
【论文标题】Multi-label topic classification for COVID-19 literature with Bioformer
【作者团队】Li Fang, Kai Wang
【发表时间】2022/04/14
【机 构】宾夕法尼亚大学
【论文链接】https://arxiv.org/pdf/2204.06758v1.pdf
【代码链接】https://github.com/WGLab/bioformer/
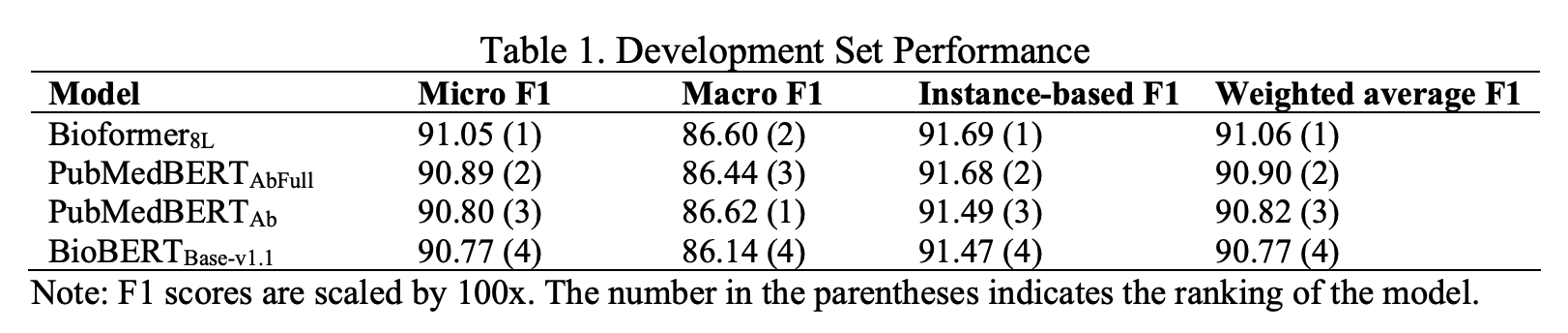
本文描述了Bioformer团队参与COVID-19文献的多标签主题分类任务(BioCreative VII的第5赛道)。主题分类是使用不同的BERT模型,即BioBERT、PubMedBERT和Bioformer进行的,本文将主题分类任务表述为一个句对分类问题,其中标题是第一句,摘要是第二句。本文的结果表明,Bioformer在这项任务中的表现优于BioBERT和PubMedBERT。与基线结果相比,本文方法的最佳模型将微观、宏观和基于实例的F1得分分别提高了8.8%、15.5%和7.4%。Bioformer在这次挑战中取得了最高的微观F1和宏观F1得分。在挑战赛后的实验中,本文发现Bioformer对COVID-19文章的预训练进一步提高了性能。
模型
本文使用BioBERT、PubMedBERT和Bioformer来进行多标签主题分类。对于BioBERT,本文使用BioBERTBase-v1.1,这是出版物中描述的版本。PubMedBERT有两个版本:一个版本是对PubMed摘要的预训练(在本研究中用PubMedBERTAb表示),另一个版本是对PubMed摘要加PMC全文的预训练(用PubMedBERTAbFull表示)。本文使用Bioformer8L,这是一个具有8个隐藏层的紧凑型生物医学BERT模型。Bioformer8L在PubMed摘要和100万PMC全文文章上进行了200万步的预训练。
主题分类任务
本文将主题分类任务表述为一个句对分类问题,其中标题是第一句,摘要是第二句。输入被表示为"[CLS]标题[SEP]摘要[SEP]"。最后一层中[CLS]标记的表示被用来进行关系分类。本文利用transformers python库中的句子分类器对模型进行了微调。本文对每个主题进行独立处理,并对七个不同的模型进行微调(每个主题一个)。本文在训练数据集上对每个BERT模型进行了3次微调。最大的输入序列长度被固定为512。选择了16个批次的大小,并选择了3e-5的学习率。
在COVID-19文章上进一步预训练Bioformer
本文从LitCovid网站下载了164,179篇COVID-19文章的摘要,摘要的总大小为164MB。预训练是在Google Colab上进行的,采用TPU(v2-8)加速。最大输入长度被固定为512,批处理大小被设置为256。学习率被设置为2e-5。本文在这个数据集上对Bioformer进行了100个epochs的预训练,其中每个epoch都有不同的随机屏蔽位置。优化步骤的数量约为80k。预训练在8小时内完成。本文把这个模型命名为BioformerLitCovid。
总结
首先,BioBERT和PubMedBERT是在COVID-19爆发之前发布的,因此COVID-19研究没有包括在这两个模型的预训练语料中。Bioformer在2021年2月进行了预训练,其预训练语料库包含了2021年2月之前发表的95,185项COVID-19研究(占总语料库的0.3%)。这一事实可能部分解释了为什么Bioformer在参数数量较少的情况下取得了更好的性能。
其次,Bioformer进行了200万步的预训练,其数量是BioBERT的两倍,额外的训练也可能有助于提高性能。
总之,本文的研究表明,一个轻量级的模型Bioformer可以在COVID-19文章的主题分类中取得令人满意的表现。本文希望本文的研究能促进COVID-19文章以外的科学文献的自动主题分类任务。
创新点
在本文中,本文介绍了Bioformer团队在LitCovid多标签主题分类赛道中的方法。本文的结果显示,Bioformer在这项任务中的表现优于其他两个BERT模型。与基线方法相比,本文的最佳模型提供了明显的性能增益。在挑战赛后的实验中,本文表明Bioformer在COVID-19文章上的进一步预训练提高了所有三个指标(微观F1、宏观F1和基于实例的F1)的性能,表明更具体的语料库的有益影响。本文还尝试了单句分类方法,但这并没有提高性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢