
论文标题:Multi-Frame Self-Supervised Depth with Transformers
论文链接:https://arxiv.org/abs/2204.07616
主页链接:https://sites.google.com/tri.global/depthformer
作者单位:丰田研究院
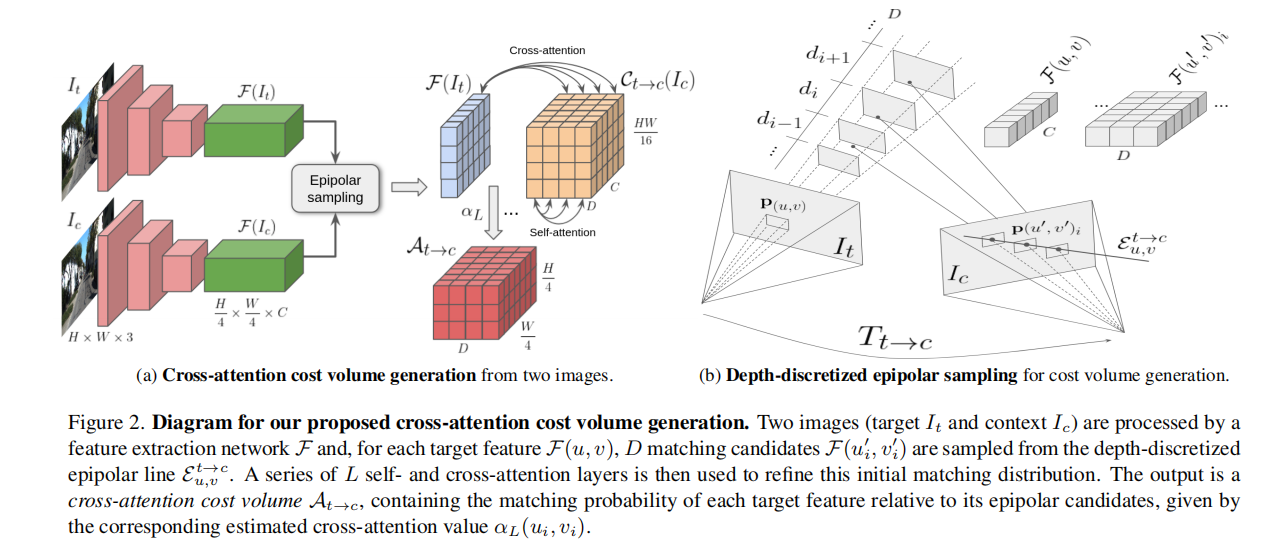
除了学习基于外观的特征外,多帧深度估计还通过特征匹配利用图像之间的几何关系来改进单帧方法。在本文中,我们重新访问了用于自监督单目深度估计的特征匹配,并提出了一种用于cost volume生成的新型Transformer架构。我们使用深度离散的极点采样来选择匹配的候选者,并通过一系列自注意力和交叉注意力层来细化预测。这些层提高了像素特征之间的匹配概率,改善了容易出现歧义和局部最小值的标准相似度指标。精炼的成本体积被解码为深度估计,整个pipeline仅使用光度目标从视频中进行端到端训练。在 KITTI 和 DDAD 数据集上的实验表明,我们的 DepthFormer 架构在自监督单目深度估计方面建立了新的技术水平,甚至可以与高度专业化的监督单帧架构竞争。我们还表明,我们学习的交叉注意力网络产生可跨数据集转移的表示,提高了预训练策略的有效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢