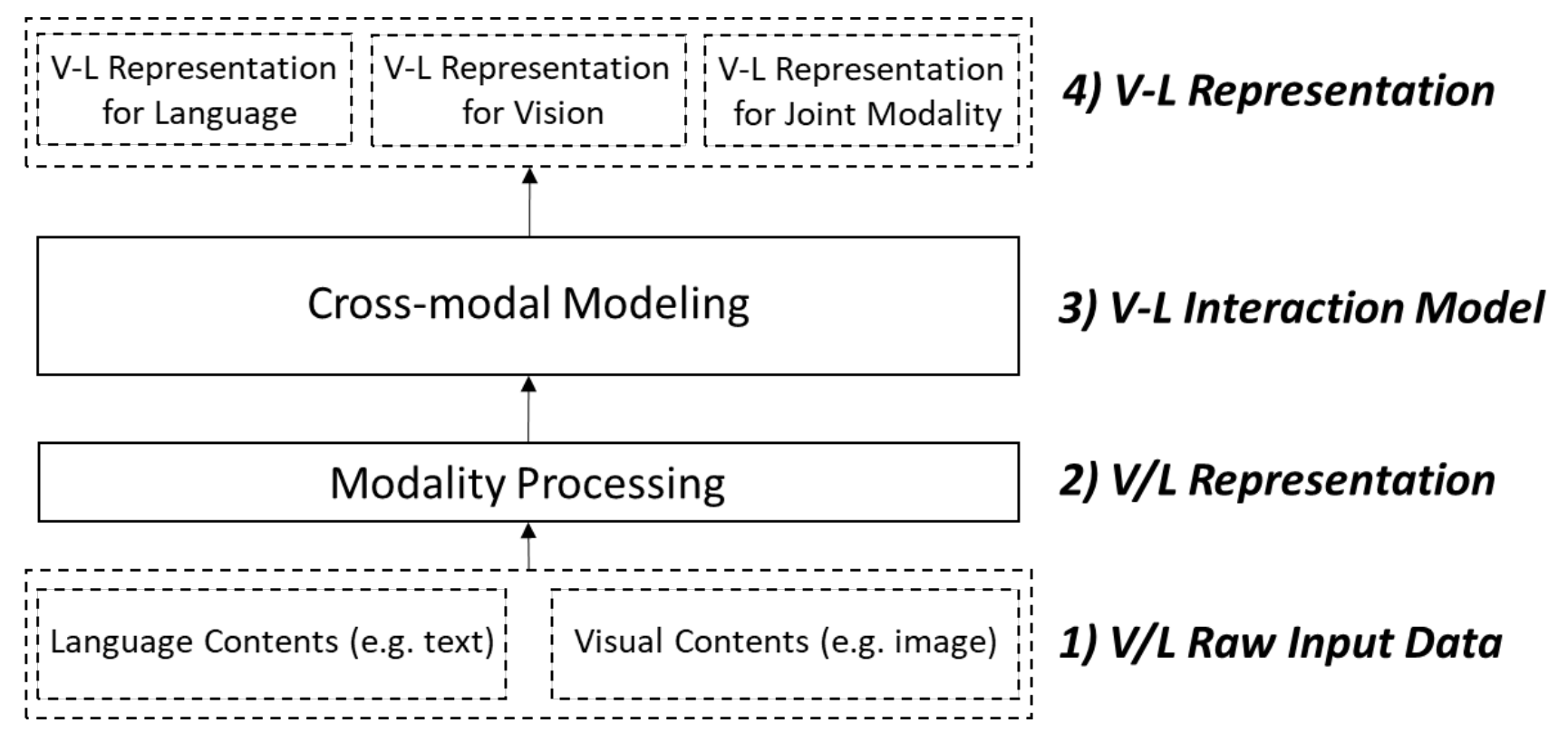 图注:视觉-语言预训练模型进行预训练的过程 [1]
图注:视觉-语言预训练模型进行预训练的过程 [1]
视觉-语言预训练模型的分类
根据结构不同,视觉-语言预训练模型可以分为两类:
1.单流(Single-stream)模型
使用一个联合跨模态编码器,在初始阶段直接将语言和图像表示进行融合。
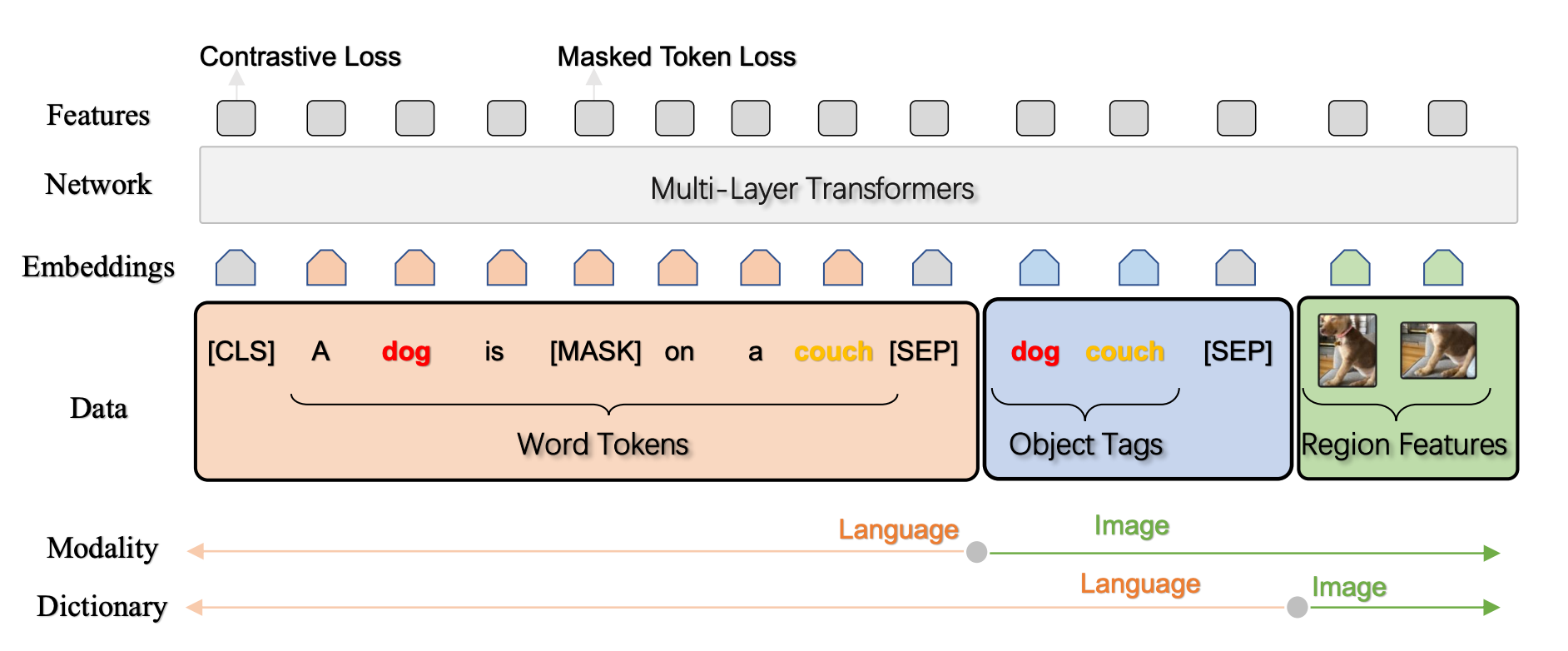
图注:单流模型案例 [2]
2.双流(Double-strem)模型
使用一个共享的跨模态编码器分别处理两种模态。
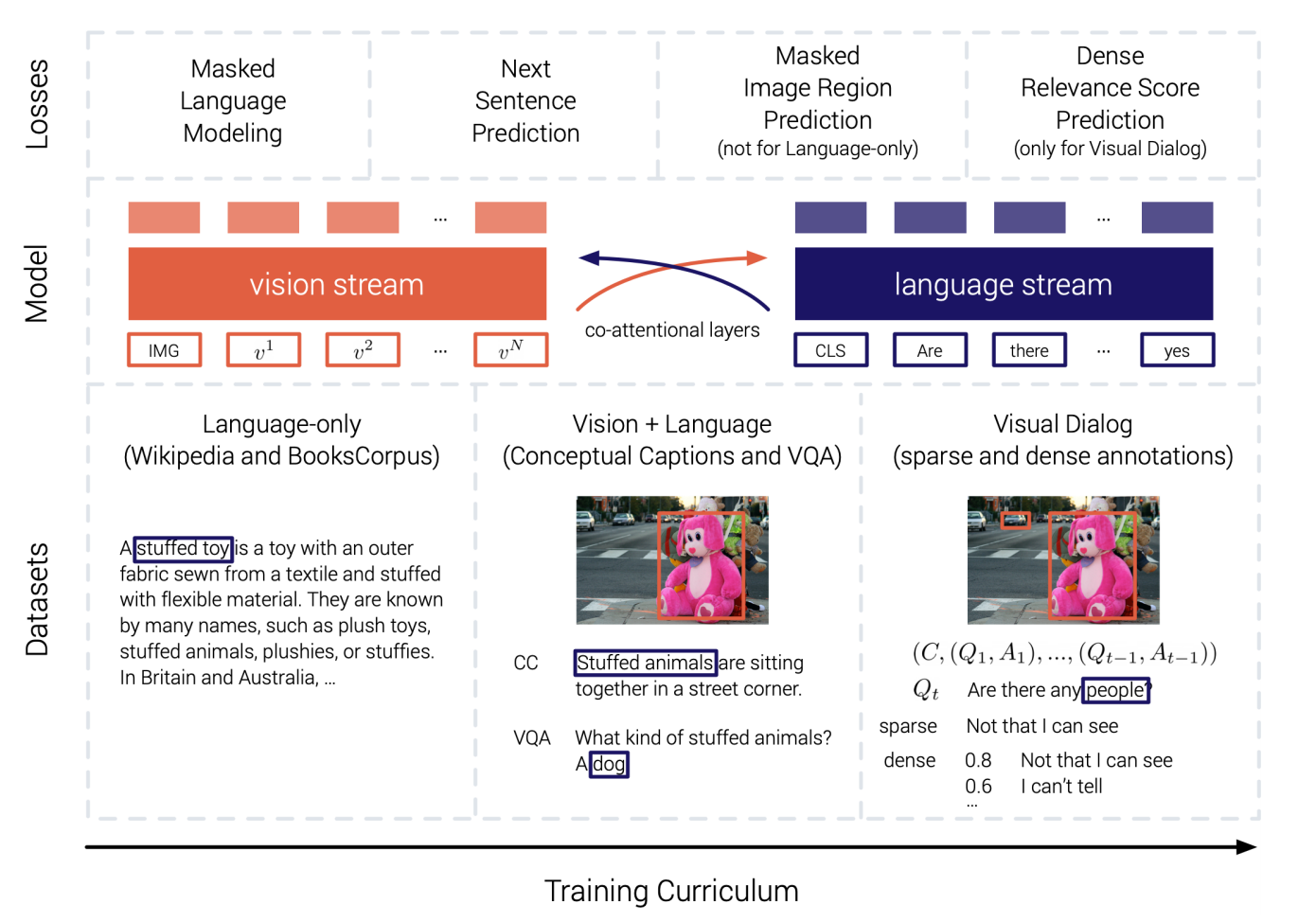
图注:双流模型案例 [3]
此外,根据融合视觉、文本表示模块架构的不同,还可以分为自注意力模型(Self-attention-based V-LIM)、联合注意力模型(Co-attention-based V-LIM)和视觉-语义嵌入跨模态对比学习(Visual Semantic-Embedding-based cross-modal contrastive learning)模型。
视觉-语言预训练模型的目标和任务
视觉-语言模型的预训练任务主要有三种,[1]分别是:
1.跨模态遮盖语言建模(Cross-modal Masked Language Modeling)
从遮盖语言建模(如BERT)延伸出来,通过学习图像信息,为语言建模提供更多的表征信息,从而使预训练语言模型扩展到跨模态学习领域。
2.跨模态遮盖区域建模(Cross-modal Masked Region Modeling)
通过对图像的部分区域进行遮盖,利用视觉-语言表示进行金阿莫,最终提升模型在视觉和多模态任务上的性能表现。
3.跨模态对齐(Cross-modal Alignment)
让模型通过学习,判断输入的图像-文本对是否为正确的一组。
迁移学习任务
通过学习了跨模态表示后,视觉语言模型在下游任务中能够取得较好的表现,包括但不限于:
VQA(Visual Question Answering):视觉问答
CMR(Cross Modal Retrieval):跨模态抽取
VCR(Visual Commonsense Reasoning):视觉常识推理
REC(Referring Expression Comprehension):指代表示理解
VRD(Visual Relationship Detection):视觉关系检测
VD(Visual Dialogue):视觉对话
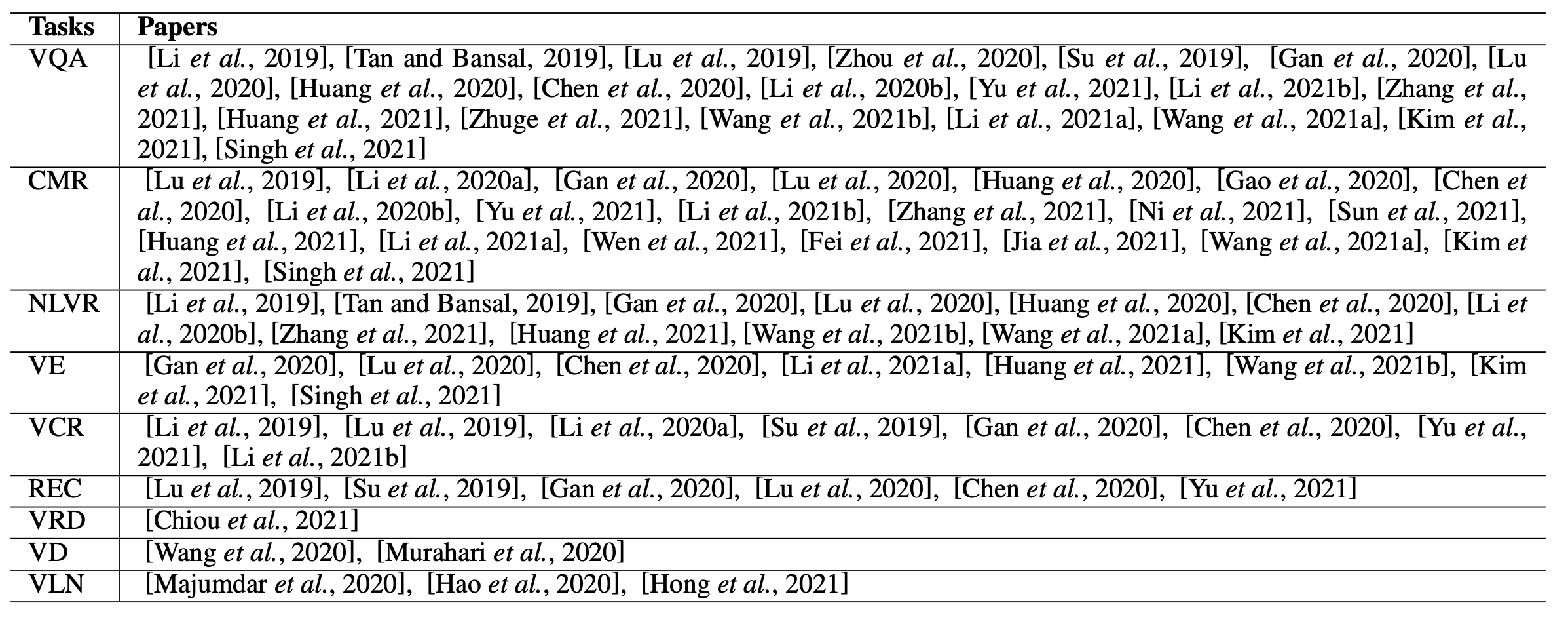
图注:视觉语言理解任务一览 [1]
参考链接
[1] Vision-and-Language Pretrained Models: A Survey:https://arxiv.org/pdf/2204.07356.pdf
[2] Li, Xiujun, et al. "Oscar: Object-semantics aligned pre-training for vision-language tasks." European Conference on Computer Vision. Springer, Cham, 2020.
[3] Murahari, Vishvak, et al. "Large-scale pretraining for visual dialog: A simple state-of-the-art baseline." European Conference on Computer Vision. Springer, Cham, 2020.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢