
本文对应学术论文收录于 AAAI 2022,地址: https://arxiv.org/abs/2109.11496,现已开源: https://github.com/megvii-research/LGD。如果认为学术论文对您的 research 或工程有帮助,欢迎引用和 star repo。
原作者曾在旷视研究院公众号上发布过对本文的速看,本文是原作者对文章更深入(罗嗦)的解读版本。图片部分有点糊,建议下载 paper的来看。
传统的检测蒸馏方法依赖于强的预训练teacher,然而在实际生产当中,要么对给定student,其合适强预训练teacher 不好获取。要么,有时候我们是有一个给定的锤子(teacher),对某种钉子(设计好某种 architecture 满足某种吞吐量的student)可能并不好用,因需要顾虑被蒸馏的学生网络和教师异构的问题,更不必说需要使用NAS搜索合适teacher的那种场景了。总之,大家经常忽略寻找预训练教师所需要的时间以及大教师网络本身的训练周期,只是兀自地只关心蒸馏是 deploy 时 cost-free的就没有然后了。不聊这个,其实知识蒸馏可以认为是从教师网络身上获取具有指导性的知识(logits也好,feature map也好,relation 都可以),而后的蒸馏损失就是惩罚它们知识的encoding 之间的距离。本文,我们绕开预训练teacher,构造出一种具备指导性的知识,只需要使用到常规的 student 检测器特征 以及常规的训练 ground-truth 。这是首个用于通用目标检测的自蒸馏方法,我们称其为标签引导自蒸馏 (Label-Guided Self-Distillation)。
我们的方法本质是一种鲜有人做的显式 label representation learning ([1], [2], etc.) 或者说 label encoding 系列工作中的一个(它也不应当局限于蒸馏这个scope,只是说蒸馏尤其是重要的下游任务 -- detection 的蒸馏可能会是它一个很 practical 的应用,为了验证其实效性,我们在此任务上进行)。在检测的 literature 里,离散的one-hot label 以及 连续的 encoded offset 就是 Naive 的 指导性知识。但是这种信号太末端,受启发于 deeply supervised 方法 [3] 等更良好的中间监督方式,ECCV 2020 的 LabelEnc [2] 方法构造了一种有指导性的中间特征图形式的知识。他们基于检测的 literature,adhoc 地构造了一种 auto-encoder-like的结构:[输入 label 的色块张量形式 -> backbone -> fpn -> head -> 预测 label]。重构的损失即检测损失,label assignment 和寻常无异。感兴趣的读者可以去读读这篇文章。这种方法虽然优雅,但是我们发现随着检测 setting 的增强 (训练时长,student backbone,+ multi-scale training),LabelEnc 带来的涨点会饱和于 baseline。如下是在三种经典检测器上的消融实验:
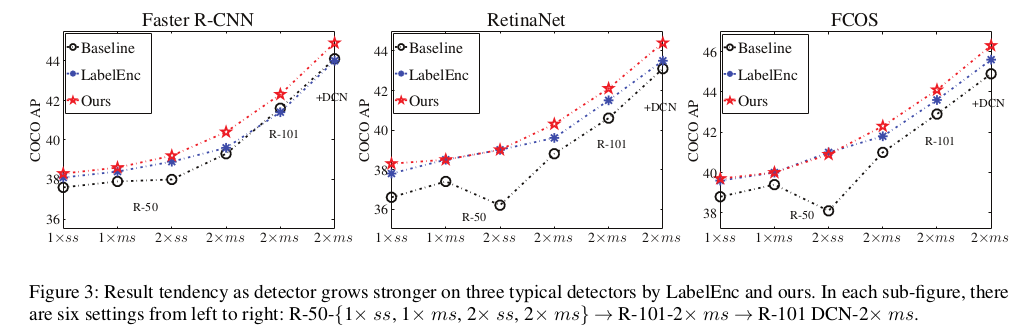
我们推测原因可能有二:(1) LabelEnc 的构造性任务里色块图的涂色形式是逐个物体逐个物体考虑的,没有考虑物体之间的高阶关系如 relationship 这种信息 (后来 [4] relation network 系列工作说明了这种信号的有效性)。这可能使得更强的训练setting 下,student 模型通过末端的ground-truth 监督(分类和回归损失),就已经可以吃掉 LabelEnc 中间监督 想做的逐物体信息监督增益了。(2) LabelEnc 方法显式揭示了输入模态 (RGB) 和 label 之间的异构性(这个不好理解是因为我们从没有把 label 本身当成一种特殊的模态来看),毕竟它常常只是在计算图的末端充当一个detached 节点。 本文旨在缓解这两个问题的同时,又兼顾了框架的端到端训练性质(LabelEnc 本身是两阶段的,需要先 pretrain AE-like结构,然后用encoding来蒸馏)以及更 time/memory-efficient 的设计。下图为框架图:
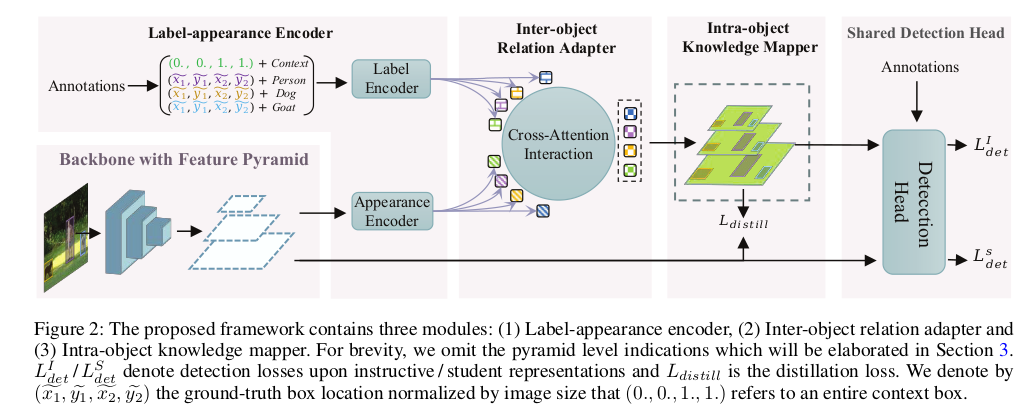
见图而明,我们的框架由 (1) 编码器模块: Label Encoder, Appearance Encoder (2) 跨物体,跨模态的交叉注意力模块 (3) 逐物体的知识映射模块 所组成。
编码器模块旨在高效的获取物体本身两种模态的1-D 嵌入,Label Encoder 是把 4+|C| 维的 descriptor 用MLP (实际使用的PointNet) 投影成 256 D 的特征条 (label embeddings)。Appearance Encoder 是将物体在原图坐标系下的框按stride 映射到每一个 pyramid feature map上,通过 bounding box 区域的二值 mask pooling 也获得 256 D 的特征条 (appearance embeddings)。
然后以 label embeddings 为 query,appearance embeddings 为 key 和 value 作 cross-attention,结果即获得 每种 pyramid 尺度的 1D attention outputs,它的好处:a. 线性组合出这些 attention outputs 的 basis 是 qkv 中的 value 即 appearance embeddings (label 参与的是 aggregation 的KQ系数计算),后续若进行和同来源于 RGB 的 student 特征图监督的话,可认为是同模态了,即缓解模态 gap。 b. 低维交互,高效计算,显存消耗低。
后续使用映射模块将 1D 的交互特征按框prior 映射回 特征图空间,并参与后续检测损失的计算,同时亦有对 student 金字塔特征图的监督损失。(当然实验上为了先让这种指导性特征图靠谱些,会先不开蒸馏损失,过数万个iters后才开,不赘述)。
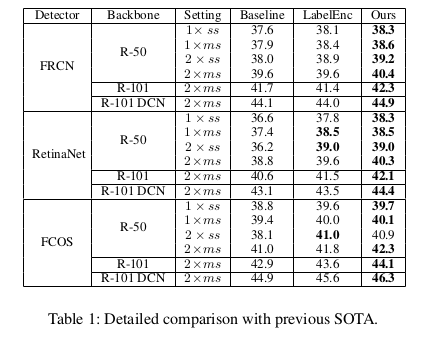
实验上对比公平,在 2xMS (最常用的3xMS 实验见 Appendix) 的 settings 上比领域 SOTA LabelEnc 方法表现要好:
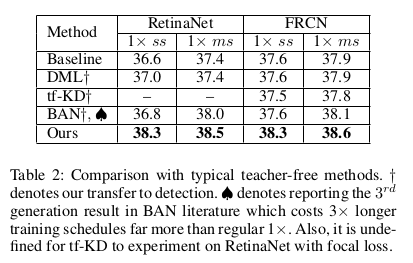
也和分类的自蒸馏方法强行实现在检测任务上进行了比较,性价比无疑是更好的:
和最经典的 teacher-based 的方法 FGFI 比较 (和带teacher setting 比本身不公平),也发现一些有趣的地方,我们的方法在 student 变强后(不少蒸馏论文并没有考虑到这种情况),也能继续涨点,而带 teacher的检测蒸馏通常是需要你的teacher 也跟着变强后才能涨的,这个没有 proof,但 ICLR的 FBKD [5] 有很多 empirical study 。
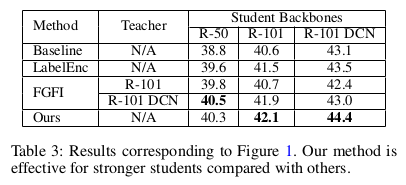
剩下就是一些 ablation study 去说明各模块间的自洽了。
我们除了 R-50, R-101, R-101 DCN v2 的 student backbone settings 还尝试了更强的 X-101 DCN v2 以及 Swin-Tiny 设置,充分说明方法的有效性:

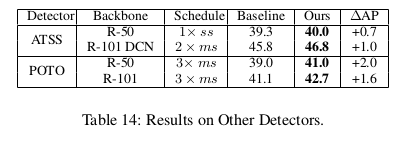
在别的检测器上:
[1] Regularizing Deep Networks by Modeling and Predicting Label Structure. Mostajabi et al. CVPR 2018
[2] LabelEnc: A New Intermediate Supervision Method for Object Detection. Hao et al. ECCV 2020
[3] Deeply-supervised Nets. Lee et al. Lee et al. AISTATS 2014
[4] Relation Networks for Object Detection. Hu et al. CVPR 2018
[5] Improve Object Detection with Feature-based Knowledge Distillation: Towards Accurate and Efficient Detectors. Zhang et al. ICLR 2021
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢