
【论文标题】Generative power of a protein language model trained on multiple sequence alignments
【作者团队】Damiano Sgarbossa, Umberto Lupo, Anne-Florence Bitbol
【发表时间】2022/04/15
【机 构】洛桑联邦理工
【论文链接】https://arxiv.org/pdf/2204.07110v1.pdf
从进化相关的蛋白质序列的大集合开始的计算模型捕捉到了蛋白质家族的代表,并学习了与蛋白质结构和功能相关的约束。因此,它们为产生属于蛋白质家族的新序列提供了可能性。基于多序列比对训练的蛋白质语言模型,如MSA Transformer,是实现这一目标的极具吸引力的候选者。本文提出并测试了一种迭代方法,该方法直接使用掩盖的语言建模任务,用MSA Transformer生成序列。本文证明,所产生的序列在同源性、共进化和基于结构的测量方面通常比Potts模型所产生的序列得分要高,甚至比天然序列得分要高。此外,尽管Potts模型更好地再现了一阶和二阶统计,MSA Transformer比Potts模型更好地再现了天然数据的高阶统计和序列在序列空间的分布。因此,MSA Transformer是蛋白质序列生成和蛋白质设计的有力候选者。
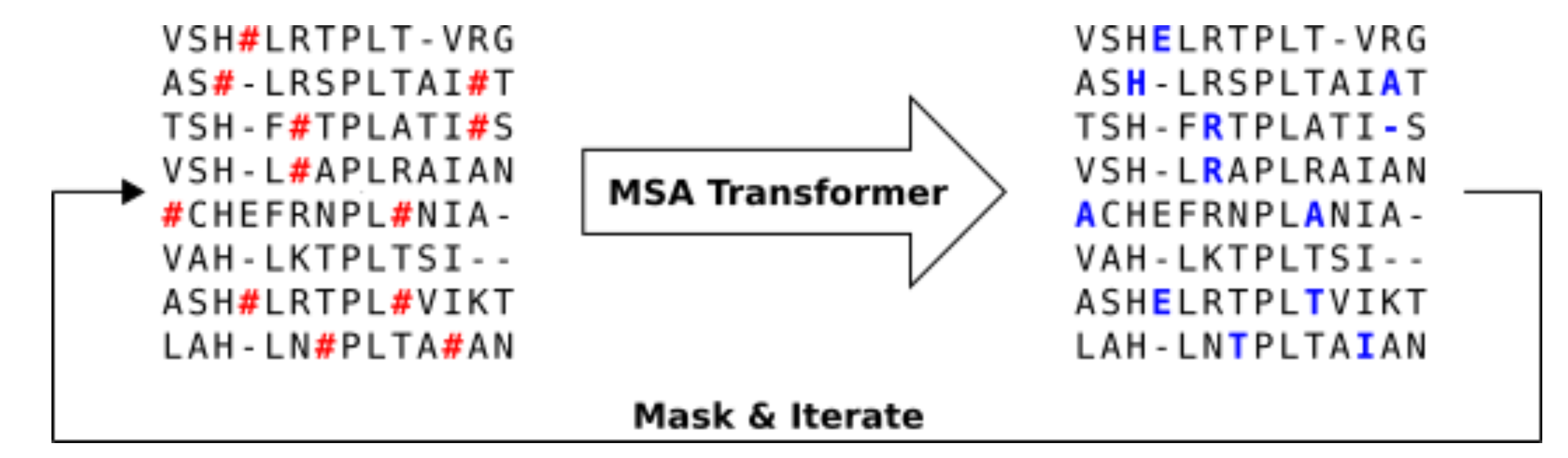
上图展示了使用MSA transformer进行序列生成的流程。
1 .对天然MSA M进行抽样以获得MSA Transformer的输入MSA M′。M′的深度是根据MSA Transformer的内存占用率选择的。在本文中,作者使用从天然MSA中均匀地随机挑选的600个序列的输入MSA。
2. 以概率p=0.1随机遮蔽M′的每个残基。
3. 将被遮蔽的MSA送入模型,用概率最高的token来填充每个被遮蔽的条目。
4. 重复步骤2和步骤3若干次。经过200次迭代后停止。
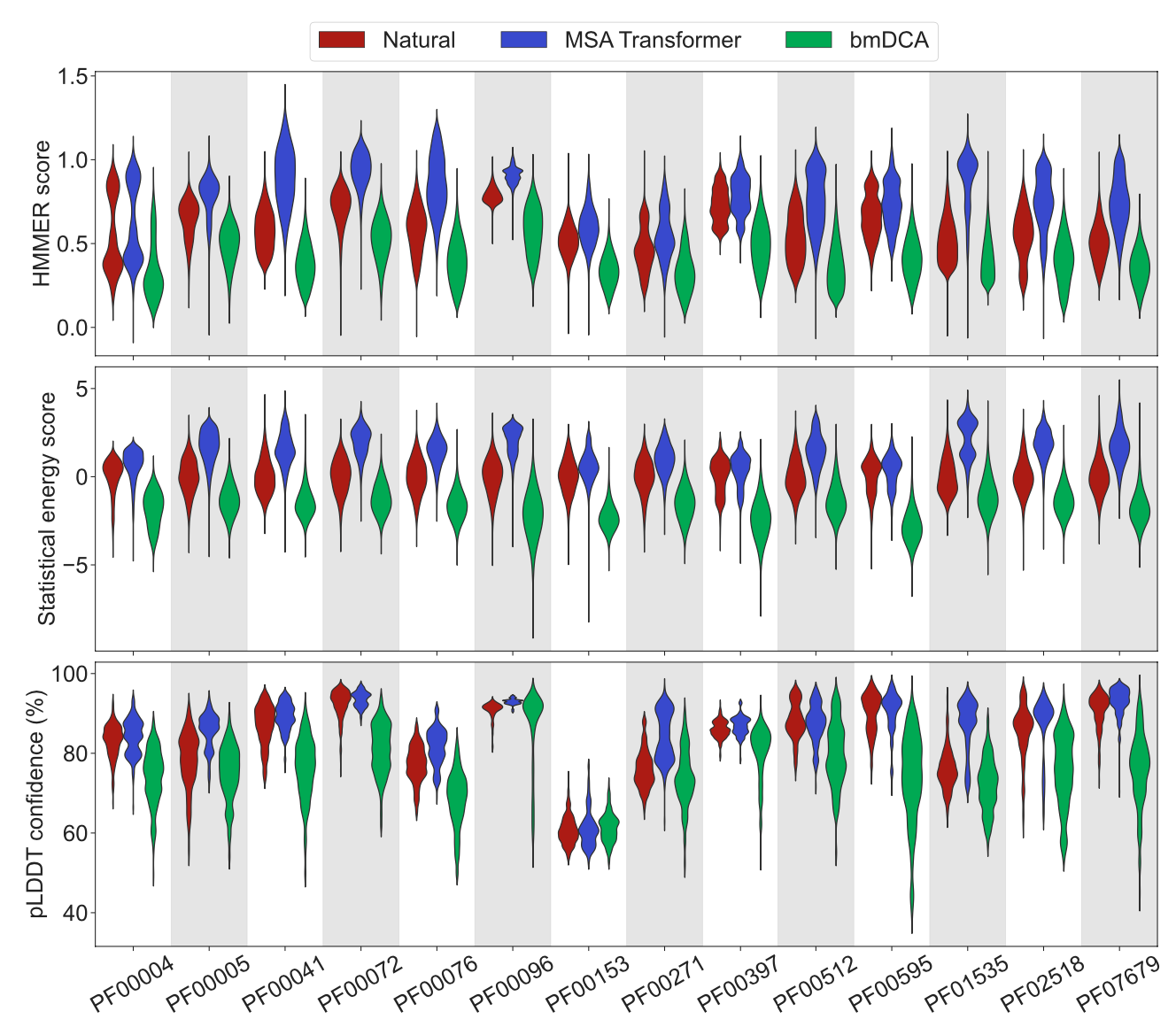
上图显示了天然序列和由MSA Transformer或bmDCA生成的序列之间的同源性、共进化和基于结构的得分。
对于各个Pfam家族,本文比较了来自Pfam的一个天然MSA和两个相同深度的合成MSA,并展示了其对应HMMER分数、统计能量得分、Alphafold pLDDT小提琴图。
- 第一个合成MSA是使用MSA Transformer通过本文的迭代掩蔽程序得到的,
- 第二个合成MSA是使用bmDCA从天然MSA推断出的Potts模型生成的。
对于所考虑的所有蛋白质家族和这三种不同的分数,MSA Transformer使用迭代遮蔽实验法所产生的序列的分数与天然序列相当,甚至平均来说比天然序列更好。相反,由bmDCA生成的序列,其得分平均比天然序列差。即使是由bmDCA拟合的Potts模型建立的得分,即统计能量得分也是如此。这些结果表明,MSA Transformer是生成蛋白质家族合成序列的一个很好的工具。
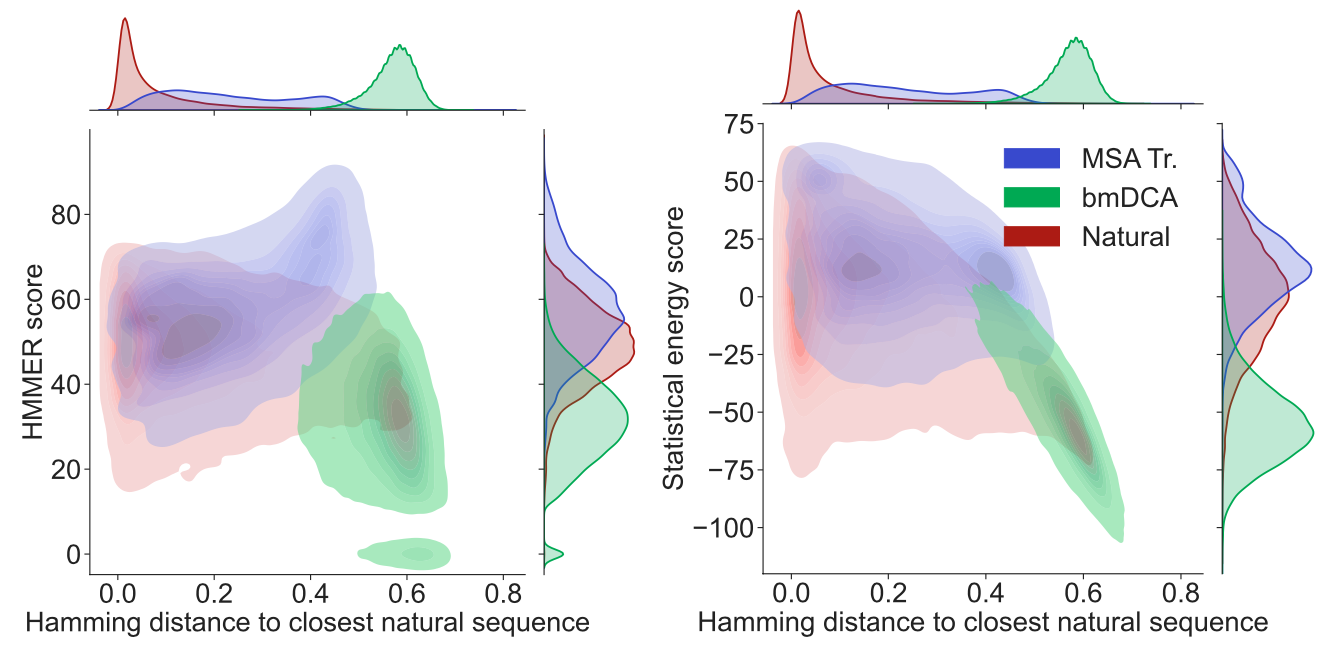
上图展示了蛋白质家族PF00153的同源性和共进化得分与天然MSA的距离。具体来说显示了HMMER分数和统计能量分数与每个序列与最接近的天然序列的Hamming距离的等高线图,可以发现以下特点:
- 从Hamming距离的边际分布来看,MSA Transformer生成的序列与最接近的天然序列的距离是不一样的,而且这些距离总体上大于最接近的天然序列之间的距离。相比之下,bmDCA生成的序列往往与天然序列有极大的差异。
- 分数的边际分布说明了MSA Transformer生成的序列的总体分数高于bmDCA生成的序列,甚至高于天然序列。
- 在与天然MSA的一定距离内,MSA Transformer生成的序列往往比bmDCA生成的序列具有更高的HMMER分数和统计能量分数。
- 具有最高HMMER分数的MSA Transformer生成的序列是那些与天然序列具有较大Hamming距离的序列。
因此,MSA Transformer生成的序列并没有通过过度拟合和复制天然序列而达到良好的分数。

上图展示了PF00153家族中从生成的MSA中估计的二体和三体的关联性与天然数据的关联性。为了评估有限大小的影响,第三列包括一个空模型,该模型是通过将天然MSA分成两半并将其中一半的统计数据与另一半的统计数据进行比较而得到的。由MSA Transformer和bmDCA生成的合成MSA在多大程度上重现了在天然MSA中观察到的氨基酸使用的统计数据?为了解决这个问题,本文从天然和合成的MSA中计算出单体、双体和三体频率,并对这些统计数据及其信息理论的概括进行比较。
从双体中可以发现MSA Transformer对这些关联的再现不如bmDCA准确。Potts模型是成对的最大熵模型,被限制为与天然MSA的单体和双体频率相匹配,所以bmDCA被训练为重现这些频率,而MSA Transformer有完全不同的训练目标。因此,这个结果是符合预期的。那么,不属于bmDCA拟合目标的高阶统计学呢?第二行,作者显示了三阶连接相关性的比较,这些数字表明,由MSA Transformer生成的MSA比由bmDCA生成的MSA更好地再现了天然MSA的高阶统计数据。
创新点
- 在这项工作中,本文提出了一个迭代遮蔽程序,直接利用蛋白质语言模型的遮蔽语言建模目标,使用基于MSA的神经语言模型MSA Transformer生成序列。
- 本文发现,这些序列的得分通常比天然的要好,主要表现在由bmDCA Potts模型生成的序列在三个非常不同的方面,即同源性、共进化和基于结构的得分。
- 此外,MSA Transformer生成的序列比bmDCA生成的序列更好地再现了天然数据的高阶突变和序列在序列空间的分布。相反,bmDCA更好地重现了一阶和二阶,这与它的训练目标一致。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢