
无监督计算机视觉的最新技术——麻省理工学院 CSAIL 科学家创建了一种算法来解决计算机视觉中最困难的任务之一:为世界上的每个像素分配一个标签,无需人工监督。

标记数据可能是一件麻烦事。它是计算机视觉模型的主要来源;没有它,他们就很难识别物体、人以及其他重要的图像特征。然而,仅仅制作一个小时的标记数据就可能需要人类800小时的时间。随着机器能够更好地感知周围环境并与之互动,我们对世界的高保真理解也在不断发展。但是他们需要更多的帮助。
麻省理工学院计算机科学与人工智能实验室(CSAIL)、微软(Microsoft)和康奈尔大学(Cornell University)的科学家们试图通过创建“STEGO”来解决这个困扰视觉模型的问题。“STEGO”是一种算法,可以在没有任何人类标签的情况下,联合发现和分割物体,直到像素。
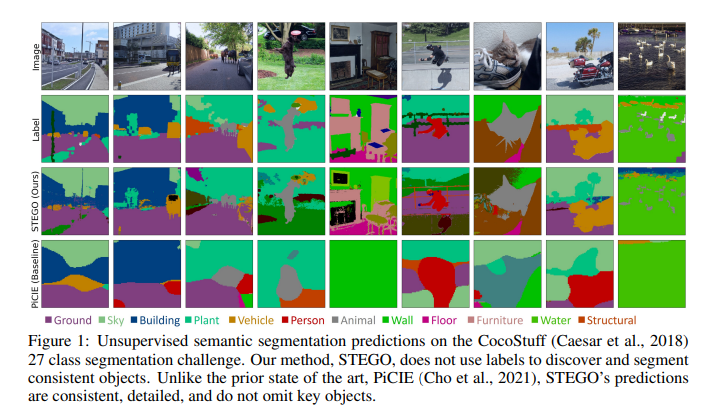
STEGO 学习了一种叫做“语义分割”的技术——为图像中的每个像素分配标签。语义分割是当今计算机视觉系统的一项重要技能,因为图像可能会被物体弄得杂乱无章。更具挑战性的是这些对象并不总是适合文字框。相对于植被、天空和土豆泥等“东西”,算法往往更适用于人和汽车等离散的“事物”。以前的系统可能只是将狗在公园里玩耍的微妙场景仅仅视为一只狗,但通过为图像的每个像素分配一个标签,STEGO 可以将图像分解为:狗、天空、草和它的主人。
为世界上的每一个像素分配一个标签是令人振奋的——尤其是在没有任何人类反馈的情况下。今天的大多数算法都从大量标记数据中获取知识,而这些数据可能需要花费大量的人力来获取。想象一下标记 100,000 张图像的每个像素的兴奋!为了在没有人类帮助的情况下发现这些对象,STEGO 会寻找出现在整个数据集中的相似对象。然后,它将这些相似的对象关联在一起,以在它学习的所有图像中构建一致的世界视图。

论文链接:https://arxiv.org/pdf/2203.08414.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢