
随着预训练语言模型的发展,诞生了很多新颖的训练方法。近年来计算机视觉领域也开始从NLP领域借鉴相应的技术,今天我们要谈的就是遮盖图像建模,一项借鉴了掩码语言模型的技术。
知识点
1.遮盖图像建模(Masked Image Modeling)是一种新型的视觉预训练方法。通过借鉴预训练语言模型BERT采用的自掩码预训练机制,遮盖图像建模对需要进行预训练的图像输入进行随机的部分遮盖,要求网络对原始的图像进行重建,从而实现对于图像数据的预训练。
2.目前典型的相关方法包括BEiT、MAE等。
定义
遮盖图像建模(Masked Image Modeling),又称“掩码图像建模”,是2021年开始兴起的一种新型的视觉预训练方法。它借鉴了预训练语言模型BERT采用的自掩码预训练机制,对需要进行预训练的图像输入进行随机的部分遮盖,要求网络基于被遮盖过的图像,对原始的图像进行重建[1],从而实现对于图像数据的预训练。
典型方法
1.BEiT
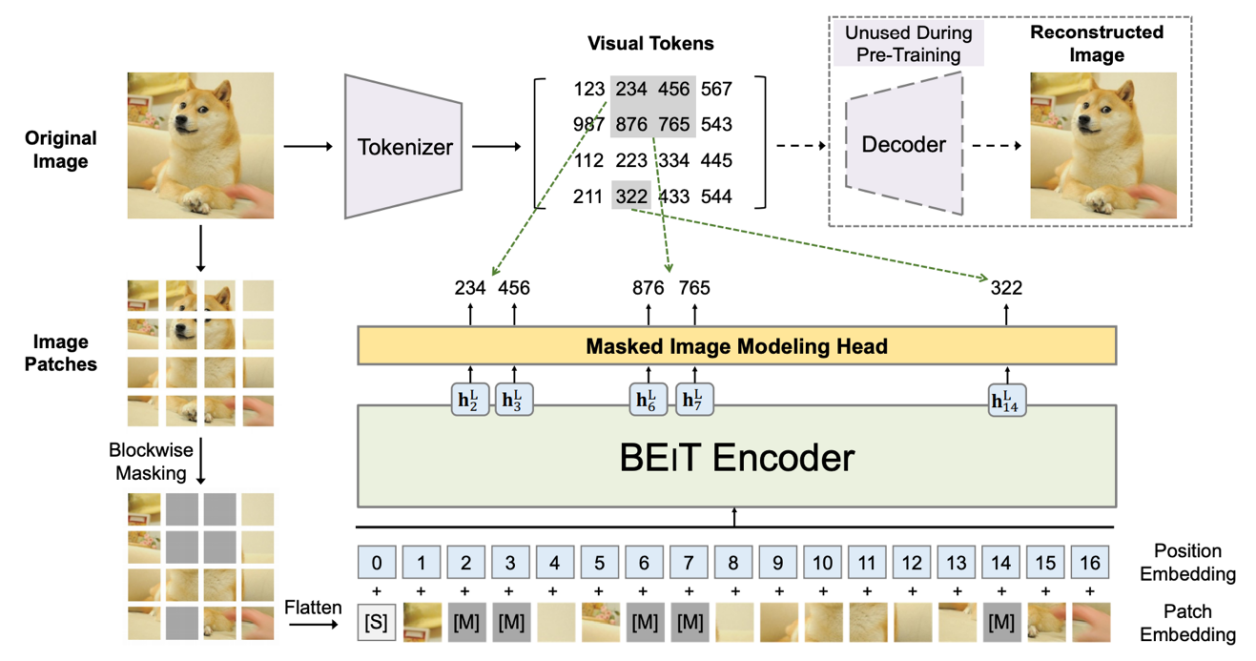
BEiT是微软亚洲研究院Hangbo Bao等人在2021年提出的一个视觉预训练模型,该文首先提出了遮盖图像建模这一学习任务机制。[2]
BEiT中的遮盖图像建模机制如下:
(1)将原始图像分割为一定尺寸的图像块(Patch);
(2)设置一定比例的图像被灰度图像遮盖(被遮盖的图像比例由研究者设定,在BEiT中是40%);
(3)将图像拉平为图像块的序列,并转换为视觉Token,连同位置嵌入表示,一同输入到Transformer架构的模型中;
(4)对于被遮盖的Patch,有一个可学习的嵌入表示。在给定被遮盖图像的情况下,求被遮盖图像部分视觉Token的最大对数似然,以此实现对被遮盖图像的还原[1]。
 2.MAE(Masked Autoencoder)
2.MAE(Masked Autoencoder)
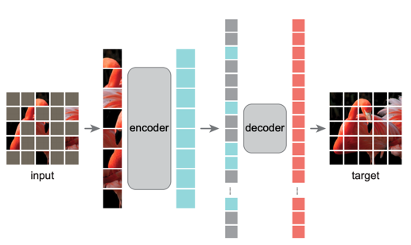
和BEiT采用了相似机制的还有Facebook AI科学家何恺明(Kaiming He)等提出的Masked Autoencoder(MAE)。[3]
与BEiT不同,MAE并未将已遮盖掉的图像作为输入的一部分。当图像的大部分被遮盖后,被遮盖的Patch直接从输入中被移除(即输入的图像块序列中不含被遮盖图像区域),输入到编码器中的图像Patch序列仅仅是保留后的一部分图像。而解码器在还原整个图像的过程中,需要直接预测出不在输入序列中,被遮盖移除掉的图像部分。
遮盖图像建模技术的优势
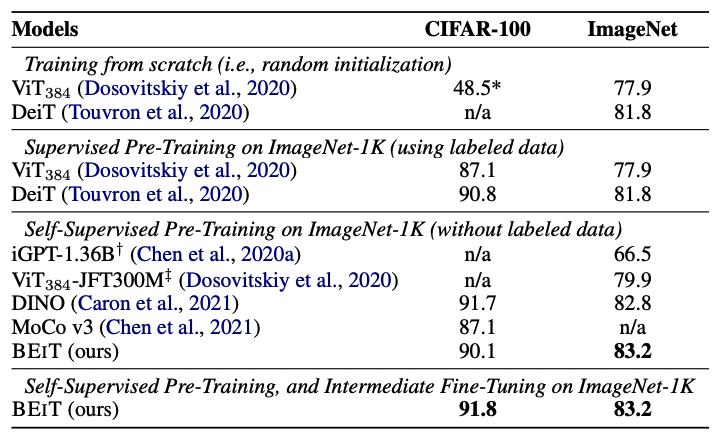
遮盖图像建模训练相比一般的图像建模训练,能够为模型在下游任务上带来更高的性能提升。例如,Base-size的BEiT模型在ImageNet-1K数据集上实现了83.2% 的Top-1准确率。而更大规模的BEiT模型在仅使用ImageNet-1K数据集的情况下实现了86.3%的准确率,超过了ViT-L模型在ImageNet-22K上的预训练表现。[2]
在MAE论文中,基于MAE的模型在COCO目标检测、ADE20K 语义分割、图像分类等任务上,均取得了当前的最佳性能水平。[3]
参考链接
[1] 智源人工智能前沿报告:https://baai.org/l/Frontiers2021
[2] Bao, Hangbo, Li Dong, and Furu Wei. "Beit: Bert pre-training of image transformers." arXiv preprint arXiv:2106.08254 (2021).
[3] He, Kaiming, et al. "Masked autoencoders are scalable vision learners." arXiv preprint arXiv:2111.06377 (2021).
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢