

论文:https://arxiv.org/abs/2204.08394
代码:https://github.com/Duankaiwen/PyCenterNet
导读
目前主流的目标检测算法多是anchor-based这一类,其中有two-stage也有one-stage。所谓的anchor其实是事先通过手工或聚类方法设定好的具有不同尺寸、宽高比的方框,这些方框覆盖了整张图像,目的是为了防止漏检。在模型训练过程中,根据anchor与ground truth的IoU(交并比)损失对anchor的长宽以及位置进行回归,使其越来越接近ground truth,在回归的同时预测anchor的类别,最终输出这些回归分类好的anchors。
由于FPN和Focal Loss的出现,有效解决了特征语义信息不足和正负样本不均衡的问题,又涌现出了一批anchor-free的算法。anchor-free检测器以两种不同的方式检测物体,一种是首先定位到多个预定义或自学习的关键点,然后约束物体的空间范围,称为Keypoint-based方法;另一种是利用中心点或中心目标区域来定义正样本,然后预测其到目标四个边的距离,称为Center-based方法。anchor-free的方法使得目标检测的流程进一步精简,减少了相关超参数,使得网络搭建训练更简便,泛化能力也更强。
这些算法又可以被概括为top-down和bottom-up两种,top-down就是先获取目标的大致边界,再进一步确定目标的位置,比如RepPoints,通过可变形卷积确定目标边界。bottom-up自底向上,图像提取到特征图后,网络先确定目标的边缘极值点或角点,再通过定义这些点是否属于同一个目标,得到目标的边界来确定检测目标,比如CornerNet(左上角点、右下角点)、ExtremeNet(上、下、左、右极值点+中心点)。
本文中,作者证明了bottom-up方法与top-down的方法具有同样的竞争能力。本文所提的方法名为CenterNet,它将每个目标检测为一个三元组关键点(左上角、右下角和中心关键点)。首先通过设计的线索对corner keypoints进行分组,然后通过center keypoints进一步确定目标。CenterNet是一种Anchor-free目标检测器,因为它不需要定义Anchor boxes。在MS-COCO数据集上,使用Res2Net-101和Swin-Transformer的CenterNet分别实现了53.7%和57.1%的ap,优于所有现有的bottom-up检测器,达到了最先进的水平。作者还设计了一个实时的CenterNet,它在30.5帧/秒的情况下达到了43.6%的AP,实现了精度和速度之间的良好平衡。
贡献
在当前时代,目标检测主要有两类:top-down的检测方法和bottom-up的检测方法。所有top-down的方法都将每个目标建模为一个先验点或预定义的Anchor boxes,然后预测到边界框的相应偏移量。top-down方法更多是将目标视为一个整体,这简化了生成边界框的后处理。然而,top-down方法通常难以感知特殊形状的物体(例如,物体的高宽比很大)。

另一方面,作者发现bottom-up的方法在定位任意几何形状的目标时可能更好,因此有更高的召回率。但是传统的bottom-up方法也会产生很多误检,不能准确地表示目标。以最具代表性的bottom-up方法之一CornerNet为例,它使用一对角关键点对每个目标进行建模,实现了最先进的目标检测精度。然而,由于对全局信息的表征能力相对较弱,CornerNet经常会生成不正确的边框,其中大部分都可以通过一些补充信息过滤掉,例如长宽比。
因此,作者认为:只要提高bottom-up方法感知目标全局信息的能力,bottom-up方法将可以达到与bottom-up方法一样具有竞争力。本文设计了2个框架来适应不同结构的网络,第一个框架适用于hourglass网络,它可以在单一分辨率的特征图上检测物体。作者还设计了适合pyramid-like网络的框架,在多分辨率特征图上检测目标,这带来了2个优势:
- 较强的通用性,大多数网络都可以适配金字塔结构,如ResNet及其变体;
- 不同尺度的目标在不同的感受野中被检测出较高的检测精度。
本文的主要贡献可以总结如下:
- 提出了一种强bottom-up的目标检测方法,命名为CenterNet。它将每个目标检测为一个三重关键点,具有对任意几何形状的目标进行定位和感知目标内部全局信息的能力。
- 设计了2个框架来适应不同结构的网络,具有更强的通用性,可以适用于几乎所有的网络。
- CenterNet在bottom-up方法中实现了最先进的检测精度,并与其他top-down方法的最先进性能相当。通过适当降低结构复杂度,CenterNet实现了精度与速度的良好平衡。
方法
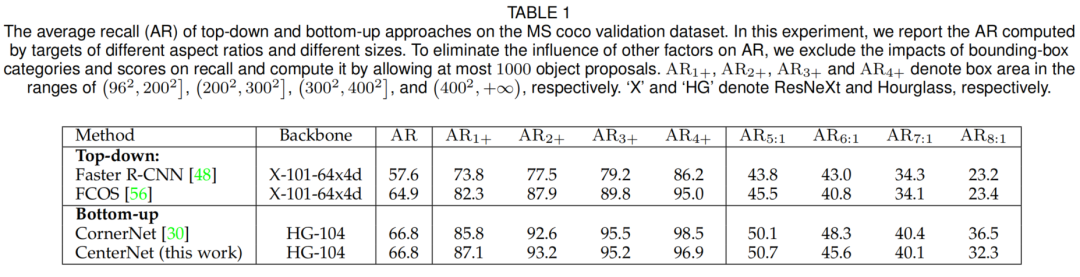
如表1所示,作者在MS-COCO验证数据集上对三种具有代表性的方法以及本文的工作进行了评估,Top-down方法的召回率明显低于Bottom-up方法,特别是对于具有特殊几何形状的对象。
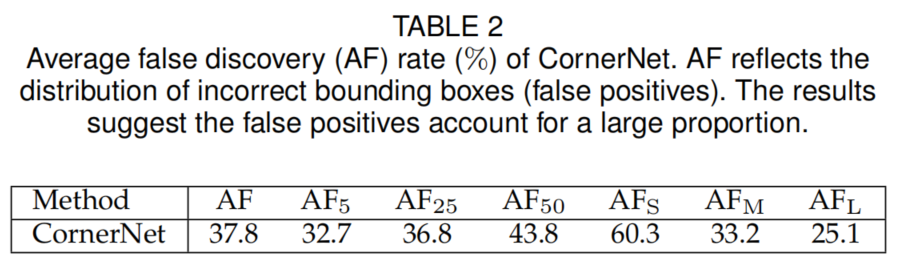
在表2中,作者对CornerNet进行了更深入的分析。计算了MS-COCO验证数据集上CornerNet的AF(average false discovery,AF=1−AP)。结果表明,即使在较低的IoU阈值下,错误的边界框也占很大比例,例如,在IoU=0.05时,CornerNet获得32.7%的AF。这意味着平均每100个物体预测框中有32.7个IoU低于0.05。小的不正确的边界框更多,达到60.3%的AF。其中一个可能的原因是,CornerNet无法查看边界框内的区域。
Object Detection as Keypoint Triplets
Single-resolution detection framework
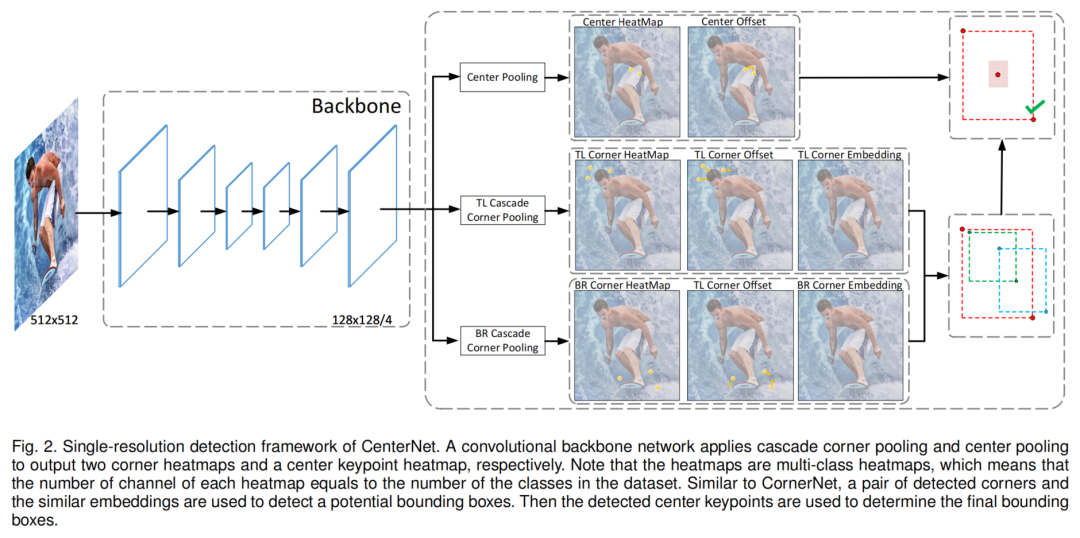
整个网络架构如图2所示。用一个corner keypoints和一对center keypoints来表示每个对象。在此基础上,嵌入了corner keypoints heatmap,并预测了corner keypoints的偏移量。然后,使用在CornerNet中提出的方法生成top-k边界框。但是,为了有效地过滤出不正确的边框,利用检测到的center keypoints,采用以下步骤:
- 据得分选取top-k的center keypoints;
- 利用相应的偏移量将这些center keypoints映射到输入图像;
- 为每个边框定义一个中心区域,并检查中心区域是否包含center keypoints。注意,选中的center keypoints的类标签应该与边框的类标签相同;
- 如果在中心区域检测到一个center keypoints,将保留边界框。边界框的得分将替换为左上角、右下角和center keypoints三个点的平均得分。如果在其中心区域没有检测到center keypoints,则边界框将被移除。
Multi-resolution detection framework
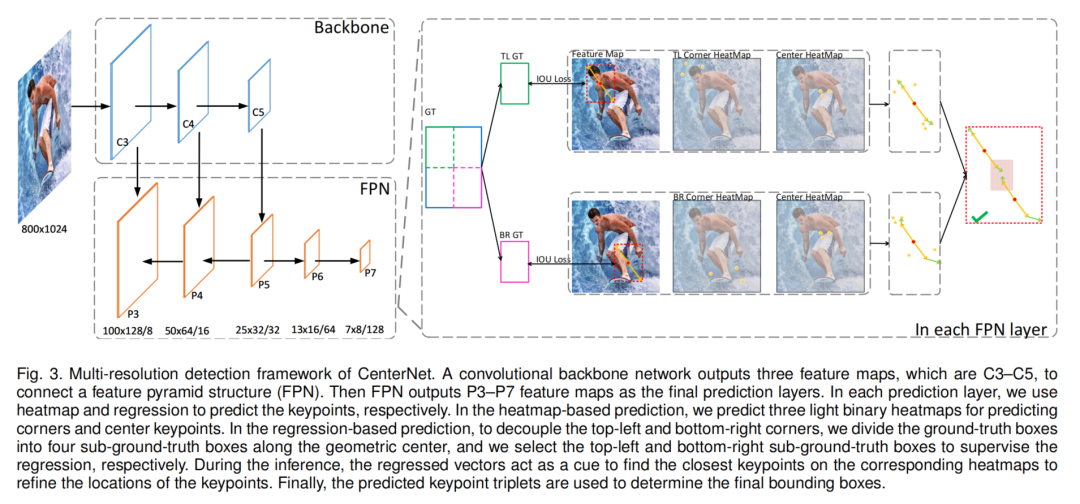
整个Multi-resolution检测框架如图3所示。它从一个Backbone(如ResNet,ResNeXt等)开始,从输入图像中提取特征。从Backbone中选择C3-C5特征映射作为特征金字塔结构(FPN)的输入。然后FPN输出P3-P7 feature map作为最终的预测层。
在每个预测层中,分别使用heatmap和回归来预测关键点。在基于heatmap的预测中,预测了3个光二元heatmap,用于预测corner keypoints和center keypoints。heatmap的分辨率与预测层相同,因此,为每个关键点预测一个额外的偏移量,以学习将关键点从heatmap映射到输入图像。
在基于回归的预测中,为了对左上角和右下角进行解耦,将GT框沿几何中心划分为4个GT框,并分别选取左上角和右下角的GT框来监督回归。以左上角框的回归为例,在左上角次GT框中选择了一些特征点,每个选择的特征点预测2个向量,分别指向顶部corner keypoints和center keypoints。
最后,为每个边界框定义一个中心区域,并检查该中心区域是否包含2个预测的center keypoints。如果在其中心区域最多检测到一个中心关键点,则边界框将被移除,边界框得分将被替换为各得分的平均值(即上角、右下角和center keypoints得分)。
提高center和corner的信息
center keypoints和corner都与目标有严格的几何关系,但包含有限的对象的视觉模式。这里以一种完全监督的方式训练网络来学习几何关系和有限的视觉特征,从而定位关键点。如果为center keypoints和corner引入更多的视觉模式,它们将能够被更好地检测出来。
Center pooling
物体的几何中心并不总是传达非常容易识别的视觉模式(例如,人的头部包含强烈的视觉模式,但中心重点往往是在人体的中间)。为了解决这个问题,作者提出Center pooling来捕捉更丰富、更容易识别的视觉模式。
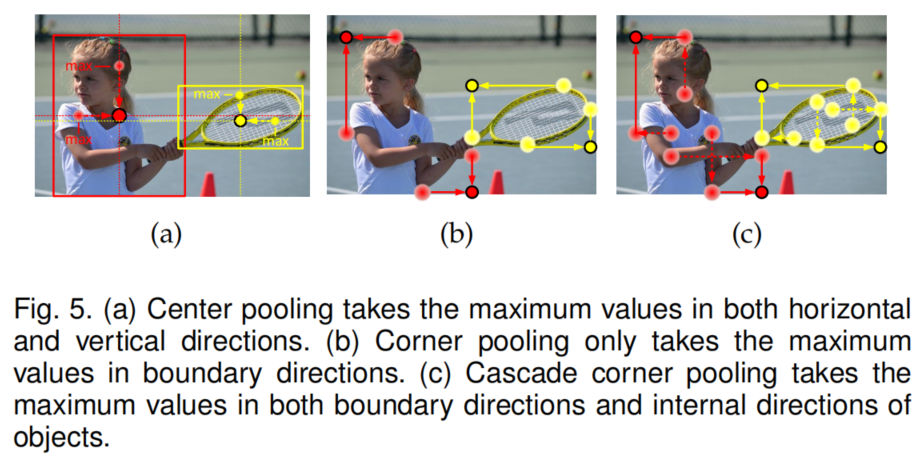
Cascade corner pooling
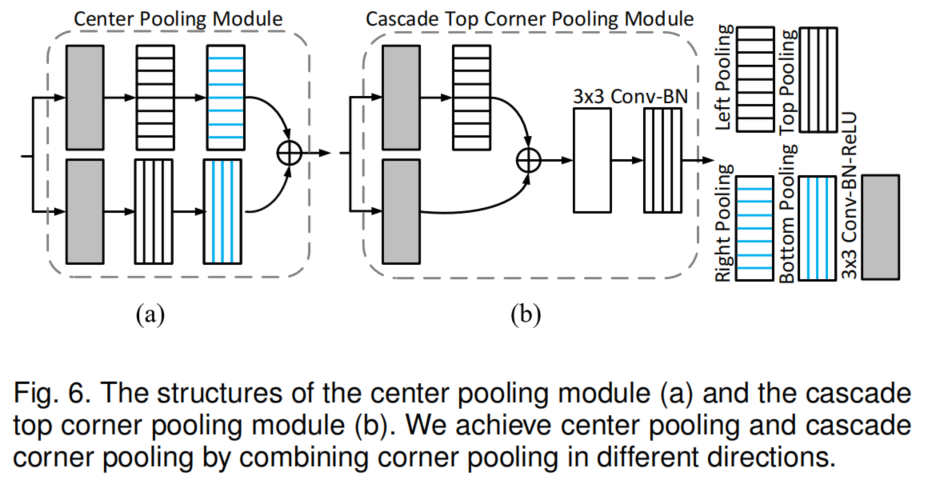
图6(a)显示了Center pooling模块的结构。要在特定的方向(如水平方向)取最大值,只需要依次连接左、右池化即可。图6(b)显示了Cascade corner pooling模块的结构,其中白色矩形表示3×3卷积之后是批归一化。与CornerNet的Corner pooling相比,在top-corner池化之前增加了一个left-corner池化。
实验
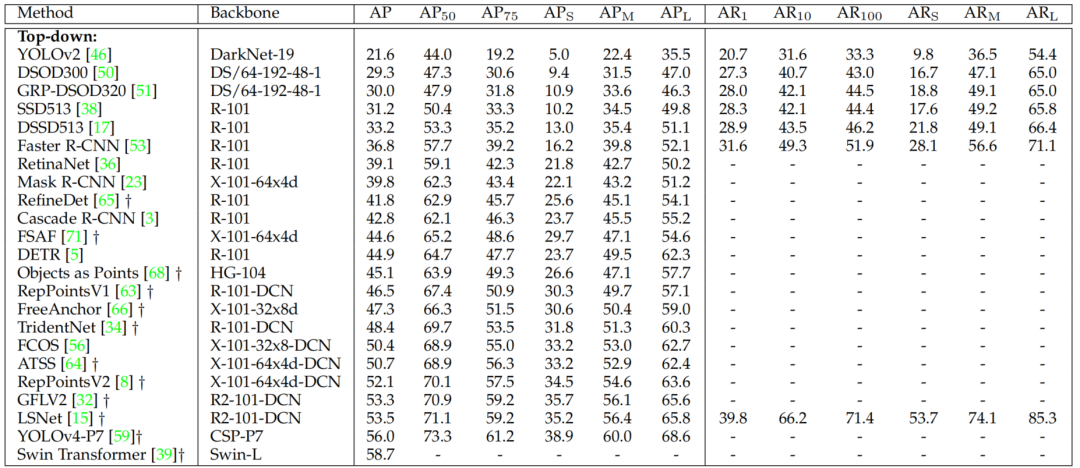
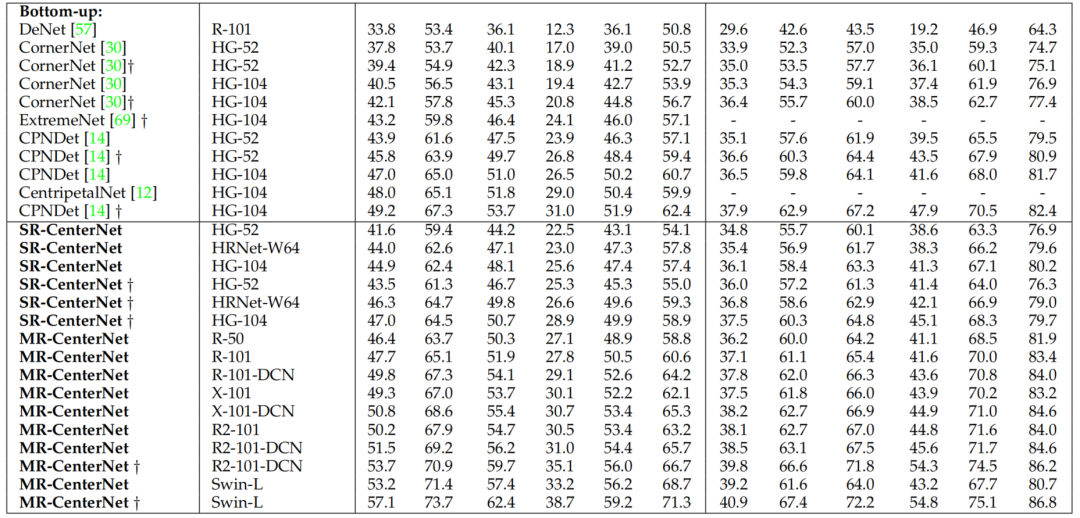
如表3所示,本文提出的MR-CenterNet进一步提高了目标检测精度。例如,在相同的网络深度(Hourglass-52 vs. ResNet-50)下,MR-CenterNet将目标的AP提高了4.8%。由于MR-CenterNet框架的通用性强,能够为CenterNet应用更强的Backbone。
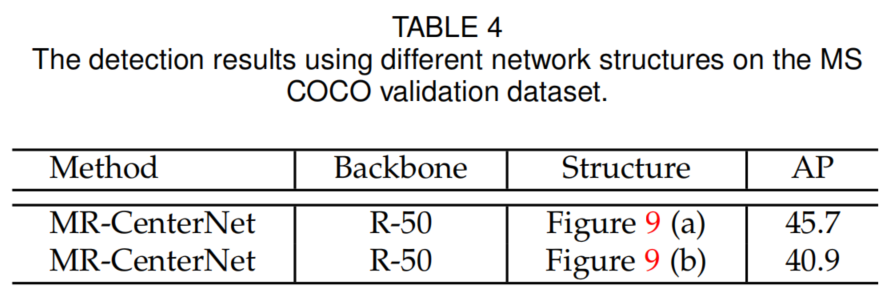
表4显示了在MS COCO验证数据集上的检测结果,MR-CenterNet具有多分辨率检测层,准确率更高。这是因为多分辨率检测结构为检测不同尺度的目标提供了更丰富的感受野,有助于提高检测精度。
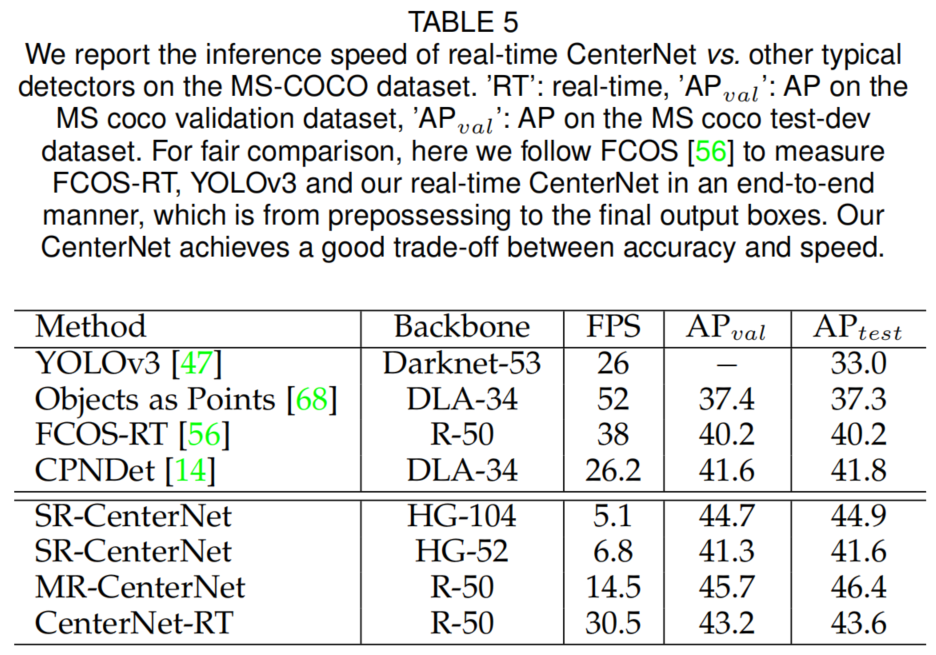
如表5所示。CenterNet-RT实现了精度和速度之间的良好平衡,在其他典型方法中仍然具有竞争力。CenterNet(即SR-CenterNet)执行速度较慢,推断速度小于7fps。本文采用金字塔结构的CenterNet对目标进行多分辨率特征层检测,提高了检测速度和精度。
参考资料
- https://blog.csdn.net/qq_44442727/article/details/114692401
- https://zhuanlan.zhihu.com/p/139476476
- https://mp.weixin.qq.com/s/1l6HvcXfEgsGsUMBNEMllA
- https://www.sohu.com/a/364671359_100007727
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢