
近日,全球自然语言处理(NLP)顶级会议NAACL 2022公布论文评审结果,网易伏羲3篇论文入选,研究方向涉及NLP领域的大规模预训练模型的推理加速、Transformer结构优化、长文本序列建模等,其技术可用于大规模模型部署、长文本生成、自然语言理解等领域。

据悉,入选论文相关成果已经应用于基于大规模预训练模型服务的推断性能提升,在情景对话、故事续写、歌词生成等任务上降低了约4倍服务延迟,同时论文中提出的增强Bert类型预训练模型性能的方法助力网易伏羲成功登顶中文语言理解权威评测基准FewClue榜单。
NAACL是自然语言处理领域的顶级国际会议,与ACL、EMNLP并称NLP领域的三大顶会。Google Scholar计算语言学刊物排名中,NAACL位列前三,其H5指数和H5中位数达到105和195,影响力可见一斑。
以下是网易伏羲本次入选的论文概述:
一、《简单且高效的Transformer:大型NLP模型的可扩展推理解决方案》
《Easy and Efficient Transformer: Scalable Inference Solution For Large NLP Model》,该文章被NAACL 2022 Industry Track接收。
文章简介:
基于transformer的超大模型在自然语言处理、多模态、图像等领域上有着惊艳的算法表现,但其推理时的庞大显存和密集计算使得其无法满足生产环境下的高吞吐、低延迟、低成本需求,因此,研究生产环境可容忍的大模型推理技术十分必要。网易开源的Easy and Efficient Transformer 通过深度优化的CUDA算子和精致的显存压缩策略,支持最大可达12288的模型维度和最长可达4096的序列长度,其性能是NVIDIA Faster Transformer(v4.0)的1.4倍到4.2倍,模型承载能力约是pytorch的1.8倍。
应用场景:
transformer的decoder由于生成序列的不可知,只能逐字生成,其性能往往是瓶颈。EET基于pre-padding的解码策略,对提示词做一次性推理的全量解码,对生成字词做KV缓存的增量解码,并通过mask fusion的CUDA设计方法,避免了现实的mask构造与计算,从而带来性能的显著提升,下图为EET与FT(V4.0)在不同提示词长度下的性能加速情况(hidden_size为1024):
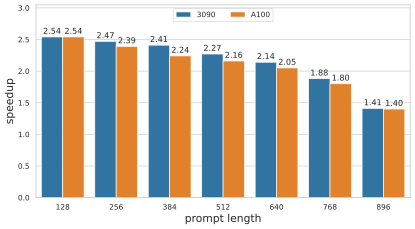
在实际应用中,更大的模型维度和序列长度经常会被使用,由于CUDA的block最大可支持的线程块大小为1024,部分推理框架仅支持最大到1024的模型维度和序列长度。EET通过线程块折叠的方法,便捷高效的扩展了最大支持的模型维度和序列长度。下图为EET与FT(v4.0)在不同模型维度下的性能加速情况:
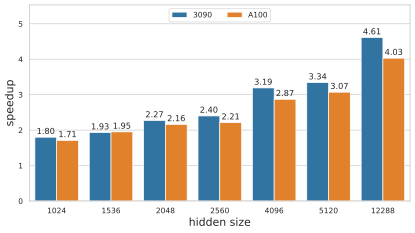
为了扩展单卡的模型容纳能力,EET设计了针对激活值复用和buffer复用的显存池化策略,在该策略下,约98%的显存为模型的权重和K/V的cache,激活与中间结果仅占了微小的2%左右的空间。下图为在不同模型大小下,EET的显存占用与pytorch显存占用的对比:
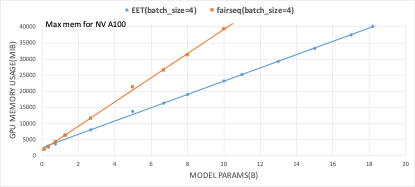
EET已服务于网易内部多款游戏以及网易云音乐、LOFTER等产品,在情景对话、故事续写、歌词生成等任务上降低了约4倍服务延迟,助力超大模型在实际业务中发挥价值。
左:《遇见逆水寒》-文字游戏;右:未来大会2020主题曲《醒来》
EET github地址: https://github.com/NetEase-FuXi/EET
二、《DecBERT: 利用因果注意力掩码增强BERT的语言理解》
《DecBERT: Enhancing the Language Understanding of BERT with Causal Attention Masks》,该文章被NAACL 2022 Findings接收。
文章简介:
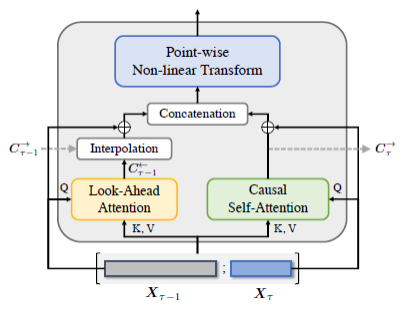
Transformer模型被广泛地应用于序列建模的任务,例如自然语言,图像,音频,行为序列等领域。相比于LSTM天然的具有建模序列顺序的能力,Transformer模型不具有这样的结构性先验。因此,为了让Transformer 模型具有建模序列顺序的能力,业界使用了Position Embedding的方法,对Transformer的输入直接加上位置标记信息。这样Transformer 就可以在建模不同token间关系的时候使用到token间的位置关系。为了改善Position Embedding的效果,后序也提出了一系列改进方法。但是除了在输入端使用Position Embedding标记位置信息,还可以在multi-head attention的操作中使用mask机制,通过控制一个token可以“看”到的token范围来建模不同token间的位置关系。像GPT这样的自回归生成模型都采用了future mask,即序列中一个token只能看到排到它前面的token。我们在论文中通过实验验证了只使用future mask的GPT的ppl和加了Position Embedding的GPT的ppl相差很小。最近Adi Haviv 等人同样发现了这个现象【1】。相比于自回归生成模型,类似于Bert的双向注意力模型目前还没有研究工作使用future mask的方法去建模序列信息,普遍只使用Position Embedding 方法。于是我们提出了Decbert,将mask机制引入到Bert类型的模型中。不同于GPT在每一层使用future mask, 我们在第一层使用future mask,第二层使用future mask 或者past mask(一个token只能看到它后面的token),分别标记为DecBert-Same和DecBert-Diff。后面的层不使用mask,和常规的Bert 结构一样。下面是模型结构示意图:
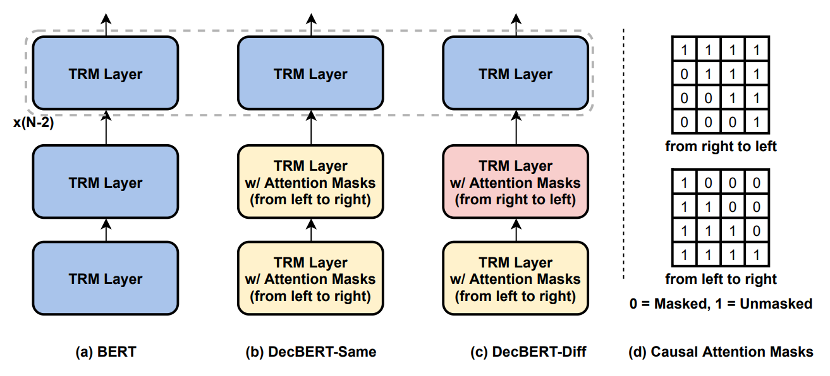
上图中TRM指Transformer层。为了验证我们方法的有效性,以下是一些实验结果:
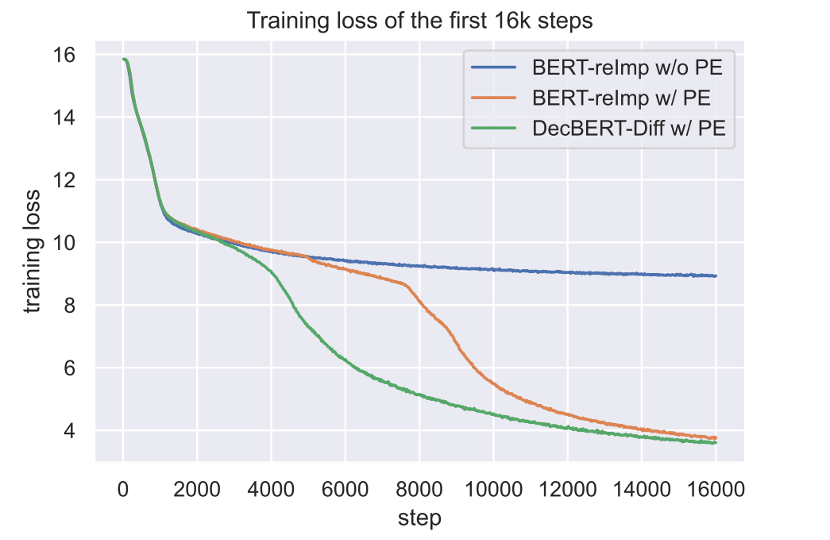
从图中可以看出,我们提出的DecBert的损失下降曲线几乎没有平台期,并且最终的损失最小。

我们使用相同的训练设置训练了Bert和DecBert,在GLUE的测试集上DecBert平均相比Bert提升了1.2分,非常显著。
【1】Transformer Language Models without Positional Encodings Still Learn Positional Information https://arxiv.org/pdf/2203.16634.pdf
应用场景:
本文提出了一种新的增强Bert类型预训练模型性能的方法,实现简单,几乎没有额外计算开销,并且效果提升比较明显,可以和其他的方法混合使用。我们将此方法应用到了FewClue评测的模型训练中,对评测成绩有明显提升,并且最终取得第一的成绩。
三、《LaMemo: 具有前瞻记忆的语言建模》
《LaMemo: Language Modeling with Look-Ahead Memory》,该论文由网易伏羲和清华大学黄民烈老师团队合作完成,被接收为NAACL 2022 Long Paper。
文章简介:
虽然基于全连接注意力机制的Transformers在建立长期依赖关系的模型方面很强大,但在语言模型中,它们很难扩展到有成千上万字的长文本。解决办法之一是为模型配备一个递归记忆模块,然而,现有的方法是直接重用之前片段的隐藏状态,这些片段以单向的方式编码上下文。因此,这禁止了这些记忆与当前语境的动态互动,而当前语境为单词预测提供了最新的信息。
为了解决这个问题,我们提出了Look-Ahead Memory(LaMemo),它通过逐步关注右侧的单词和用旧的记忆状态进行插值来加强递归记忆,它同时使用当前的文本和历史的信息动态更新记忆单元,以保持历史中的长期信息,实现结构如下:
LaMemo包含了双向注意和片段递归,其额外的计算开销只与记忆长度成线性比例。我们在标准的语言模型benchmarks上进行了实验,证明了长文本生成的场景下,LaMemo相比其他具备不同类型记忆的baselines更有优势。下图是我们在Wikitext-103数据集上测试的结果,LaMemo相比其他方法达到了更低的ppl(perplexity)指标。

应用场景:
该方法可以应用在超长的故事及剧情生成中,并提升更广范围内文本内容的相关性和一致性。
网易伏羲成立于2017年,是国内专业从事游戏与泛娱乐AI研究和应用的顶尖机构,研究方向包括强化学习、图像动作、虚拟人、自然语言、用户画像、大数据和云计算平台等。
迄今为止,网易伏羲已经发表100多篇AI顶会论文,拥有200多项发明专利,以及数字人、智能捏脸、AI创作、AI反外挂、AI推荐匹配、AI竞技机器人等多个领域的领先技术。目前,网易伏羲正在向游戏、文娱等产业开放AI技术及产品,已服务超200家客户,应用日均调用量数亿次。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢