

论文链接:https://arxiv.org/pdf/2204.03475v1.pdf
代码链接:https://github.com/Alibaba-MIIL/Solving_ImageNet
导读
ImageNet是目前评估计算机视觉模型性能的主要数据集,一种常见的做法是为不同结构的模型设计一个专业的训练策略,并进行优化和对比。在本文中,作者们提出了一个在ImageNet数据集上训练任何结构Backbone网络的方法。其名称为Unified Scheme for ImageNet,USI,以知识蒸馏和技巧为主,不需要为不同模型调整超参数和训练参数,且具有快捷的训练耗时。本文在CNN、Transformer、Mobile-oriented、纯MLP四种模型上进行了验证。结果证实,USI在这些模型上均得到了SOTA的结果,因此,可以将在ImageNet上训练的不同任务、模型转化为一个统一的、可比较的自动过程。
贡献
ImageNet(1K)数据集是为ILSVRC2012视觉识别挑战竞赛提出的数据集,它一直是深度学习模型进行验证、改进的重要数据来源,不仅可以作为计算机视觉模型预训练的主要数据集,在ImageNet上测量模型的准确性还可以很好地反映各种下游任务的实际性能。
然而,在ImageNet数据集上进行训练仍是一个未解决的挑战。自从AlexNet的开创性工作以来,超时学习率调度、自动增强、随机增强、批大小的缩放学习率、模型权重的指数移动平均、改进权值初始化、基于图像的正则化等新的训练技巧、正则化和改进方法不断提出。几乎所有新模型都伴随着一个特定的训练方案,这些方案可能会有很大的不同,而且针对一个模型的训练方案在用于其他模型时往往表现不佳。例如,当使用ResNet50模型的专用方案来训练EfficientNetv2模型时,它的精度会降低约3.3%。
广义上说,计算机视觉的深度学习Backbone可以分为四类:CNN(ResNet)、Transformer、Mobile-oriented、纯MLP。ResNet模型及其变体(TResNet[30],SEResNet[18],ResNet-D[15]等等)通常在各种训练方案上效果较好。Mobile-oriented模型严重依赖于深度卷积和高效的面向cpu的[32,17,34]架构。基于Transformer的视觉[8,24,11]和MLP-only[36,37]视觉模型更难训练,[29,23]也更不稳定。在[38]中提出了这些模型专门的训练方案,包括更长的训练(1000个时代)、强切割混合和下降路径正则化、大重量衰减和重复增强[1]。
在本文中,作者介绍了一个统一的训练方案,称为USI(Unified Scheme for ImageNet)。USI可以训练任何主干到最先进的结果,且不需要任何超参数调优或每个模型的定制技巧。图1展示了USI的整体流程。
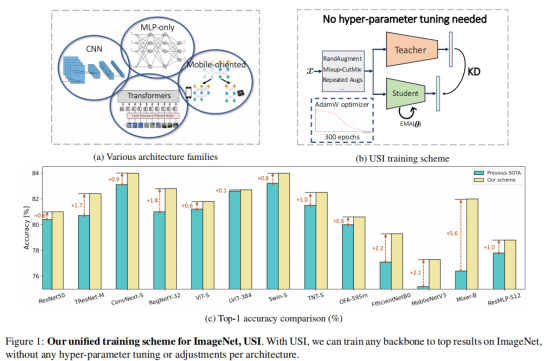
本文的主要贡献可以总结如下:
- 为ImageNet数据集引入了一个统一的、有效的训练方案,USI,它不需要超参数调整,适用于任何主干网络;
- 在各种深度学习模型上测试了USI,包括CNN、Transformer、Mobile-oriented、纯MLP。与每个模型的定制方案相比,证明USI可靠地取得了最先进的结果;
- 使用USI对现代深度学习模型进行了的速度-准确性比较,并沿着Pareto曲线识别了有效的主干网络。
方法
知识蒸馏的目的是将大模型中必要的参数知识迁移至计算消耗较小的小模型中来,近年来得到了众多研究人员的关注和思考。但是,这一研究方法并不是在ImageNet上进行训练的必要选项。
为什么要将知识蒸馏引入到ImageNet数据集的训练中?
ImageNet是预训练和评估计算机视觉模型的主要数据集。与其他分类数据集不同,在ImageNet上需要从头开始训练模型,而不进行迁移学习。一般来说,从零开始的训练是更困难的,需要更高的学习率、更强的正则化和更多的训练时代。因此,ImageNet上的优化过程对不同的超参数和所使用的体系结构更加敏感。
下图更直观地展示了本文的动机:
- 图片(a)包含大量钉子。注意,教师模型的第 2 和第 3 顶预测与钉子(螺钉和锤子)有关,但概率可以忽略不计。
- 图片 (b) 包含一架客机。 这是教师模型的最高预测(6%)。 然而,教师模型也以不可忽略的概率(11.3%)预测翅膀。这里的老师减轻了真实标签不是互斥的情况,并提供了关于图像内容的更准确的信息。
- 图片(c)中包含了一只母鸡。然而,母鸡并不是很容易观察到。教师模型的预测反映了这一点,通过识别出一只概率较低的母鸡(5%)。
- 在图片(d)中,老师不同意ground-truth。
从上面的例子中可以看到,教师模型的预测比简单的标签包含了更多的信息。老师提供的丰富的预测解释了类别之间的相关性和相似性。由于这些因素,与仅使用硬标签的训练相比,使用教师模型的训练提供了更好的监督,导致了一个更有效和更平稳的优化过程。

USI训练策略
如下图所示,USI是基于知识蒸馏的训练策略。当使用知识蒸馏在ImageNet上进行训练时,可以观察到训练过程对超参数选择的鲁棒性更强,并且需要更少的训练技巧和正则化。此外,一个单一的统一方案可以训练任何主干达到最佳结果。
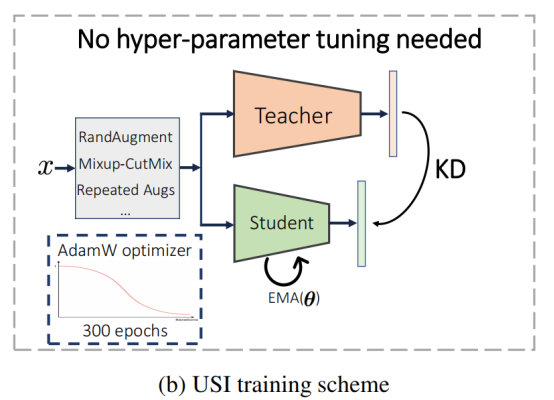
表1给出了USI的全部训练配置:
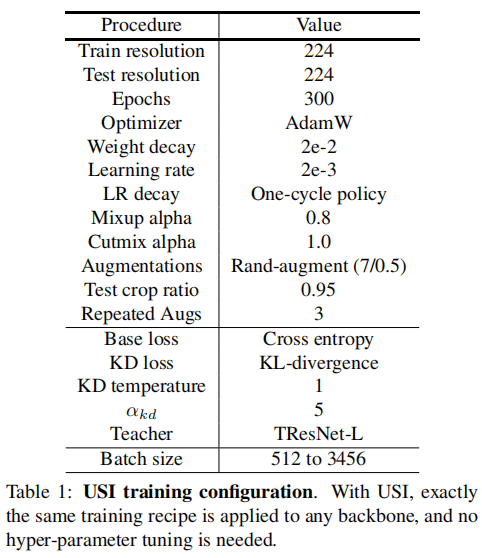
其中,batch size的选择策略是越大越好,教授模型的选择策略是性能上优于学生模型。具体选择上述配置的原因将在实验部分给出。
实验
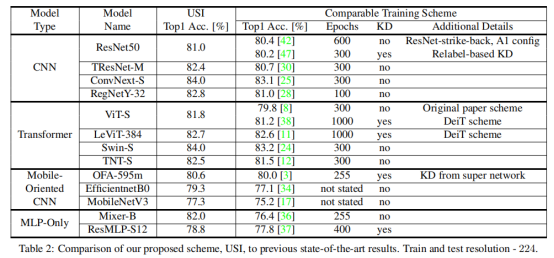
表2给出了各种深度学习架构在使用USI方案进行训练时获得的ImageNettop-1精度。作者将USI与以前的最先进的结果进行了比较,从表2中可以看到,在所有测试的架构(CNN、变压器、面向移动的、MLP-only)上,USI获得的结果优于之前报告的实验结果。
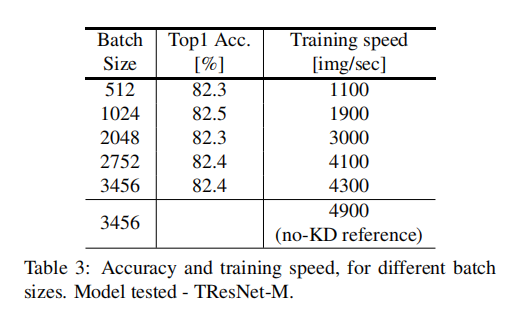
如第2.3节所述,batch size增大会加快训练速度。在表3中,作者测试了具有固定学习率的USI对不同batch size的鲁棒性。表3表明,在一个大范围的batch size内(512-3456),精度几乎保持不变,这表明USI在固定的学习速率下运行良好。
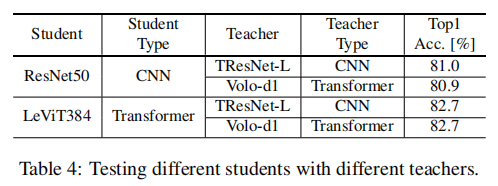
表4测试了不同的学生模式是否从不同的教师模型中受益。

在表5中,我们给出了在不同的训练长度下获得的准确性。可以看出,随着我们将训练时间从300增加到600增加到1000,准确性继续提高。
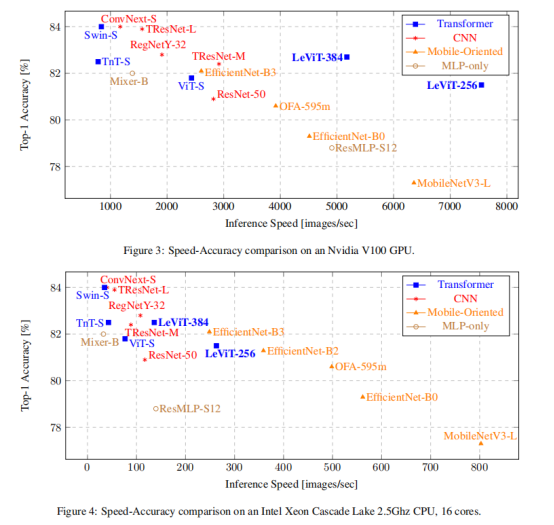
有了USI,我们可以在ImageNet上进行方法、可重复和可靠的速度-精度权衡比较。在图3和图4中,我们比较了各种关于GPU和CPU推理的现代架构。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢